На Хабре уже есть несколько статей\переводов, в которых рассказывается о неизвестных фичах\тонкостях\возможностях Пайтона. Я буду пытаться не повторять их, а дополнять, но если уж так случилось, что вы это уже где-то видели — не огорчайтесь. Я уверен, что найдется что-то интересное и для вас.

Пользователь
Руководство: пишем интерпретатор с JIT на PyPy
12 мин
Перевод
Все исходные коды и примеры из этой статьи доступны здесь.
Когда я первый раз смотрел проект PyPy, мне потребовалось некоторое время, чтобы выяснить, что он из себя представляет. Он состоит из двух вещей:
— набор инструментов для написания интерпретаторов языков программирования;
— реализация Питона с применением этого набора инструментов.
Вероятно, большинство людей думает, что PyPy это только вторая часть, но это руководство не об интерпретаторе Питона. Оно о том, как написать интерпретатор своего языка.
Я взялся за это руководство для того, чтобы лучше понять как работает PyPy и что он из себя представляет. Предполагается, что вы очень мало знаете о PyPy, поэтому я начну с самого начала.
Когда я первый раз смотрел проект PyPy, мне потребовалось некоторое время, чтобы выяснить, что он из себя представляет. Он состоит из двух вещей:
— набор инструментов для написания интерпретаторов языков программирования;
— реализация Питона с применением этого набора инструментов.
Вероятно, большинство людей думает, что PyPy это только вторая часть, но это руководство не об интерпретаторе Питона. Оно о том, как написать интерпретатор своего языка.
Я взялся за это руководство для того, чтобы лучше понять как работает PyPy и что он из себя представляет. Предполагается, что вы очень мало знаете о PyPy, поэтому я начну с самого начала.
Поисковые технологии или в чем загвоздка написать свой поисковик
3 мин
Когда-то давно взбрела мне в голову идея: написать свой собственный поисковик. Было это очень давно, тогда я еще учился в ВУЗе, мало чего знал про технологии разработки больших проектов, зато отлично владел парой десятков языков программирования и протоколов, да и сайтов своих к тому времени было понаделано много.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Ну есть у меня тяга к монструозным проектам, да…
В то время про то, как они работают было известно мало. Статьи на английском и очень скудные. Некоторые мои знакомые, которые были тогда в курсе моих поисков, на основе нарытых и мной и ими документов и идей, в том числе тех, которые родились в процессе наших споров, сейчас делают неплохие курсы, придумывают новые технологии поиска, в общем, эта тема дала развитие довольно интересным работам. Эти работы привели в том числе к новым разработкам разных крупных компаний, в том числе Google, но я лично прямого отношения к этому не имею.
На данный момент у меня есть собственный, обучающийся поисковик от и до, со многими нюансами – подсчетом PR, сбором статистик-тематик, обучающейся функцией ранжирования, ноу хау в виде отрезания несущественного контента страницы типа меню и рекламы. Скорость индексации примерно полмиллиона страниц в сутки. Все это крутится на двух моих домашних серверах, и в данный момент я занимаюсь масштабированием системы на примерно 5 свободных серверов, к которым у меня есть доступ.
Опасности обучения на Java
10 мин
Перевод
«Вы счастливчики. Мы по три месяца жили в мешках из дерюги в грязных сараях. Мы вставали в шесть утра, стирали мешки, съедали по корке чёрствого хлеба и шли работать на мельницу, по 14 часов в день, с понедельника и до воскресенья, и когда мы возвращались домой, наш папа порол нас своим ремнем»
— Летающий цирк Монти Пайтона, Четыре йоркширца
Ленивая молодёжь.
Что может быть хорошего в тяжёлой работе?
Верный признак моего старения — моё ворчание и жалобы о «современной молодёжи» и о том, как не хотят или не могут больше делать ничего сложного.
— Летающий цирк Монти Пайтона, Четыре йоркширца
Ленивая молодёжь.
Что может быть хорошего в тяжёлой работе?
Верный признак моего старения — моё ворчание и жалобы о «современной молодёжи» и о том, как не хотят или не могут больше делать ничего сложного.
Тестирование. Начало
4 мин

Привет. В этой серии постов я попробую рассказать про тестирование кода на питоне, в частности проектов django. Мы рассмотрим модульное тестирование (юнит-тесты), статический анализ кода и некоторые подводные камни тестирования веб-сайтов.
Вводную часть о пользе тестирования опустим — код, покрытый тестами, становится мягким и шелковистым, про это только ленивый еще не читал / писал.
Руководство к дескрипторам
10 мин
Перевод
Краткий обзор
В этой статье я расскажу о том, что такое дескрипторы, о протоколе дескрипторов, покажу как вызываются дескрипторы. Опишу создание собственных и исследую несколько встроенных дескрипторов, включая функции, свойства, статические методы и методы класса. С помощью простого приложения покажу, как работает каждый из них, приведу эквиваленты внутренней реализации работы дескрипторов кодом на чистом питоне.
Изучение того, как работают дескрипторы, откроет доступ к большему числу рабочих инструментов, поможет лучше понять как работает питон, и ощутить элегантность его дизайна.
Двоичные таблицы Юнга
7 мин
Итак, как и обещал, продолжение темы о таблицах Юнга. Напомню, что под таблицей Юнга понимается числовая матрица, обладающая некоторыми специальными свойствами. Матрица – это двумерный массив. И вот тут должен возникнуть естественный вопрос – а почему, собственно, массив должен быть двумерным? А что, если мы попробуем реализовать на тех же принципах таблицу размерности три, или четыре, а лучше всего, конечно, пять звездочек! О том, куда приведет нас такое обобщение, можно прочитать под катом…
Сага о том, как мы писали консоль
8 мин
Если посадить тысячу мартышек за тысячу пишущих машинок, то за тысячу лет они напишут эмулятор терминала. — вместо эпиграфа.
Извините фальстарт, это не я, это андроидный смартбук.
Когда мы только запускали облако, первой проблемой было «как нам получить консоль». Штатный механизм XCP поразумевает, что консоль рисуется с помощью VNCTerm, а желающий её увидеть должен сначала пойти в XenAPI, получить там session-id консоли, пойти на порт консоли, передать session-id, получить RFB, завёрнутый в HTTP, развернуть HTTP, вынуть RFB (он же VNC), отдать её локальному рендереру VNC (VNC-клиенту или java-апплету с тем же функционалом). При этом консоль закрывалась (сессия рвалась) при каждой перезагрузке виртуальной машины. Она рвалась даже при миграции виртуальной машины. Другими словами, это была технология, которая подразумевала «глянул одним глазком, починил ssh/iptables и забыл». Неудобно, медленно, сложно. Выкатывать такое в продакт совсем не хотелось.
И я залез в дебри serial-howto, console-howto и ещё несколько ужасных документов, рассказывающих о том, как правильно нужно конфигуриовать прерывания на ISA плате у мультикарт, а так же специфику настройки linux-2.2 для работы с оными. Параллельно изучалось устройство консоли в зене (внимательный читатель мог даже заметить, когда именно я более-менее разобрался в этом вопросе — я писал на хабре краткий обзор того, что происходит с консолью).
После этого пришла мысль: нужно писать своё, потому что готового чужого хорошего нет.
Сначала мы хотели взять хотя бы готовые компоненты и сделать из них своё. Я помню до сих пор ту замечательную схему, в которой мы планировали сохранять в БД вывод anyterm'а, делать двойное туннелирование последовательного порта с использованием UDP… Выглядело это, мягко скажем, неприглядно.
Потом пришла в голову мысль выпилить anyterm. Для этого нужно было посмотреть, как работают терминалки. Это было очень забавно и поучительно (желающие могут изучить исходный текст PuTTY). Главной проблемой в этом изучении было то, что они много рисуют на экран. Прямо в процессе обработки ввода. Отделить специфику DC от, собственно, того, что является консолью, было сложно.
Через некоторое время мы пришли к идее «нам нужен свой эмулятор терминала».
Задача казалась относительно простой, пока мы не прикоснулись к бездне, именуемой «escape-коды и типы терминалов...».
Итак, в начале была пишущая машинка. В какой-то момент возникло желание совместить телеграф с пишущей машинкой. Так возник телетайп
Разумеется, инженерам, создававшим телетайп, не было никакого резона делать все с нуля. Они просто приделали коды к каждой клавише пишущей машинки. После некоторых боёв в стиле MS VS Netscape, был создан стандартhtml5 на коды для оных машинок, то бишь телетайпов. Если мне память не изменяет, то это ASCII, где предусмотрены все комбинации клавиш, характерные для американской пишущей машинки. Включая код BELL, который, кстати, должен вовсе не делать BEEP, а делать «дзыньк», ибо у пишущих машинок был именно колокольчик, а не спикер.
Извините фальстарт, это не я, это андроидный смартбук.
Когда мы только запускали облако, первой проблемой было «как нам получить консоль». Штатный механизм XCP поразумевает, что консоль рисуется с помощью VNCTerm, а желающий её увидеть должен сначала пойти в XenAPI, получить там session-id консоли, пойти на порт консоли, передать session-id, получить RFB, завёрнутый в HTTP, развернуть HTTP, вынуть RFB (он же VNC), отдать её локальному рендереру VNC (VNC-клиенту или java-апплету с тем же функционалом). При этом консоль закрывалась (сессия рвалась) при каждой перезагрузке виртуальной машины. Она рвалась даже при миграции виртуальной машины. Другими словами, это была технология, которая подразумевала «глянул одним глазком, починил ssh/iptables и забыл». Неудобно, медленно, сложно. Выкатывать такое в продакт совсем не хотелось.
И я залез в дебри serial-howto, console-howto и ещё несколько ужасных документов, рассказывающих о том, как правильно нужно конфигуриовать прерывания на ISA плате у мультикарт, а так же специфику настройки linux-2.2 для работы с оными. Параллельно изучалось устройство консоли в зене (внимательный читатель мог даже заметить, когда именно я более-менее разобрался в этом вопросе — я писал на хабре краткий обзор того, что происходит с консолью).
После этого пришла мысль: нужно писать своё, потому что готового чужого хорошего нет.
Сначала мы хотели взять хотя бы готовые компоненты и сделать из них своё. Я помню до сих пор ту замечательную схему, в которой мы планировали сохранять в БД вывод anyterm'а, делать двойное туннелирование последовательного порта с использованием UDP… Выглядело это, мягко скажем, неприглядно.
Потом пришла в голову мысль выпилить anyterm. Для этого нужно было посмотреть, как работают терминалки. Это было очень забавно и поучительно (желающие могут изучить исходный текст PuTTY). Главной проблемой в этом изучении было то, что они много рисуют на экран. Прямо в процессе обработки ввода. Отделить специфику DC от, собственно, того, что является консолью, было сложно.
Через некоторое время мы пришли к идее «нам нужен свой эмулятор терминала».
Задача казалась относительно простой, пока мы не прикоснулись к бездне, именуемой «escape-коды и типы терминалов...».
Пишущие машинки
Итак, в начале была пишущая машинка. В какой-то момент возникло желание совместить телеграф с пишущей машинкой. Так возник телетайп
Разумеется, инженерам, создававшим телетайп, не было никакого резона делать все с нуля. Они просто приделали коды к каждой клавише пишущей машинки. После некоторых боёв в стиле MS VS Netscape, был создан стандарт
Таблицы Юнга в задачах поиска и сортировки
6 мин
Таблицы Юнга являются широко известным (в узких кругах) типом объектов, изучаемых в комбинаторике и смежных науках: ссылка, ссылка, книжка. Ниже рассматривается применение частного вида таблиц Юнга применительно к таким стандартным алгоритмическим задачам, как поиск и сортировка. С этой точки зрения таблицы Юнга весьма близки пирамидам, собственно так они и позиционируются в учебнике Кормена и ко (упражнения в разделе, посвященном пирамидам).
Lightcycle demo using WebGL (part 0)
17 мин
Вступление
Мне нравится осваивать новые технологии, делая то, чем раньше вообще не занимался. А еще мне нравится TRON. Оба фильма, кстати. Помню, еще до того, как я их посмотрел, в студенческие дремучие времена, я играл в Armagetron и фанател от гонок на светоциклах. После просмотра TRON: Legacy мне внезапно захотелось сделать свой Tron с гридом и изоморфами. Недолго думая, я запустил любимую Visual Studio Express и задумался — а чем это мое творение будет отличаться от свалки клонов «Трона»? Студия плавно закрылась, а мой энтузиазм несколько поутих. Ровно до того момента, как мне на глаза попалась какая-то статья о WebGL. Глаза снова загорелись, а руки сами потянулись к редактору. В голову как-то не приходила мысль, что последний раз я на JavaScript делал обработчик нажатия кнопки на зачет по какому-то предмету.
Итак, сегодня в программе:
- Низкоуровневое программирование WebGL.
- Рендеринг простого трехмерного объекта.
- Подробные комментарии процесса разработки.
- Много букв и код на JavaScript.
- Бесплатная выпивка и приятная музыка.

Статья предназначена для тех, кому просто нечего делать и хочется почитать про то, как другие тратят свое время за компьютером вместо прогулок под теплым летним солнцем.
«Выглядит похоже». Как работает перцептивный хэш
6 мин
Перевод
За последние несколько месяцев несколько человек спросили меня, как работает TinEye и как в принципе работает поиск похожих картинок.
По правде говоря, я не знаю, как работает поисковик TinEye. Он не раскрывает деталей используемого алгоритма(-ов). Но глядя на поисковую выдачу, я могу сделать вывод о работе какой-то формы перцептивного хэш-алгоритма.
По правде говоря, я не знаю, как работает поисковик TinEye. Он не раскрывает деталей используемого алгоритма(-ов). Но глядя на поисковую выдачу, я могу сделать вывод о работе какой-то формы перцептивного хэш-алгоритма.
Разработка игр с использованием Cocos2d на Python
5 мин

Введение
Имплементация Cocos2d на Objective-C используется для разработки игр для iPhone весьма широко. По данным официального сайта число игр на этом движке уже превышает 1800. Не раз упоминался он и на Хабре. Другие порты (cocos2d-x на C++ и cocos2d-android на Java) также известны и набирают популярность. Однако прародитель этих движков, оригинальный Cocos2d оказался незаслуженно обойден вниманием. Попробую восполнить этот пробел.
JavaScript F.A.Q: Часть 1
15 мин
Несколько дней назад мы с TheShock создали топик в котором собирали ваши вопросы, касательно JavaScript (архитектура, фрэймворки, проблемы). Настало время ответить на них. Мы получили очень много вопросов, как в комментариях так и по email. Эта первая часть ответов — те вопросы, которые достались мне.
Пора завязывать
4 мин
 Может быть, стоило написать в «Я негодую». Не знаю. Пока писал, расколотил чашку с чаем и таким образом достиг хладнокровия.
Может быть, стоило написать в «Я негодую». Не знаю. Пока писал, расколотил чашку с чаем и таким образом достиг хладнокровия.Я про вот что: раз и два.
Есть же множество прекрасных тем для холиваров: Windows или Linux, IE или FF, Canon и Nikon, Intel и AMD, «на Украине» или «в Украине». Чужой или Хищник, наконец!
Так нет же, зацепились на ровном месте: пробелы и табуляции.
HTML5 как победа научного материализма
15 мин
Стандарт HTML5 уже почти готов к использованию. Где-то все еще идут жаркие споры по конкретным секциям DOM, видеокодекам, анимации и прочим 3D, но основа HTML5 — его синтаксис, атрибуты и теги — уже устаканились. Эти разделы стандарта не меняются уже многие месяцы; окончательно и по факту их зафиксируют релизы IE9 и FF4, после чего какие-либо их изменения в рамках пятой версии станут невозможны.
Так как костыли для старых версий IE уже созданы и обкатаны, то уже совсем-совсем скоро, начиная новый проект, можно будет открыть свой любимый редактор и, не скрывая наслаждения, написать
Сначала, конечно, html5 появится скорее в бложиках энтузиастов, чем на серьезных сайтах, но — вот увидите — через несколько лет в каждой региональной газете появятся объявления типа «ремонт и настройка ПК, заправка принтеров, 1С, сайты на HTML5».
В IT, как и в других областях техники, спецификации бывают хорошие, как у Страуструпа, а бывают плохие и даже отвратительные, как спецификация ECMAScript. По моему скромному мнению, спецификация HTML5 обещает стать воистину великой, просто-таки образцовой вершиной этого бюрократического жанра.
Пролистывая на выходных свежую версию черновика стандарта (от 5-ого марта), я в очередной раз не мог не восхититься изящностью принятых решений и филигранной точностью формулировок родившейся в тяжелых муках спецификации.
Эта статья о том, почему стандарт html5 получился именно такой, и что на самом деле скрывается за его внешне обтекаемыми формулировками.
Так как костыли для старых версий IE уже созданы и обкатаны, то уже совсем-совсем скоро, начиная новый проект, можно будет открыть свой любимый редактор и, не скрывая наслаждения, написать
<!doctype html>Сначала, конечно, html5 появится скорее в бложиках энтузиастов, чем на серьезных сайтах, но — вот увидите — через несколько лет в каждой региональной газете появятся объявления типа «ремонт и настройка ПК, заправка принтеров, 1С, сайты на HTML5».
В IT, как и в других областях техники, спецификации бывают хорошие, как у Страуструпа, а бывают плохие и даже отвратительные, как спецификация ECMAScript. По моему скромному мнению, спецификация HTML5 обещает стать воистину великой, просто-таки образцовой вершиной этого бюрократического жанра.
Пролистывая на выходных свежую версию черновика стандарта (от 5-ого марта), я в очередной раз не мог не восхититься изящностью принятых решений и филигранной точностью формулировок родившейся в тяжелых муках спецификации.
Эта статья о том, почему стандарт html5 получился именно такой, и что на самом деле скрывается за его внешне обтекаемыми формулировками.
AA-Tree или простое бинарное дерево
6 мин
Тема бинарных деревьев уже обсуждалась на хабре (здесь и здесь).
Про AA-дерево было сказано, что «из-за дополнительного ограничения операции реализуются проще чем у красно-черного дерева (за счет уменьшения количества разбираемых случаев)».
Мне, однако, кажется, что AA-дерево заслуживает отдельной статьи.
Про AA-дерево было сказано, что «из-за дополнительного ограничения операции реализуются проще чем у красно-черного дерева (за счет уменьшения количества разбираемых случаев)».
Мне, однако, кажется, что AA-дерево заслуживает отдельной статьи.
TOP'ай сюда
5 мин
Обзор практически всех *top утилит под linux (atop, iotop, htop, foobartop и т.д.).
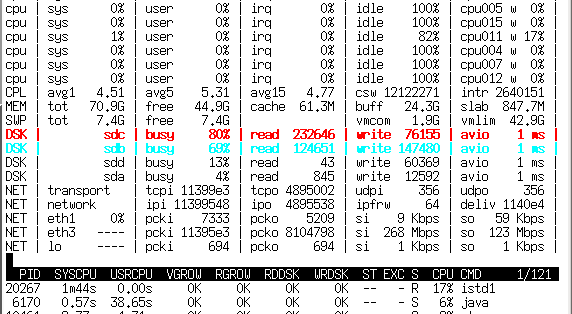
Atop имеет два режима работы — сбор статистики и наблюдение за системой в реальном времени. В режиме сбора статистики atop запускается как демон и раз в N времени (обычно 10 мин) скидывает состояние в двоичный журнал. Потом по этому журналу atop'ом же (ключ -r и имя лог-файла) можно бегать вперёд-назад кнопками T и t, наблюдая показания atop'а с усреднением за 10 минут в любой интересный момент времени.
В отличие от top отлично знает про существование блочных устройств и сетевых интерфейса, способен показывать их загрузку в процентах (на 10G, правда, процентов не получается, но хотя бы показывается количество мегабит).
Незаменимое средство для поиска источников лагов на сервере, так как сохраняет не только статистику загрузки системы, но и показатели каждого процесса — то есть «долистав» до нужного момента времени можно увидеть, кто этот счастливый момент с LA > 30 создал. И что именно было причиной — IO программ, своп (нехватка памяти), процесор или что-то ещё. Помимо большего количества информации ещё способен двумя цветами подсказывать, какие параметры выходят за разумные пределы.
top
Все мы знаем top — самую простую и самую распространённую утилиту из этого списка. Показывает примерно то же, что утилита vmstat, плюс рейтинг процессов по потреблению памяти или процессора. Совсем ничего не знает про загрузку сети или дисков. Позволяет минимальный набор операций с процессом: renice, kill (в смысле отправки сигнала, убийство — частный случай). По имени top суффикс "-top" получили и все остальные подобные утилиты в этом обзоре.atop
Atop имеет два режима работы — сбор статистики и наблюдение за системой в реальном времени. В режиме сбора статистики atop запускается как демон и раз в N времени (обычно 10 мин) скидывает состояние в двоичный журнал. Потом по этому журналу atop'ом же (ключ -r и имя лог-файла) можно бегать вперёд-назад кнопками T и t, наблюдая показания atop'а с усреднением за 10 минут в любой интересный момент времени.
В отличие от top отлично знает про существование блочных устройств и сетевых интерфейса, способен показывать их загрузку в процентах (на 10G, правда, процентов не получается, но хотя бы показывается количество мегабит).
Незаменимое средство для поиска источников лагов на сервере, так как сохраняет не только статистику загрузки системы, но и показатели каждого процесса — то есть «долистав» до нужного момента времени можно увидеть, кто этот счастливый момент с LA > 30 создал. И что именно было причиной — IO программ, своп (нехватка памяти), процесор или что-то ещё. Помимо большего количества информации ещё способен двумя цветами подсказывать, какие параметры выходят за разумные пределы.
Двадцать вопросов, которые помогают разработать алгоритм
5 мин
Как разработать алгоритм, решающий сложную задачу? Многие считают, что для этого нужно «испытать озарение», что процесс этот не вполне рационален и зависит от творческой силы или таланта.
На самом деле решение любой задачи сводится к сбору информации о наблюдаемом объекте. Причем этот принцип применим как для решения самых сложных научно-исследовательских задач, так и для решения прикладных задач. Работа изобретателя напоминает не столько работу волшебника, сколько путешествие первооткрывателя по неизведанной территории. Главное качество хорошего изобретателя – умение собирать информацию.
Если вы хотите решить сложную задачу, собирайте информацию в самых разных направлениях. Ответив на следующие 20 вопросов, вы легко выстроите план работы над задачей.
На самом деле решение любой задачи сводится к сбору информации о наблюдаемом объекте. Причем этот принцип применим как для решения самых сложных научно-исследовательских задач, так и для решения прикладных задач. Работа изобретателя напоминает не столько работу волшебника, сколько путешествие первооткрывателя по неизведанной территории. Главное качество хорошего изобретателя – умение собирать информацию.
Если вы хотите решить сложную задачу, собирайте информацию в самых разных направлениях. Ответив на следующие 20 вопросов, вы легко выстроите план работы над задачей.