Дано: банк с дата-центром в Москве и множеством филиалов.
В дата-центре стоит куча x86-машин и серьёзная хайэндовая система хранения данных (СХД). В филиалах реализована сеть с центральным сервером или мини-кластером (+ резервным сервером и low-end хранилищем), с дисковой корзиной. Бекап общих данных делается на ленте (и вечером в сейф) или же на другой сервак рядом с первым. Критичные данные (финансовые транзакции, например), асинхронно реплицируются в центр. На сервере работает Exchange, AD, антивирус, файловый сервер и так далее. Есть ещё данные, которые не являются критичными для банковской сети (это не прямые транзакции), но всё ещё очень важны — например, документы. Они не реплицируются, но иногда бекапятся по ночам, когда филиал не работает. Через полчаса после окончания рабочего дня все сессии гасятся, и начинается большое копирование.
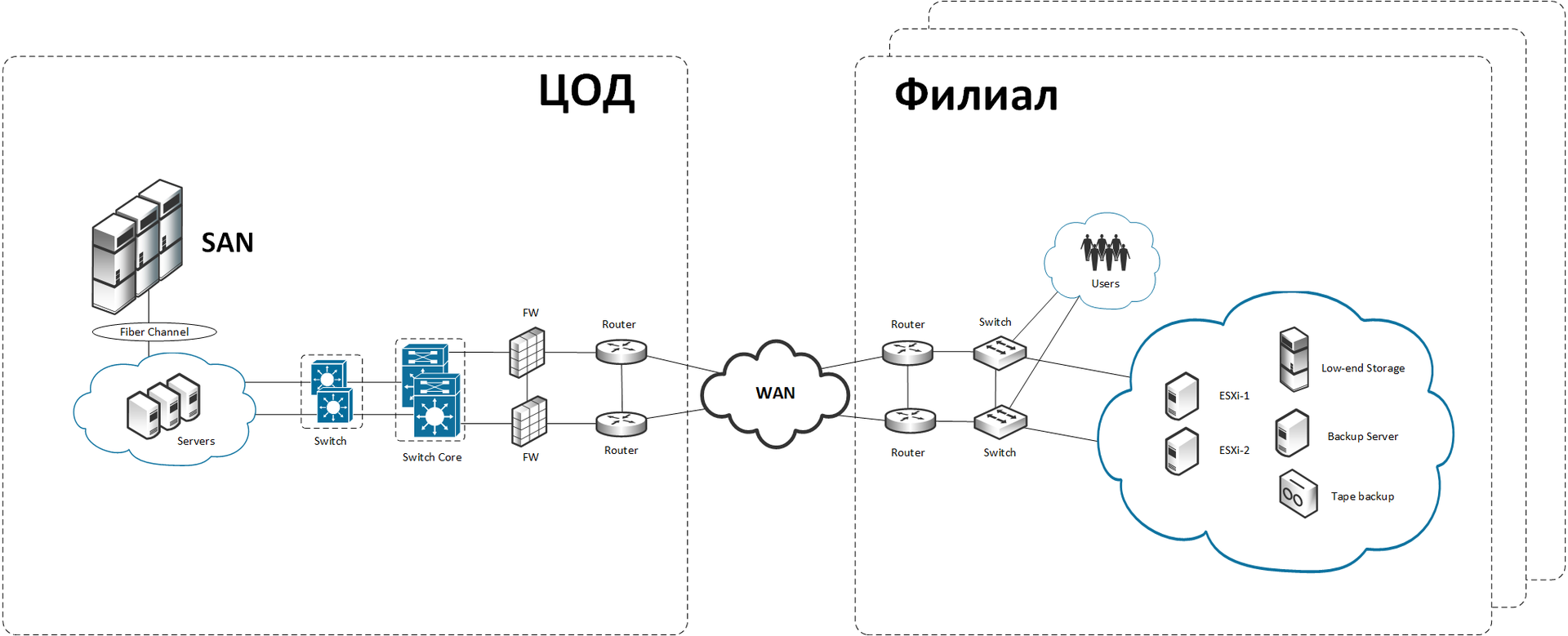
Вот примерно так это было устроено до начала работ
Проблема, конечно, в том, что всё это начинает медленно увеличивать технологический долг. Хорошим решением было бы сделать VDI-доступ (это избавило бы от необходимости держать огромную сервисную команду и сильно облегчило бы администрирование), но VDI требует широких каналов и малых задержек. А это в России не всегда получается элементарно из-за отсутствия магистральной оптики в ряде городов. С каждым месяцем увеличивается количество неприятных «предаварийных» инцидентов, постоянно мешают ограничения железа.
И вот банк решил сделать то, что, вроде бы, дороже по внедрению, если считать напрямую, но сильно упрощает обслуживание серверной инфраструктуры в филиалах и гарантирует сохранность данных филиала: консолидировать все данные в одну центральную СХД. Только не простую, а ещё с умным локальным кэшем.
В дата-центре стоит куча x86-машин и серьёзная хайэндовая система хранения данных (СХД). В филиалах реализована сеть с центральным сервером или мини-кластером (+ резервным сервером и low-end хранилищем), с дисковой корзиной. Бекап общих данных делается на ленте (и вечером в сейф) или же на другой сервак рядом с первым. Критичные данные (финансовые транзакции, например), асинхронно реплицируются в центр. На сервере работает Exchange, AD, антивирус, файловый сервер и так далее. Есть ещё данные, которые не являются критичными для банковской сети (это не прямые транзакции), но всё ещё очень важны — например, документы. Они не реплицируются, но иногда бекапятся по ночам, когда филиал не работает. Через полчаса после окончания рабочего дня все сессии гасятся, и начинается большое копирование.
Вот примерно так это было устроено до начала работ
Проблема, конечно, в том, что всё это начинает медленно увеличивать технологический долг. Хорошим решением было бы сделать VDI-доступ (это избавило бы от необходимости держать огромную сервисную команду и сильно облегчило бы администрирование), но VDI требует широких каналов и малых задержек. А это в России не всегда получается элементарно из-за отсутствия магистральной оптики в ряде городов. С каждым месяцем увеличивается количество неприятных «предаварийных» инцидентов, постоянно мешают ограничения железа.
И вот банк решил сделать то, что, вроде бы, дороже по внедрению, если считать напрямую, но сильно упрощает обслуживание серверной инфраструктуры в филиалах и гарантирует сохранность данных филиала: консолидировать все данные в одну центральную СХД. Только не простую, а ещё с умным локальным кэшем.











 Тема одежды с дополненным функционалом поднималась на Хабре уже несколько раз. Зачастую, такие гаджеты, как
Тема одежды с дополненным функционалом поднималась на Хабре уже несколько раз. Зачастую, такие гаджеты, как