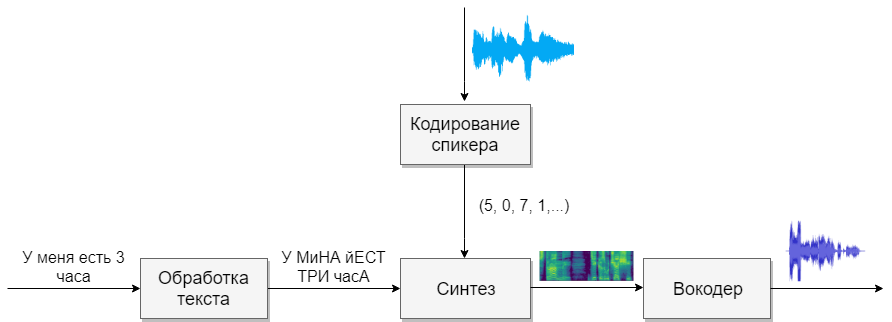
Синтез речи на сегодняшний день применяется в самых разных областях. Это и голосовые ассистенты, и IVR-системы, и умные дома, и еще много чего. Сама по себе задача, на мой вкус, очень наглядная и понятная: написанный текст должен произноситься так, как это бы сделал человек.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
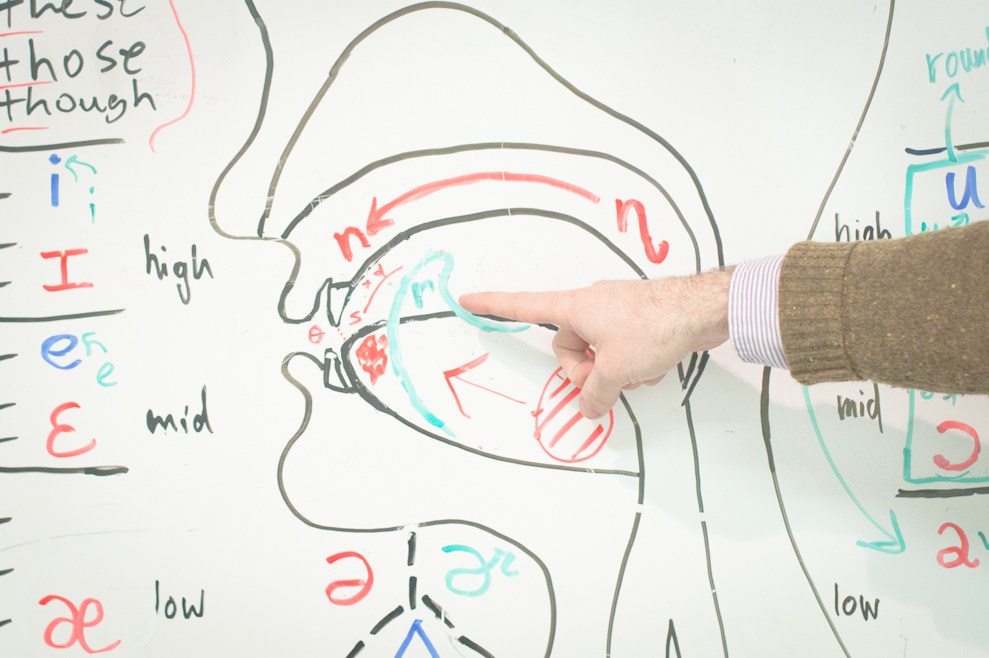
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.
Некоторое время назад в область синтеза речи, как и во многие другие области, пришло машинное обучение. Выяснилось, что целый ряд компонентов всей системы можно заменить на нейронные сети, что позволит не просто приблизиться по качеству к существующим алгоритмам, а даже значительно их превзойти.
Я решил попробовать сделать полностью нейросетевой синтез своими руками, а заодно и поделиться с сообществом своим опытом. Что из этого получилось, можно узнать, заглянув под кат.