Знакомство с гео-библиотекой S2 от Google и примеры использования
15 мин
Привет, Хабр!
Меня зовут Марко, я работаю в Badoo в команде «Платформа». Не так давно на GopherCon Russia 2018 я рассказывал, как работать с координатами. Для тех, кто не любит смотреть видео (и всех интересующихся, конечно), публикую текстовый вариант своего доклада.
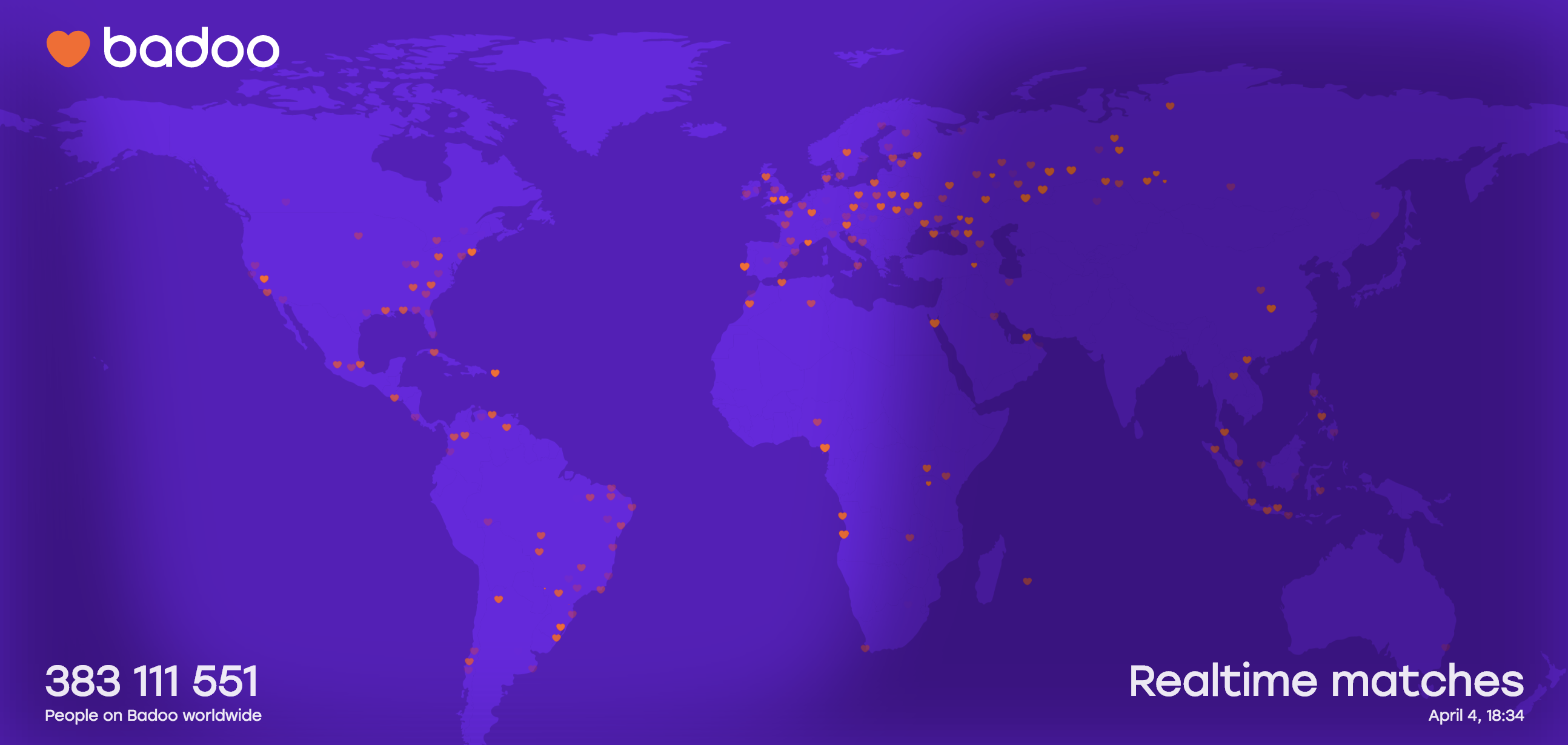
Сейчас у большинства людей в мире есть смартфон с постоянным доступом в Интернет. Если говорить в цифрах, то в 2018 году смартфон будет у почти 5 млрд людей, и 60% из них пользуются мобильным Интернетом.
Это огромные числа. Компаниям получать координаты пользователей стало легко и просто. Эти лёгкость и доступность породили (и продолжают порождать) огромное количество сервисов, основанных на координатах.
Всем нам известны компании типа Uber, игры, покорившие мир, такие как Ingress и Pokemon Go. Да что уж там, в любом банковском приложении есть возможность увидеть банкоматы или скидки поблизости.
Мы в Badoo также очень активно используем координаты, чтобы предоставлять своим пользователям лучший, актуальный и интересный для них сервис. Но о каком именно использовании идёт речь? Давайте посмотрим на примеры сервисов, которые у нас есть.
Меня зовут Марко, я работаю в Badoo в команде «Платформа». Не так давно на GopherCon Russia 2018 я рассказывал, как работать с координатами. Для тех, кто не любит смотреть видео (и всех интересующихся, конечно), публикую текстовый вариант своего доклада.
Введение
Сейчас у большинства людей в мире есть смартфон с постоянным доступом в Интернет. Если говорить в цифрах, то в 2018 году смартфон будет у почти 5 млрд людей, и 60% из них пользуются мобильным Интернетом.
Это огромные числа. Компаниям получать координаты пользователей стало легко и просто. Эти лёгкость и доступность породили (и продолжают порождать) огромное количество сервисов, основанных на координатах.
Всем нам известны компании типа Uber, игры, покорившие мир, такие как Ingress и Pokemon Go. Да что уж там, в любом банковском приложении есть возможность увидеть банкоматы или скидки поблизости.
Мы в Badoo также очень активно используем координаты, чтобы предоставлять своим пользователям лучший, актуальный и интересный для них сервис. Но о каком именно использовании идёт речь? Давайте посмотрим на примеры сервисов, которые у нас есть.