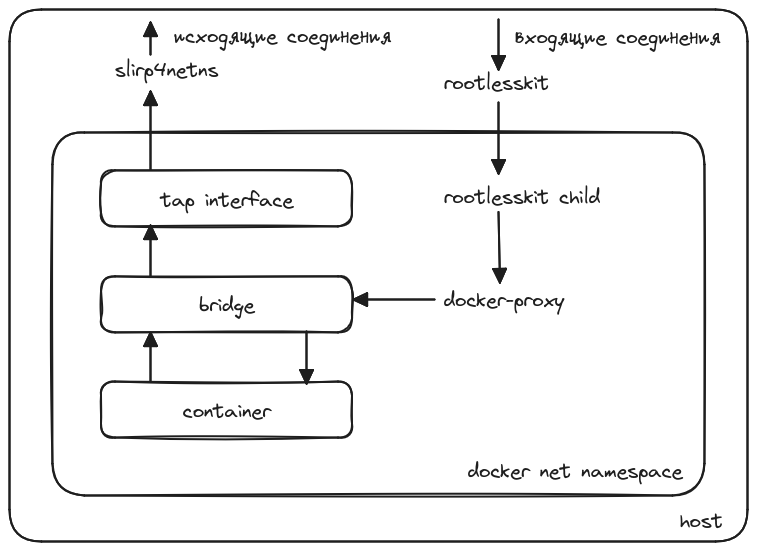
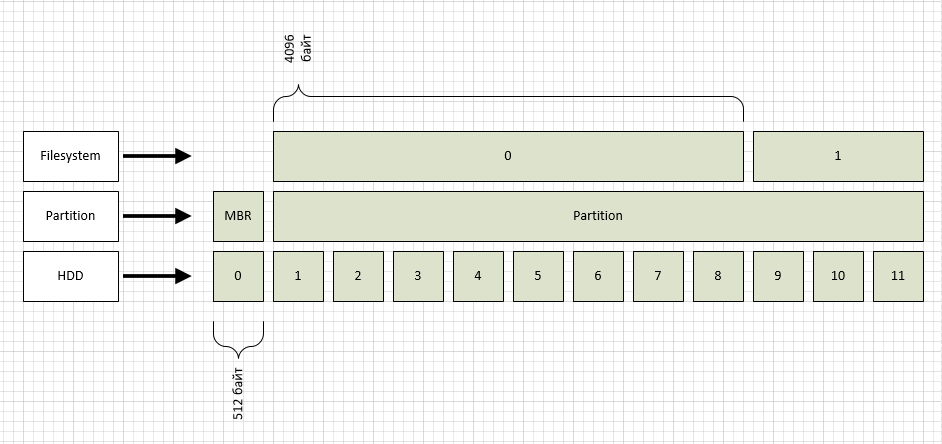
Понимание того как Kubernetes обрабатывает контейнеры дает большую гибкость при создании пользовательских конфигураций под конкретные нужды.
Kubernetes позволяет выполнять много полезной работы без глубокого понимания деталей. Утилита командной строки kubectl и дашборды в Openshift помогают управлять вашими контейнерами. Однако, как только вы заглянете глубже в Kubernetes все может быстро усложниться.
Тем не менее, понимание того, как основные части взаимодействуют друг с другом, является важным для главного архитектора, который использует Kubernetes в своих проектах. Проведем аналогию с обычным архитектором: для проектирования небоскребов важно знать прочность на растяжение железобетона в сравнении с балками из чистой стали. Также полезно понимать как работают системы отопления, вентиляции и кондиционирования воздуха.
Такая аналогия правдива и для работы с Kubernetes. Просто сказать: "Давайте оставим это на усмотрение разработчиков" - недостаточно, с таким же успехом можно предоставить выбор системы кондиционирования обычным рабочим со строительной площадки. За каждой хорошо спроектированной системой стоит как множество деталей, так и архитектор, который понимает их значение.
Для системного архитектора в IT важно понимать как Kubernetes создает и запускает контейнеры. Изучение контейнерной оркестрации необходимо по двум причинам. Во-первых, это хорошее знание для архитектора уровня компании (как для обычного архитектора знание систем кондиционирования). Во-вторых, понимание механизмов, благодаря которым Kubernetes создает и запускает контейнеры, позволяет настраивать пользовательские конфигурации кластеров Kubernetes для специфичных кейсов, но для этого необходимо понимать основы.