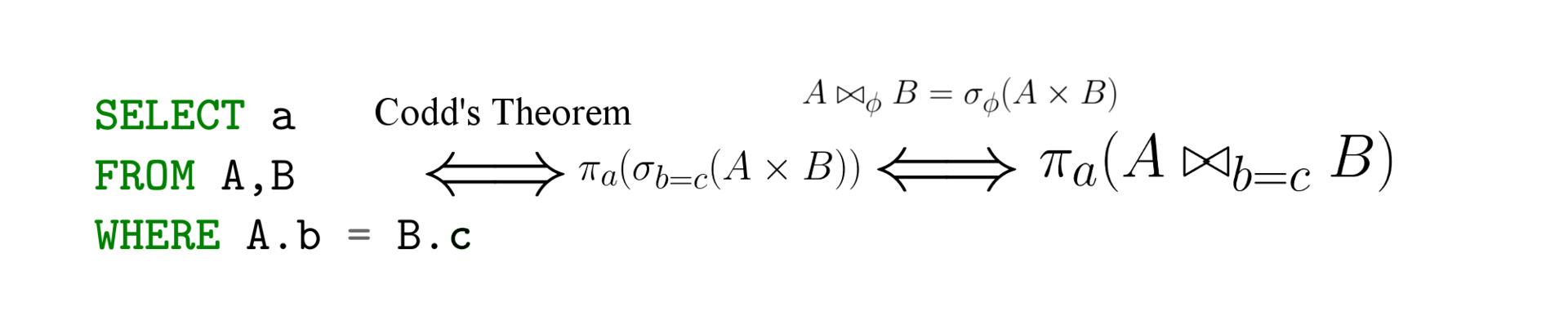Взлом Wi-Fi
7 мин
Перевод
Взлом маршрутизаторов WPA/WPA2 Wi-Fi с помощью Airodump-ng и Aircrack-ng/Hashcat
Это краткое пошаговое руководство, которое демонстрирует способ взлома сетей Wi-Fi, защищённых слабыми паролями. Оно не исчерпывающее, но этой информации должно хватить, чтобы вы протестировали свою собственную сетевую безопасность или взломали кого-нибудь поблизости. Изложенная ниже атака полностью пассивна (только прослушивание, ничего не транслируется с вашего компьютера) и о ней невозможно узнать, если вы только реально не воспользуетесь паролем, который взломали. Необязательную активную атаку с деаутентификацией можно применить для ускорения разведывательного процесса. Она описана в конце статьи.


 Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.
Реляционные базы данных (РБД) используются повсюду. Они бывают самых разных видов, от маленьких и полезных SQLite до мощных Teradata. Но в то же время существует очень немного статей, объясняющих принцип действия и устройство реляционных баз данных. Да и те, что есть — довольно поверхностные, без особых подробностей. Зато по более «модным» направлениям (большие данные, NoSQL или JS) написано гораздо больше статей, причём куда более глубоких. Вероятно, такая ситуация сложилась из-за того, что реляционные БД — вещь «старая» и слишком скучная, чтобы разбирать её вне университетских программ, исследовательских работ и книг.