
Поднимаем собственный торрент-трекер на Centos
4 мин
Зачем нужен собственный торрент-трекер – вопрос не стоит. Причины могут быть разные. Поэтому сразу перейду к делу.
Вероятно, все крупные трекеры пишутся на заказ, либо индивидуально «допиливаются» известные движки. Когда стоит цель поднять собственный, например локальный трекер, чаще всего требования к нему не будут очень уж высокими, и остаётся выбрать нужный вариант из всех доступных, с перспективой на развитие.
Примерно так думал я, рассматривая и оценивая каждого кандидата. Свой выбор я остановил на TorrentPier II. Оценивая плюсы и минусы следует отметить привычный для пользователей интерфейс, схожий с небезыствестным Rutracker-ом, и техническую поддержку, пусть и в виде форума. Трекер, после небольшой настройки, без проблем работает у меня уже более года.
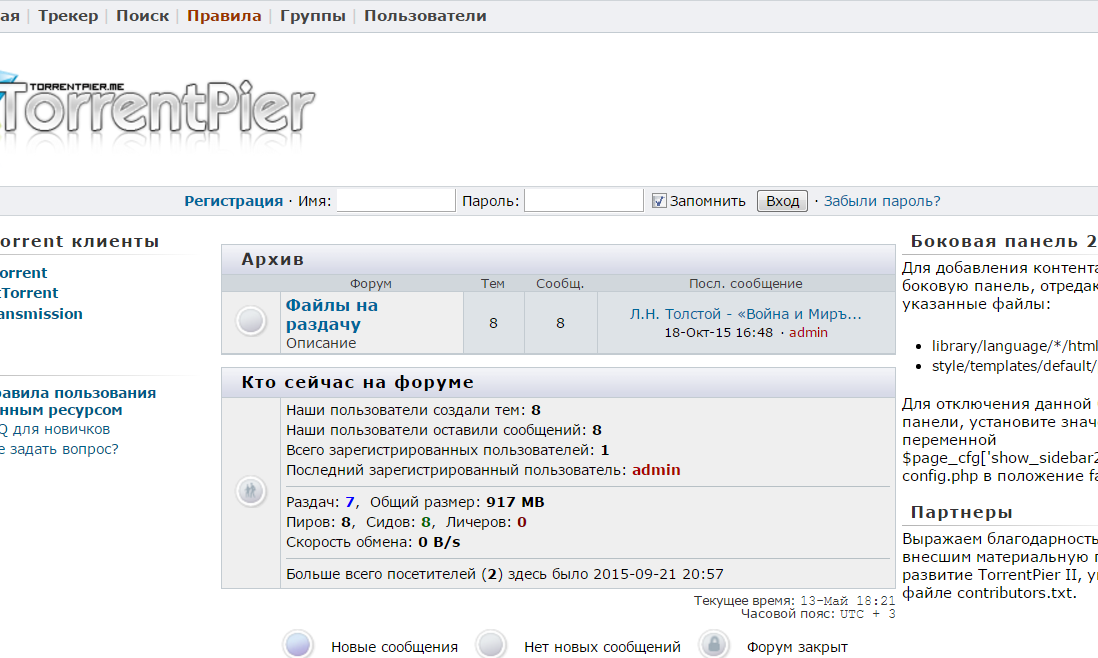
Установка выглядит следующим образом (небольшая цитата из инструкции):
Вероятно, все крупные трекеры пишутся на заказ, либо индивидуально «допиливаются» известные движки. Когда стоит цель поднять собственный, например локальный трекер, чаще всего требования к нему не будут очень уж высокими, и остаётся выбрать нужный вариант из всех доступных, с перспективой на развитие.
Примерно так думал я, рассматривая и оценивая каждого кандидата. Свой выбор я остановил на TorrentPier II. Оценивая плюсы и минусы следует отметить привычный для пользователей интерфейс, схожий с небезыствестным Rutracker-ом, и техническую поддержку, пусть и в виде форума. Трекер, после небольшой настройки, без проблем работает у меня уже более года.
Установка выглядит следующим образом (небольшая цитата из инструкции):

 Книга
Книга 








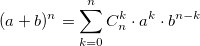 также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы:
также использует биномиальные коэффициенты. Для их расчета можно использовать формулу, выражающую биномиальный коэффициент через факториалы: 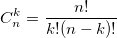 или использовать рекуррентную формулу:
или использовать рекуррентную формулу: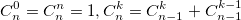 Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.
Из бинома Ньютона и рекуррентной формулы ясно, что биномиальные коэффициенты — целые числа. На данном примере хотелось показать, что даже при решении несложной задачи можно наступить на грабли.

