
Как объяснить бабушке, что такое Agile за 15 минут с картинками
7 мин
Перевод
«Любое дело всегда длится дольше, чем ожидается, даже если учесть закон Хофштадтера.»
— закон Хофштадтера
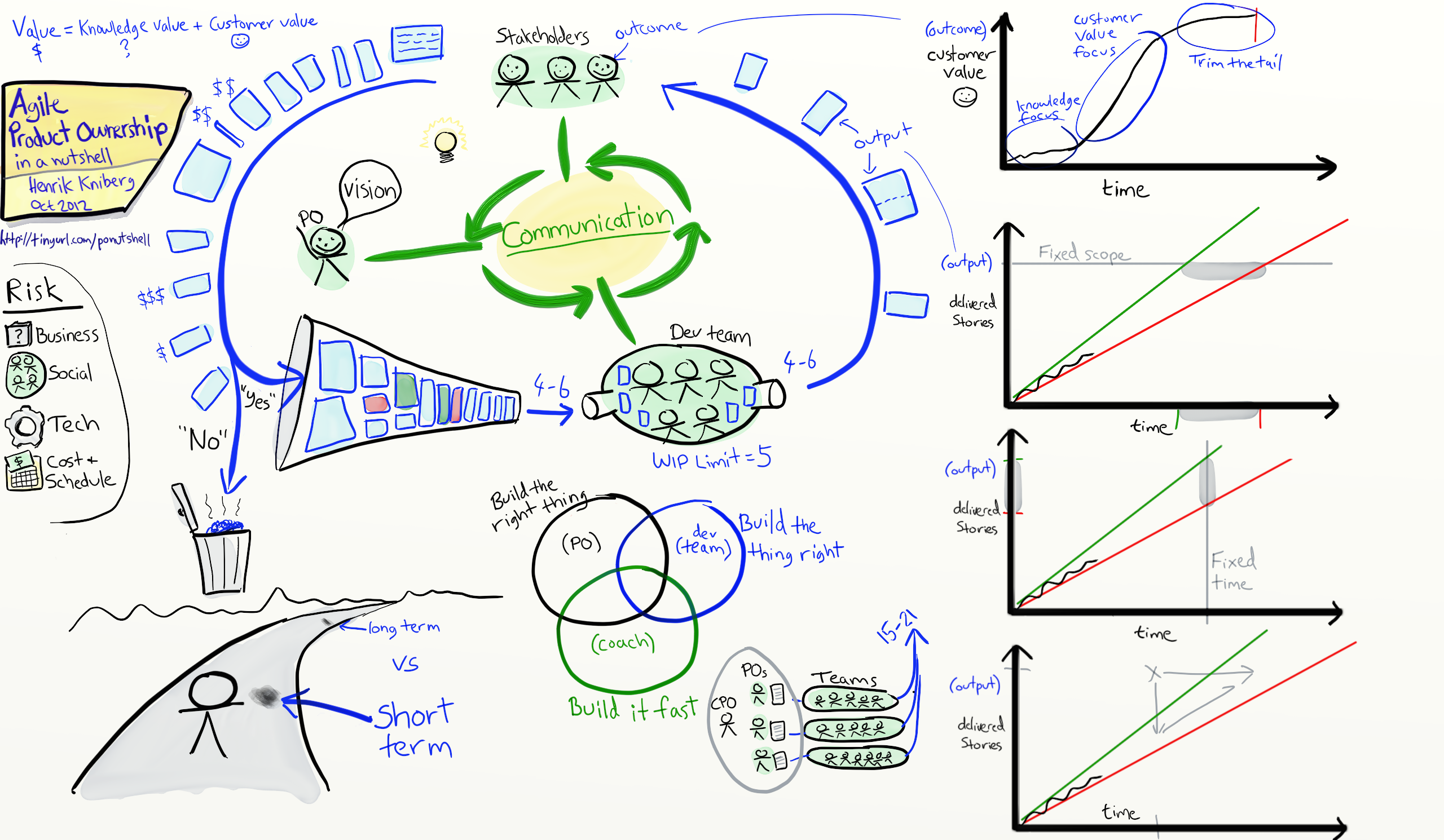
Самый просматриваемый ролик на YouTube по теме agile. 744 625 просмотров на момент публикации данной статьи. Легкий стиль изложения, картинки и всего 15 минут — лучшее что я видел. TED отдыхает.
— закон Хофштадтера
Самый просматриваемый ролик на YouTube по теме agile. 744 625 просмотров на момент публикации данной статьи. Легкий стиль изложения, картинки и всего 15 минут — лучшее что я видел. TED отдыхает.









 Под катом — перевод статьи опытного разработчика о его опыте практического применения Go. Важно — мнение переводчика может не совпадать с мнением автора статьи.
Под катом — перевод статьи опытного разработчика о его опыте практического применения Go. Важно — мнение переводчика может не совпадать с мнением автора статьи.