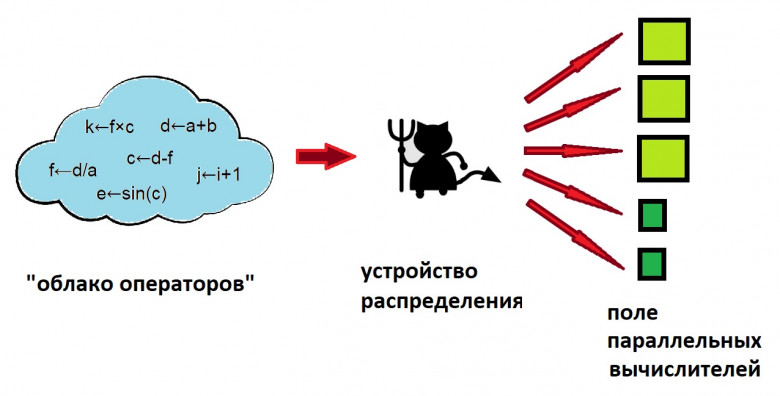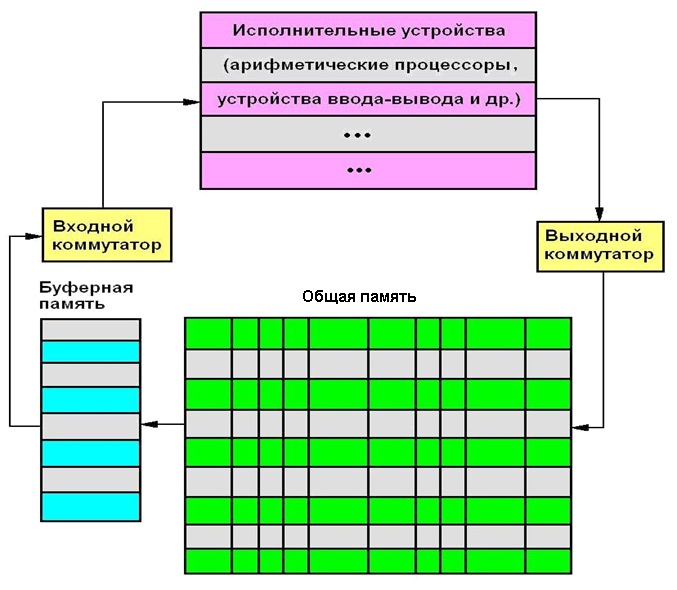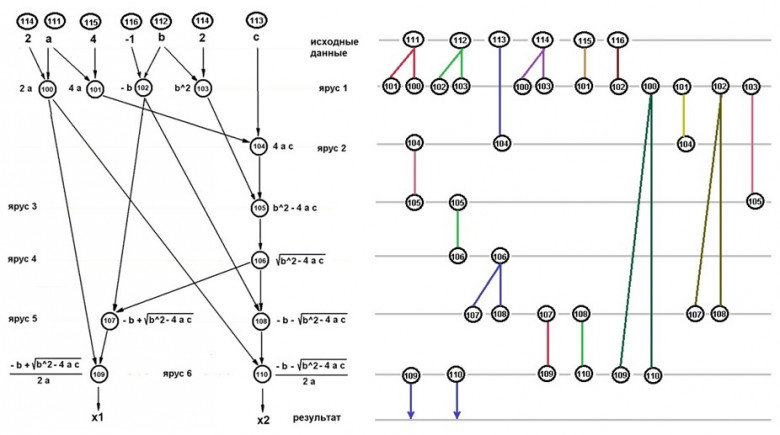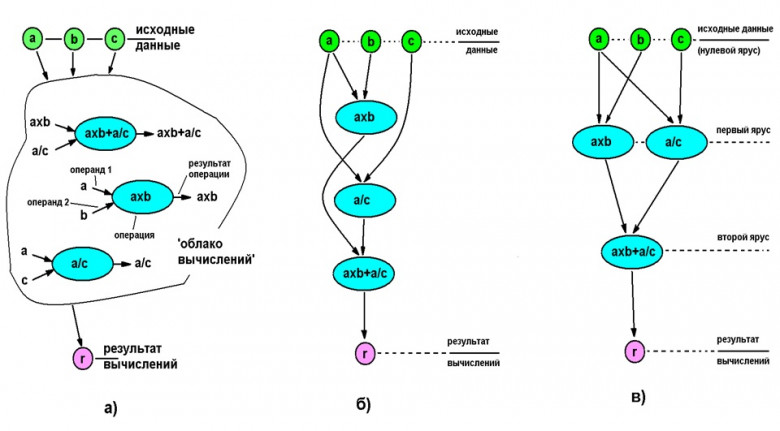
Процессоры архитектуры сверхдлинного машинного слова (VLIW - Very Long Instruction Word) относятся к специфическим классам архитектур, прямо нацеленным на использование внутреннего параллелизма в алгоритмах (программах), причём параллелизм этот анализируется и планируется к рациональному использованию при вычислениях на программном уровне; собственно аппаратная часть освобождается от процедур распараллеливания (и поэтому должна стать проще и экономичнее использующих внутреннее распараллеливание).
VLIW-подход основан на идее загрузки во входной буфер процессора одновременно набора (bundle) допускающих параллельное выполнение машинных команд и исполнения этого ряда команд аналогично единой команде в процессорах классической архитектуры. VLIW-процессоры реализуют параллелизм уровня ILP (Instruction-Level Parallelizm, параллелизм уровня машинных инструкций) и SMP (Symmetric MultiProcessing, системы с общей памятью) идеологему работы с оперативной памятью. Несмотря на выпуклое преимущество (программным путём дешевле реализовать сложные процедуры параллелизации), работа VLIW-процессоров сопряжена с известными проблемами. Среди них называют статичность полученных планов параллельного выполнения и проблемы с излишней неравномерностью времени доступа к оперативной памяти разных вычислительных ядер (временна́я антиплотность кода, следствием является резкое снижение производительности из-за неизбежности определять время выполнения всей связки команд сверхдлинного слова по продолжительности наиболее длинной из них).