На протяжении 2010-х в IT набирает популярность digital detox — «цифровая разгрузка». Несколько лет назад основательница компании Kovert Designs на 4 дня вывезла 35 гендиректоров в марокканскую пустыню, где у тех не было ни смартфонов, ни интернета. А заодно с ними — неврологов, которые изучали, как краткосрочное отсутствие доступа к цифровым технологиям влияет на состояние человека. Оказалось — прекрасно, особенно на память и внимание. Но необязательно ехать в пустыню. Действенный способ перезапустить мозг — отправиться в поход на 1–3 дня. Конечно, чтобы сделать это безопасно и с комфортом, необходимо снаряжение. Разбираемся, какая экипировка нужна тем, кто хочет очистить «мозговой кэш», выбираясь на природу.

Maxim W@maximw
backend developer
Структура Data Science-проекта с высоты птичьего полета
6 мин
Как узнать наверняка, что внутри у колобка?
Может, ты его проглотишь, а внутри него река? © Таня Задорожная
Что такое Data Science сегодня, кажется, знают уже не только дети, но и домашние животные. Спроси любого котика, и он скажет: статистика, Python, R, BigData, машинное обучение, визуализация и много других слов, в зависимости от квалификации. Но не все котики, а также те, кто хочет стать специалистом по Data Science, знают, как именно устроен Data Science-проект, из каких этапов он состоит и как каждый из них влияет на конечный результат, насколько ресурсоемким является каждый из этапов проекта. Для ответа на эти вопросы как правило служит методология. Однако бОльшая часть обучающих курсов, посвященных Data Science, ничего не говорит о методологии, а просто более или менее последовательно раскрывает суть упомянутых выше технологий, а уж со структурой проекта каждый начинающий Data Scientist знакомится на собственном опыте (и граблях). Но лично я люблю ходить в лес с картой и компасом и мне нравится заранее представлять план маршрута, которым двигаешься. После некоторых поисков неплохую методологию мне удалось найти у IBM — известного производителя гайдов и методик по управлению чем угодно.
Must-have алгоритмы машинного обучения
5 мин
Перевод
Хабр, привет.
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Этот пост — краткий обзор общих алгоритмов машинного обучения. К каждому прилагается краткое описание, гайды и полезные ссылки.
Это один из основных алгоритмов машинного обучения. Позволяет уменьшить размерность данных, потеряв наименьшее количество информации. Применяется во многих областях, таких как распознавание объектов, компьютерное зрение, сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных или к сингулярному разложению матрицы данных.
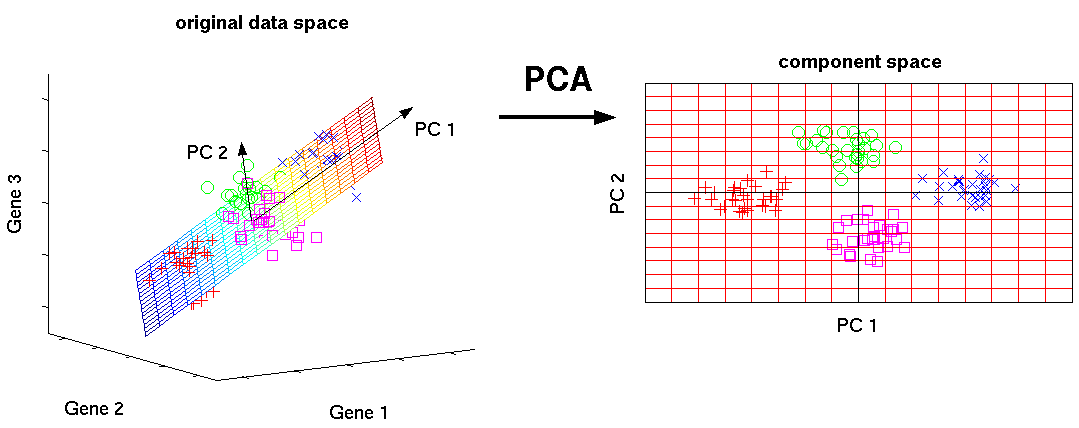
SVD — это способ вычисления упорядоченных компонентов.
Полезные ссылки:
Вводный гайд:
Меня зовут Рушан, и я автор Telegram‑канала Нейрон. Не забудьте поделиться с коллегами или просто с теми, кому интересны такие статьи. Этот пост — краткий обзор общих алгоритмов машинного обучения. К каждому прилагается краткое описание, гайды и полезные ссылки.
Метод главных компонент (PCA)/SVD
Это один из основных алгоритмов машинного обучения. Позволяет уменьшить размерность данных, потеряв наименьшее количество информации. Применяется во многих областях, таких как распознавание объектов, компьютерное зрение, сжатие данных и т. п. Вычисление главных компонент сводится к вычислению собственных векторов и собственных значений ковариационной матрицы исходных данных или к сингулярному разложению матрицы данных.
SVD — это способ вычисления упорядоченных компонентов.
Полезные ссылки:
Вводный гайд:
Кластеризуем лучше, чем «метод локтя»
4 мин
Перевод

Кластеризация — важная часть конвейера машинного обучения для решения научных и бизнес-задач. Она помогает идентифицировать совокупности тесно связанных (некой мерой расстояния) точек в облаке данных, определить которые другими средствами было бы трудно.
Однако процесс кластеризации по большей части относится к сфере машинного обучения без учителя, для которой характерен ряд сложностей. Здесь не существует ответов или подсказок, как оптимизировать процесс или оценить успешность обучения. Это неизведанная территория.
Умные алгоритмы обработки строк в ClickHouse
12 мин
В ClickHouse постоянно возникают задачи, связанные с обработкой строк. Например, поиск, вычисление свойств UTF-8 строк или что-то более экзотическое, будь то поиск типа учёта регистра или поиск по сжатым данным.
Всё началось с того, что руководитель разработки ClickHouse Лёша Миловидов o6CuFl2Q пришёл к нам на факультет компьютерных наук в НИУ ВШЭ и предложил огромное количество тем для курсовых и дипломов. Когда я увидел «Умные алгоритмы обработки строк в ClickHouse» (я, человек, который увлекается разными алгоритмами, в том числе экспериментальными), сразу же настроил планов, как сделаю самый крутой диплом. Мою радость и выражение лица можно описать следующей картинкой:

Что почитать и посмотреть для старта в Data Science: книги, словари и курсы
3 мин
Подборка ресурсов по математике, статистике и программированию для начинающих Дата Сайентистов. Ознакомьтесь с материалами, если вы планируете учиться на онлайн-курсах. Так вы опередите одногруппников, а заодно прокачаете полезный навык — изучать дополнительные материалы самостоятельно.
Визуализация больших графов для самых маленьких
12 мин

Что делать, если вам нужно нарисовать граф, но попавшиеся под руку инструменты рисуют какой-то комок волос или вовсе пожирают всю оперативную память и вешают систему? За последние пару лет работы с большими графами (сотни миллионов вершин и рёбер) я испробовал много инструментов и подходов, и почти не находил достойных обзоров. Поэтому теперь пишу такой обзор сам.
GPS трекер BOXY
9 мин
Привет, Хабр!
GPS трекером уже никого не удивишь — это факт. Написать этот краткий обзор решил, когда первый раз взял в руки эту «фитюльку». Ну, по порядку: появилась задача – оснастить трекером домашнего питомца. Не то чтобы он убегал постоянно, но для общего спокойствия что-то надо закрепить на его ошейник. «Тех задание» выглядело так:

В итоге, поиск компактного трекера привёл к написанию данного обзора.
GPS трекером уже никого не удивишь — это факт. Написать этот краткий обзор решил, когда первый раз взял в руки эту «фитюльку». Ну, по порядку: появилась задача – оснастить трекером домашнего питомца. Не то чтобы он убегал постоянно, но для общего спокойствия что-то надо закрепить на его ошейник. «Тех задание» выглядело так:
- максимально компактный GPS трекер с возможностью отслеживать положение онлайн;
- аккумулятора должно хватить на день или больше.
В итоге, поиск компактного трекера привёл к написанию данного обзора.
Очень много YouTube-каналов для прокачки английского языка для программистов
4 мин
Туториал
Привет, Хабр!
С помощью YouTube можно ощутимо и сравнительно быстро улучшить английский.
Понимание на слух как минимум. Истина не нова, но мало кто смотрит английский YouTube, потому что легко потеряться в бесконечности каналов. Но для вас я собрал самые стоящие каналы!
Добавляйте в закладки и подписывайтесь на меня!
Дальше вас ждет много крутых статей.
AJ Hoge. На его канале есть всё: от базовых слов до размышлений о важности языка тела в общении. Чувак пилит видосы уже много лет, материальчик накопился.
EngVid. Если бы можно было выбрать что-то одно для улучшения английского, то это оно. Разные преподы и тематики, постоянное обновление, бездонный ресурс. Ещё сайт одноимённый крутой, с удобной навигацией — можно найти очень узкую тему по интересам.
С помощью YouTube можно ощутимо и сравнительно быстро улучшить английский.
Понимание на слух как минимум. Истина не нова, но мало кто смотрит английский YouTube, потому что легко потеряться в бесконечности каналов. Но для вас я собрал самые стоящие каналы!
Добавляйте в закладки и подписывайтесь на меня!
Дальше вас ждет много крутых статей.
Поучить английский
AJ Hoge. На его канале есть всё: от базовых слов до размышлений о важности языка тела в общении. Чувак пилит видосы уже много лет, материальчик накопился.
EngVid. Если бы можно было выбрать что-то одно для улучшения английского, то это оно. Разные преподы и тематики, постоянное обновление, бездонный ресурс. Ещё сайт одноимённый крутой, с удобной навигацией — можно найти очень узкую тему по интересам.
Нечувствительные к весам нейронные сети (WANN)
6 мин
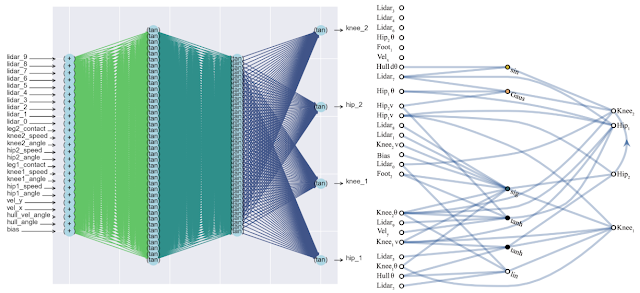
Новая работа Google предлагает архитектуру нейронных сетей, способных имитировать врожденные инстинкты и рефлексы живых существ, с последующим дообучением в течение жизни.
А также значительно уменьшающую количество связей внутри сети, повышая тем самым их быстродействие.
Time series данные в реляционной СУБД. Расширения TimescaleDB и PipelineDB для PostgreSQL
21 мин
Time series данные или временные ряды — это данные, которые изменяются во времени. Котировки валют, телеметрия перемещения транспорта, статистика обращения к серверу или нагрузки на CPU — это time series данные. Чтобы их хранить требуются специфичные инструменты — темпоральные базы данных. Инструментов — десятки, например, InfluxDB или ClickHouse. Но даже у самых лучших решений для хранения временных рядов есть недостатки. Все time series хранилища низкоуровневые, подходят только для time series данных, а обкатка и внедрение в текущий стек — дорого и больно.

Но, если у вас стек PostgreSQL, то можете забыть о InfluxDB и всех остальных темпоральных БД. Ставите себе два расширения TimescaleDB и PipelineDB и храните, обрабатываете и проводите аналитику time series данных прямо в экосистеме PostgreSQL. Без внедрения сторонних решений, без недостатков темпоральных хранилищ и без проблем их обкатки. Что это за расширения, в чем их преимущества и возможности, расскажет Иван Муратов (binakot) — руководитель отдела разработки в «Первой Мониторинговой Компании».
Но, если у вас стек PostgreSQL, то можете забыть о InfluxDB и всех остальных темпоральных БД. Ставите себе два расширения TimescaleDB и PipelineDB и храните, обрабатываете и проводите аналитику time series данных прямо в экосистеме PostgreSQL. Без внедрения сторонних решений, без недостатков темпоральных хранилищ и без проблем их обкатки. Что это за расширения, в чем их преимущества и возможности, расскажет Иван Муратов (binakot) — руководитель отдела разработки в «Первой Мониторинговой Компании».
Шесть навыков, которые выведут вашу карьеру в Data Science на новый уровень
4 мин
Перевод
Перед вами перевод статьи Genevieve Hayes, Data Scientist с 15-летним опытом работы. Автор рассказывает о том, какие навыки стоит развивать, чтобы значительно увеличить шансы найти работу в Data Science. Чтобы определить эти навыки, она проанализировала 100 вакансий, размещенных работодателями из Австралии, Канады, Великобритании и США.

15 книг по машинному обучению для начинающих
5 мин
Сделал подборку книг по Machine Learning для тех, кто хочет разобраться, что да как.
Добавляйте в закладки и делитесь с коллегами!
1. «Математические основы машинного обучения и прогнозирования» Владимир Вьюгин.
О чем
Сначала изучите азы статистической теории машинного обучения, игр с предсказаниями и прогнозирования с применением экспертной стратегии. Их основы прекрасно объясняет автор книги, доктор физико-математических наук Владимир Вьюгин. Пособие рассчитано на студентов и аспирантов и в доступной форме излагает математические основы, необходимые для дальнейшей работы с машинным обучением.
2. «Верховный алгоритм» Педро Домингос.
О чем
Книга, благодаря которой даже ничего не смыслящие в математике и статистике люди поймут, что такое алгоритмы машинного обучения и каково их применение в жизни. Профессор Педро Домингос рассказывает о пяти основных школах Machine Learning и о том, как они используют идеи из различных областей научного знания — нейробиологии, физики, статистики, биологии, — чтобы помогать людям решать сложные задачи и упрощать рутину с помощью алгоритмов.
Добавляйте в закладки и делитесь с коллегами!
Книги по машинному обучению на русском
1. «Математические основы машинного обучения и прогнозирования» Владимир Вьюгин.
О чем
Сначала изучите азы статистической теории машинного обучения, игр с предсказаниями и прогнозирования с применением экспертной стратегии. Их основы прекрасно объясняет автор книги, доктор физико-математических наук Владимир Вьюгин. Пособие рассчитано на студентов и аспирантов и в доступной форме излагает математические основы, необходимые для дальнейшей работы с машинным обучением.
2. «Верховный алгоритм» Педро Домингос.
О чем
Книга, благодаря которой даже ничего не смыслящие в математике и статистике люди поймут, что такое алгоритмы машинного обучения и каково их применение в жизни. Профессор Педро Домингос рассказывает о пяти основных школах Machine Learning и о том, как они используют идеи из различных областей научного знания — нейробиологии, физики, статистики, биологии, — чтобы помогать людям решать сложные задачи и упрощать рутину с помощью алгоритмов.
REST Assured: что мы узнали за пять лет использования инструмента
8 мин
REST Assured — DSL для тестирования REST-сервисов, который встраивается в тесты на Java. Это решение появилось более девяти лет назад и стало популярным из-за своей простоты и удобного функционала.
В DINS мы написали с ним более 17 тысяч тестов и за пять лет использования столкнулись со множеством «подводных камней», о которых нельзя узнать сразу после импорта библиотеки в проект: статическим контекстом, путаницей в порядке применения фильтров к запросу, трудностями в структурировании теста.
Эта статья — о таких неявных особенностях REST Assured. Их нужно учитывать, если есть шанс, что количество тестов в проекте будет быстро увеличиваться — чтобы потом не пришлось переписывать.

Семь книг для тех, кто хочет стать гейм-дизайнером
11 мин
Перевод

В этой статье рассказывается о том, когда и как дизайн игр стал профессией, а также о том, как он сформировался в отдельную дисциплину. Также мы предложим 7 книг, которые нужно прочитать каждому гейм-дизайнеру. Мы объясним, что особо ценного в этих книгах и как они позволят вам стать профессиональным гейм-дизайнером. Существуют и другие статьи с рекомендациями книг по дизайну игр, но их авторы не указывают конкретный порядок их чтения. Мы перечислили книги в определённом порядке, позволяющем читателю плавно повышать свои навыки гейм-дизайна. Более того, в статье подробно описаны порядок и причины для изучения этих книг.
Эта статья не является маркетингом описываемых материалов, а предоставляет информацию о том, где и чему учиться.
Data Science Digest (August 2019)
4 мин

Приветствую всех! DataFest возвращается в Украину и пройдет 7 сентября в Одессе. Сейчас формируется программа, но если вы хотите выступить с докладом, то можно подать свою тему здесь. Зарегистрироваться в качестве участника можно здесь. Напоминаю, что у дайджеста есть свой Telegram-канал и страницы в соцсетях (Facebook, Twitter, LinkedIn), где я ежедневно публикую ссылки на полезные материалы. Присоединяйтесь!
А пока предлагаю свежую подборку материалов под катом.
Шпаргалка для стажера: пошаговое решение задач на собеседовании Google
3 мин
Перевод
В прошлом году последние пару месяцев я потратил на подготовку к собеседованию для стажировки в Google (Google Internship). Все прошло хорошо: я получил и работу, и отличный опыт.
Теперь, спустя два месяца после стажировки, я хочу поделиться документом, который использовал для подготовки к собеседованиям. Для меня это было чем-то типа шпаргалки перед экзаменом. Но процесс создания документа и постоянная пошаговая проверка по нему помогли мне запомнить все самое важное.
Python Vs R — Data Science
3 мин
Туториал
When mulling over the best programming language to use for data science, Python and R ring a bell (very quickly). While there are a lot of languages like C, C++, Java, Julia, Perl, and Scala, it's protected to state that Python and R are the harbingers in data science.
While a great deal of data researchers will discuss the customary shortcomings like data wrangling in R or data representation in Python, ongoing improvements like Altair for Python or R have adequately reacted to these shortcomings.
So which one would it be a good idea for you to decide for your next data investigation venture?
R has been ruling this space for a long time now. This bodes well as this programming language was explicitly intended for analysts.
While a great deal of data researchers will discuss the customary shortcomings like data wrangling in R or data representation in Python, ongoing improvements like Altair for Python or R have adequately reacted to these shortcomings.
So which one would it be a good idea for you to decide for your next data investigation venture?
R has been ruling this space for a long time now. This bodes well as this programming language was explicitly intended for analysts.
Как стать более востребованным специалистом в сфере Data Science в 2019
4 мин
Заголовок этой статьи может показаться немного странным. И вправду: если вы работаете в сфере Data Science в 2019, вы уже востребованы. Спрос на специалистов в этой области неуклонно растет: на момент написания этой статьи, на LinkedIn размещено 144,527 вакансий с ключевым словом «Data Science».
Тем не менее, следить за последними новостями и трендами в индустрии однозначно стоит. Чтобы помочь вам в этом, мы с командой CV Compiler проанализировали несколько сотен вакансий в сфере Data Science за июнь 2019 и определили, какие навыки ожидают от кандидатов работодатели чаще всего.
Тем не менее, следить за последними новостями и трендами в индустрии однозначно стоит. Чтобы помочь вам в этом, мы с командой CV Compiler проанализировали несколько сотен вакансий в сфере Data Science за июнь 2019 и определили, какие навыки ожидают от кандидатов работодатели чаще всего.
Splunk: Machine learning на новый уровень
4 мин

Чуть больше года назад мы делали обзор на приложение Splunk Machine Learning Toolkit, с помощью которого можно анализировать машинные данные на платформе Splunk, используя различные алгоритмы машинного обучения.
Сегодня мы хотим рассказать о тех обновлениях, которые появились за последний год. Вышло множество новых версий, добавлены различные алгоритмы и визуализации, которые позволят поднять анализ данных в Splunk на новый уровень.