- Научная статья
- Pytorch: YOLOv4-CSP, YOLOv4-P5, YOLOv4-P6, YOLOv4-P7 (main repository — use to reproduce results)
YOLOv4-CSP
YOLOv4-tiny
YOLOv4-large
- Darknet: YOLOv4-tiny, YOLOv4-CSP, YOLOv4x-MISH
- Структура YOLOv4-CSP
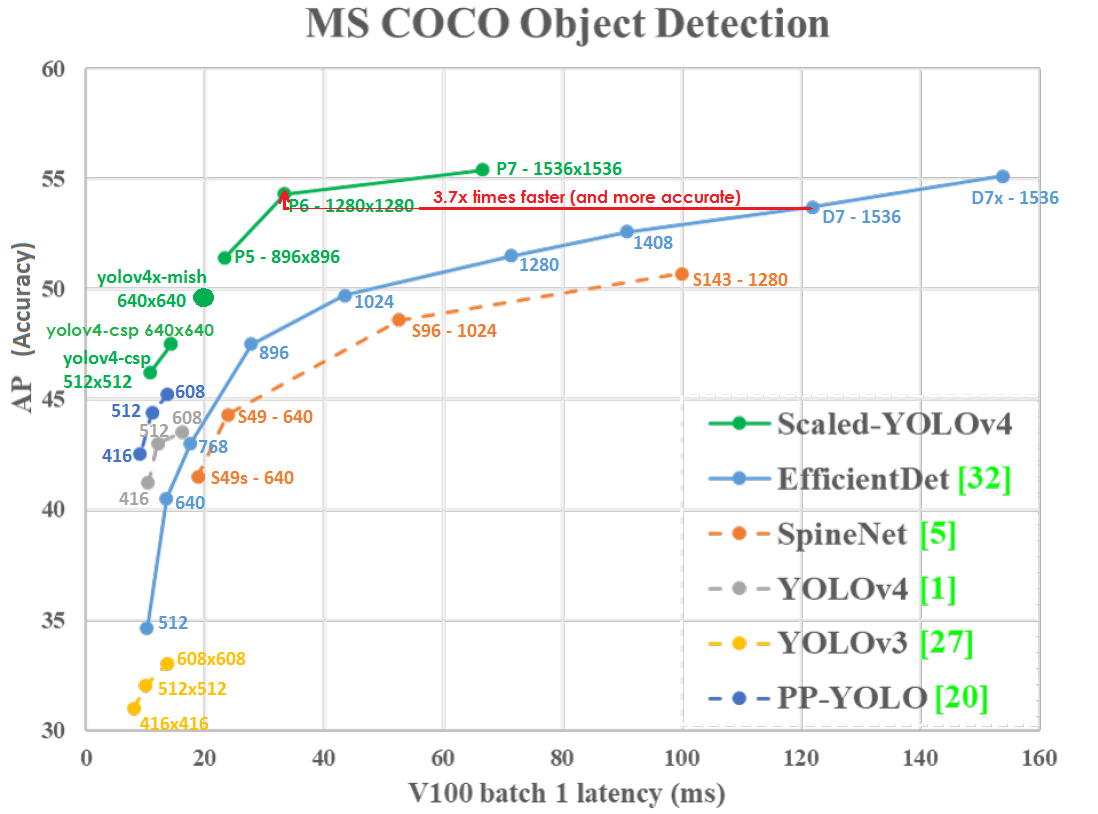
Scaled YOLO v4 является самой лучшей нейронной сетью для обнаружения объектов — самой точной нейронной сетью (55.8% AP) на датасете Microsoft COCO среди всех опубликованных нейронных сетей на данный момент. А также является лучшей с точки зрения соотношения скорости к точности во всем диапазоне точности и скорости от 15 FPS до 1774 FPS. На данный момент это Top1 нейронная сеть для обнаружения объектов.
Scaled YOLO v4 обгоняет по точности нейронные сети:
- Google EfficientDet D7x / DetectoRS or SpineNet-190 (self-trained on extra-data)
- Amazon Cascade-RCNN ResNest200
- Microsoft RepPoints v2
- Facebook RetinaNet SpineNet-190
Мы показываем, что подходы YOLO и Cross-Stage-Partial (CSP) Network являются лучшими с точки зрения, как абсолютной точности, так и соотношения точности к скорости.
График Точности (вертикальная ось) и Задержки (горизонтальная ось) на GPU Tesla V100 (Volta) при batch=1 без использования TensorRT: