
Борьба с утечками памяти в веб-приложениях
13 мин
Перевод
Когда мы перешли от разработки веб-сайтов, страницы которых формируются на сервере, к созданию одностраничных веб-приложений, которые рендерятся на клиенте, мы приняли определённые правила игры. Одно из них — аккуратное обращение с ресурсами на устройстве пользователя. Это значит — не блокировать главный поток, не «раскручивать» вентилятор ноутбука, не сажать батарею телефона. Мы обменяли улучшение интерактивности веб-проектов, и то, что их поведение стало больше похоже на поведение обычных приложений, на новый класс проблем, которых не существовало в мире серверного рендеринга.

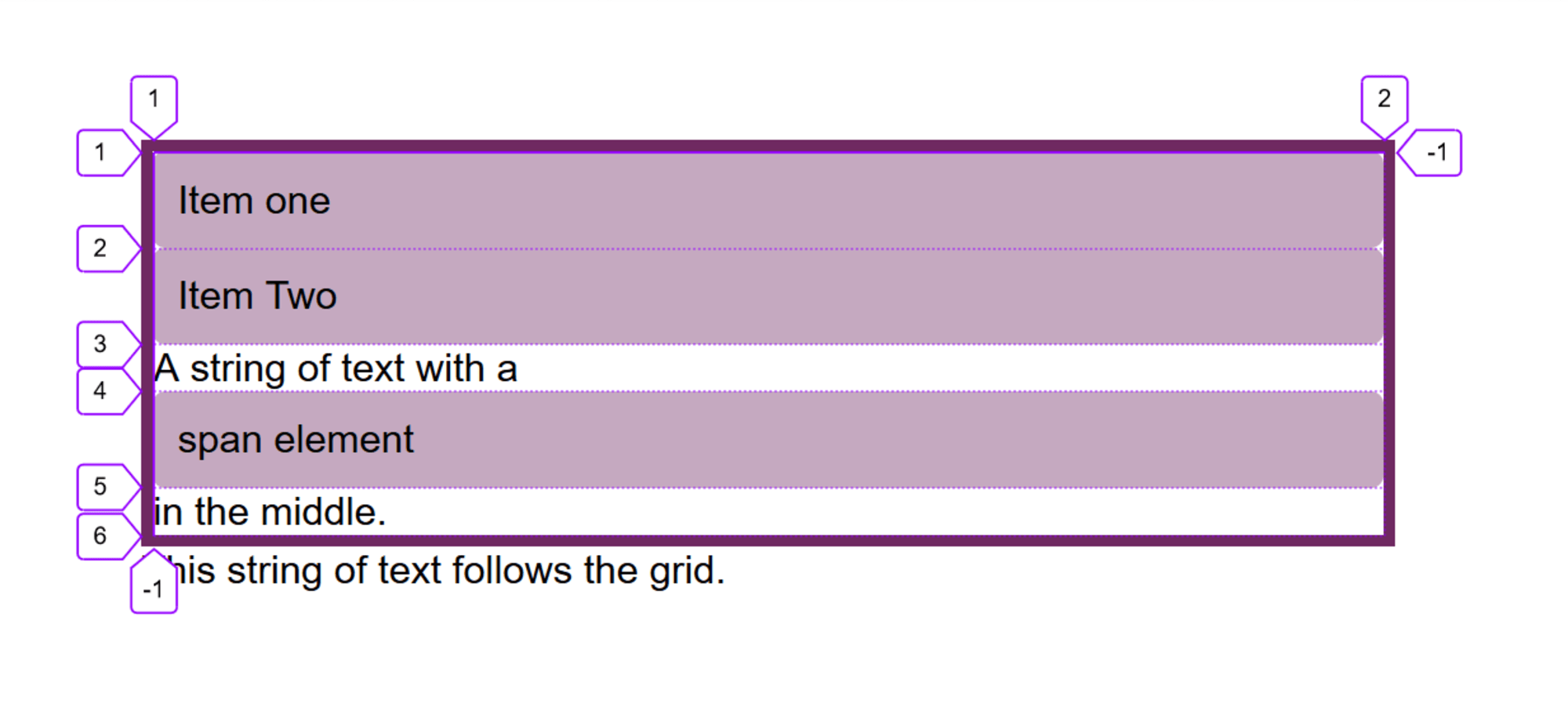








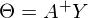 , где
, где 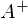 — псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
— псевдообратная матрица. Это решение наглядное, точное и короткое. Но есть проблема, которую можно решить численно. Градиентный спуск — метод численной оптимизации, который может быть использован во многих алгоритмах, где требуется найти экстремум функции — нейронные сети, SVM, k-средних, регрессии. Однако проще его воспринять в чистом виде (и проще модифицировать).
