
Стандартная гауссова статистика работает на основе следующих предположений. Центральная предельная теорема утверждает, что при увеличении числа испытаний, предельное распределение случайной системы будет нормальным распределением. События должны быть независимыми и идентично распределены (т.е. не должны влиять друг на друга и должны иметь одинаковую вероятность наступления). При исследовании крупных комплексных систем обычно предполагают гипотезу о нормальности системы, чтобы далее мог быть применен стандартный статистический анализ.
Часто на практике изучаемые системы (от солнечных пятен, среднегодовых значений выпадения осадков и до финансовых рынков, временных рядов экономических показателей) не являются нормально-распределенными или близкими к ней. Для анализа таких систем Херстом [1] был предложен метод Нормированного размаха (RS-анализ). Главным образом данный метод позволяет различить случайный и фрактальный временные ряды, а также делать выводы о наличии непериодических циклов, долговременной памяти и т.д.
Часто на практике изучаемые системы (от солнечных пятен, среднегодовых значений выпадения осадков и до финансовых рынков, временных рядов экономических показателей) не являются нормально-распределенными или близкими к ней. Для анализа таких систем Херстом [1] был предложен метод Нормированного размаха (RS-анализ). Главным образом данный метод позволяет различить случайный и фрактальный временные ряды, а также делать выводы о наличии непериодических циклов, долговременной памяти и т.д.
Алгоритм RS-анализа
- Дан исходный ряд
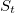 . Рассчитаем логарифмические отношения:
. Рассчитаем логарифмические отношения:
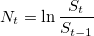
- Разделим ряд
 на
на 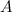 смежных периодов длиной
смежных периодов длиной 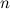 . Отметим каждый период как
. Отметим каждый период как 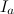 , где
, где 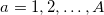 . Определим для каждого среднее значение:
. Определим для каждого среднее значение:
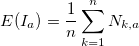
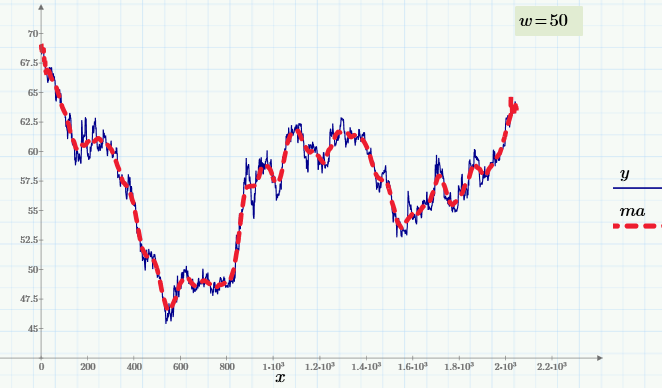





 Разработки Синезис не ограничиваются одной лишь видеоаналитикой. Мы занимаемся и аудиоаналитикой. Вот о ней-то мы и хотели сегодня вам рассказать. Из этой статьи вы узнаете о наиболее известных аудиоаналитических системах, а также алгоритмах и их специфике. В конце материала – традиционно – список источников и полезных ссылок, в том числе аудиобиблиотек.
Разработки Синезис не ограничиваются одной лишь видеоаналитикой. Мы занимаемся и аудиоаналитикой. Вот о ней-то мы и хотели сегодня вам рассказать. Из этой статьи вы узнаете о наиболее известных аудиоаналитических системах, а также алгоритмах и их специфике. В конце материала – традиционно – список источников и полезных ссылок, в том числе аудиобиблиотек.