Spring Framework является одним из самых сложных фремворков для понимания и изучения. Большинство разработчиков изучают его медленно, через практические задачи и гугл. Этот подход не эффективен, так как не даёт полной картины и при этом требует больших затрат.
Я хотел бы предложить вам принципиально новый подход к изучению Спринга. Он заключается в том, что человек проходит через серию специально подготовленных туториалов и самостоятельно реализует функционал спринга. Особенность этого подхода в том, что он, помимо 100%-го понимания изучаемых аспектов Spring даёт ещё большой прирост в Java Core (Annotations, Reflection, Files, Generics).
Статья подарит вам незабываемые ощущения и позволит почувствовать себя разработчиком Pivotal. Шаг за шагом, вы сделаете ваши классы бинами и организуете их жизненный цикл (такой же, как и в реальном спринге). Классы, которые вы будете реализовывать — BeanFactory, Component, Service, BeanPostProcessor, BeanNameAware, BeanFactoryAware, InitializingBean, PostConstruct, PreDestroy, DisposableBean, ApplicationContext, ApplicationListener, ContextClosedEvent.
Всем привет! Меня зовут Лёха, и я работаю бэкенд-разработчиком в FunCorp. Сегодня мы поговорим про реактивное программирование, библиотеку Reactor и немного про веб.
Реактивное программирование часто «подвергается упоминанию», но если вы (как и автор статьи) всё ещё не знаете, что это такое — устраивайтесь поудобнее, попробуем разобраться вместе.
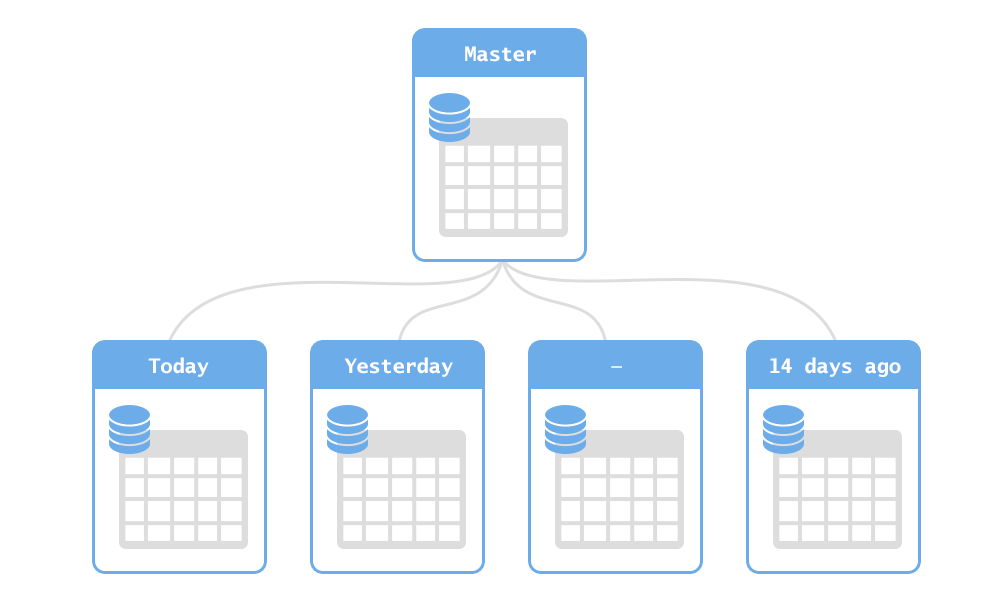
Архитектура большинства Java(и не только) приложений сегодня предусматривает возможность расширения функционала посредством различного рода магических воздействий на код. В последнее время это также стало возможно, если использовать какой-нибудь модный фреймворк или IoC-контейнер. Но что делать, если приложение долгоживущее и слишком сложное для того, чтобы переводить его на использование какого либо фреймворка?
В последнем приложении, с которым я работал, был реализован на тот момент неизвестный мне велосипед SPI механизм, который искал в джарках текстовые файлы вида META-INF/services/<qualified interface name> и брал оттуда название нужного класса, реализующего этот интерфейс, далее этот класс использовался как расширение. Поискав в интернете, узнал, что Service Provider Interface(SPI) представляет собой программный механизм для поддержки сменных компонентов и что этот механизм уже довольно давно используется в Java Runtime Environment(JRE), например в Java Database Connectivity(JDBC):
ps = Service.providers(java.sql.Driver.class);
try {
while (ps.hasNext()) {
ps.next();
}
} catch (Throwable t) {
// Do nothing
}
Благодаря этому коду приложения больше не нуждаются в конструкции Class.forName(<driver class>) (хотя и с ней будут работать), JDBC драйверы будут подгружены автоматически при первом обращении к методам класса DriverManager.
Весь смысл в разделении логики на сервис(Service) и провайдеры(Service Providers). Ссылки на провайдеры сохраняются в джарках расширений в текстовом файле(UTF-8) META-INF/services/<qualified service class>, в каждой строке полное имя класса провайдера. Пустые строки и комментарии(начинающиеся с символа #) игнорируются. Ограничения на провайдеры: они должны реализовывать интерфейс либо наследоваться от класса сервиса и иметь конструктор по умолчанию(zero-argument public constructor).
Данная статья в первую очередь предназначена для подготовки к собеседованиям на позицию Java разработчика (на самом деле, это шпаргалка, которую я писал для себя в течении многих лет, и повторяю при каждом новом поиске работы).
Предполагается. что вы знакомы с многими функциями из Java SE, поэтому в основном информация дается кратко. Конечно, можно использовать эту статью и просто для обучения основам Java SE платформы (но в этом случае, после чтения статьи вам скорее всего придется обратиться к другим источникам).
Итак, вы пытаетесь вспомнить все, что знаете перед собеседованием и не важно сколько лет опыта, без подготовки вас все равно могут поймать на том вопросе, который вы вроде бы помнили, но именно на собеседовании забыли. Это шпаргалка позволит вам освежить некоторые из ваших знаний.
Внимание: я не буду касаться вопросов по самому языку Java (вроде для чего нужно слово final или чем overriding отличается от overloading), это потребует отдельной статьи, это вопросы именно по Java SE (6-9) платформе.
В одной из классических статей для новичков, мелькавших недавно на Хабре, рассказывалось про создание базового Web приложения на Java. Все начиналось с сервлета, потом создания JSP страницы и, наконец, деплоймента в контейнер. Посмотрев на это свежим взглядом я понял, что для как раз для новичков это, наверняка, выглядит совершенно жутко — на фоне простых и понятных PHP или Node.js, где все просто — написал контроллер, вернул объект, он стал JSON или HTML. Чтобы немного развеять это ощущение, я решил написать "Гайд для новичков в Spring". Цель это статьи — показать, что создание Web приложений на Java, более того — на Spring Framework это не боль и мучительное продирание через web.xml, persistence.xml, beans.xml, и собирание приложения как карточного домика по кусочкам, а вполне себе быстрый и комфортный процесс. Аудитория — начинающие разработчики, разработчики на других языках, ну и те, кто видел Спринг в его не самые лучше времена.
Также я веду курс «Scala for Java Developers» на платформе для онлайн-образования udemy.com (аналог Coursera/EdX).
В следствии этого у меня скопилось значительно количество ссылок на видео на русском языке по Java как моего авторства, так и моих коллег.
(GolovachCourses.com)
Здесь собраны несколько вариантов записи моего курса Java Core. Модуль #1 (Procedural Java):
Набор июль 2013: #1, #2, #3, #4
Набор апрель 2013: #1, #2, #3, #4
Набор февраль 2013: #1, #2, #3, #4
Набор январь 2013: #1, #2, #3, #4
Набор октябрь 2012: #1, #2, #3, #4.
Приветствую тебя — Человек жаждущий знаний!
Хочу поделится с тобой своим небольшими но думаю полезным для многих знаниями по Kotlin в виде небольшой серии видео.
Планета Марс уже не первый год населена роботами. То тут, то там появляются беспилотные электрокары и летающие дроны, а в программах, написанных на Java, с завидной регулярностью всплывают проблемы с кодировками.
Хочу поделиться своими мыслями о том, почему это происходит.
Привет, Хабр. В этой статье я кратко расскажу о деталях реализации микросервисной архитектуры с использованием инструментов, которые предоставляет Spring Cloud на примере простого концепт-пруф приложения.
Код доступен для ознакомления на гитхабе. Образы опубликованы на докерхабе, весь зоопарк стартует одной командой.
В последнее время интерес к облачным архитектурам растет с каждым днем, так как это один из наиболее эффективных способов масштабировать приложение, не прикладывая больших усилий, а самым узким местом любого высоконагруженного проекта является хранилище данных, в частности реляционная БД. Для борьбы с недостатками традиционных БД в основном используется 2 подхода:
1) Кэширование результатов выполнения запросов
плюсы: высокая скорость доступа к данным
минусы: требует компромисса между актуальностью данных и скоростью доступа, т.к. данные в кэше могут устареть, а удалять старые данные из кэша с последующим кэшированием новых — это дополнительные задержки и нагрузка на систему
2) NoSQL решения
плюсы: хорошая горизонтальная масштабируемость, доменная модель данных совпадает с моделью хранения данных
минусы: низкая скорость получения результатов в случае использования диска, практически невозможно обеспечить работу внутрикорпоративного софта, который ориентирован на работу с конкретной реляционной БД.
Сегодня я хочу познакомить вас с таким типом хранилища данных, который объединяет достоинства обоих подходов и при этом имеет ряд преимуществ перед упомянутыми выше решениями: In-memory-data-grid (IMDG).
Год подходит к концу, впереди длинные каникулы. Для многих каникулы — это отличная возможность посидеть и посмотреть вокруг, что же у нас нового и интересного происходит нынче в профессиональном джавовском мире.
В апреле в Москве мы провели в Москве большую Java-конференцию — JPoint 2015. Конференция собрала более тысячи разработчиков на площадке, еще несколько сотен — смотрели конференцию онлайн. Мы экспериментировали и с открытием (лекция Дмитрия Галкина о современном искусстве и программировании действительно шокировала многих) и с новыми форматами (круглые столы и экспертные дискуссии). Но ключевой темой конференции были и остаются доклады.
Видеозаписи всех докладов конференции лежат на Youtube. Мы, как всегда, собрали статистику из отзывов участников и посчитали рейтинг докладов. В этом посте — традиционный обзор лучших докладов конференции. Я сделаю короткий обзор десяти лучших докладов конференции с тем, чтобы вы немного больше знали о них и посмотрели именно то, что интересно вам.
Итак, поехали.
10 место
Сергей Walrus Куксенко, Oracle — Железные счётчики на страже производительности
Средняя оценка: 4.28
Этот доклад получил специальный приз жюри в номинации «аццкий хардкор». Общая идея доклада сводится к следующему: представьте, что вы уже наоптимизировали в своем приложении все, что можно — посмотрели на сеть, ОС, JVM и т.д. и поняли, что все уперлось в процессор. После этого мы попрофилировали, работать стало быстрее, но все равно процессор загружен на 100%. Что делать?
Оказывается, внутри процессора есть разные счетчики событий. Называется этот механизм Hardware Performance Counters. Архитектура современных процессоров очень сложна, в них может происходить очень много разного. Фокус в том, что мы можем включить некоторые счетчики внутри процессора, которые будут считать количество произошедших событий. То есть, некоторый железный профилировщик внутри процессора.
Какие именно события умеет считать этот процессорный профилировщик? Да практически любые. В современных интеловских процессорах, по утверждению Сергея, их около тысячи. Если вы хотите понять, какие события надо смотреть в первую очередь, куда вообще копать и какие с этим возникают трудности — обязательно посмотрите этот доклад.
В этом году Сергей снова прилетит к нам в Москву — правда уже не из Питера, а из Калифорнии. С темой он определится в январе. Скорее всего это будет снова что-то про оптимизацию производительности.
Функцией партиционирования таблиц в PostgreSQL, к сожалению, активно пользуются пока не многие. На мой взгляд, очень достойно о ней рассказывает в своей работе Hubert Lubaczewski (depesz.com). Предлагаю вам еще один перевод его статьи!
В последнее время я заметил, что всё чаще и чаще сталкиваюсь с кейсами, где можно было бы использовать партиционирование. И хотя, теоретически, большинство людей знает о его существовании, на самом деле эту фичу не слишком хорошо понимают, а некоторые её даже побаиваются.
Так что я постараюсь объяснить в меру своих знаний и возможностей, что это такое, зачем его стоит использовать и как это сделать.
Представляю на ваш суд ещё один перевод коанов о Мастере Фу на русский язык. В данный сборник вошли все коаны, на данный момент опубликованные на сайте Эрика Реймонда. Надо сказать, что сам Эрик личность весьма неординарная, но упоминания в данной статье стоящая. Помимо холиваров в списках рассылки всевозможных проектов за его авторством также несколько серьёзных трудов о Unix — в том числе и о сообществе, без которого экосистема современных открытых проектов не была бы возможной (полный список книг). Идея перевести коаны в очередной раз пришла мне в голову во время чтения одного из таких трудов, а именно «The Art of Unix Programming», поскольку многое из скрытого смысла коанов становится ясно только после прочтения очередной главы оттуда.
Ну и конечно же, дисклеймер: все комментарии и специфика переложения есть плод воображения вашего покорного слуги.
Я публикую этот перевод в надежде на то, что он может кому-то понравиться, но не предоставляю на него никаких гарантий, в том числе соответствия канонам перевода или пригодности для цитирования где бы то ни было.
Из опыта code-review и ответов на StackOverflow набралось немало моментов, касающихся Java Collections API, которые мне казались очевидными, но другие разработчики о них почему-то не знали или знали, но не чувствовали уверенности их применять. В этой статье я собираю в общую кучу всё, что накопилось.
Содержание:
List.subList
PriorityQueue
EnumSet и EnumMap
Set.add(E) и Set.remove(E) возвращают булево значение
Map.put(K, V), Map.remove(K), List.set(idx, E), List.remove(idx) возвращают предыдущий элемент
На днях вышел новый стабильный релиз mongodb. В этой версии был добавлен ряд нововведений таких как новый GUI для визуальной работы с mongodb, LEFT JOIN, валидация документа и т.д. некоторые из этих свойств мы и рассмотрим на небольших примерах ниже.
Так уж случилось, что с этого семестра в своем вузе я записался на спецкурс по паттернам проектирования. Курс проходит в виде семинаров, на которых ты (студент) должен рассказать чему научился за неделю (имеется ввиду, какие паттерны изучил и применил на практике).
Хотел бы преподнести на суд общественности перевод одной чудесной статьи, в которой описаны базовые принципы программирования. Пару слов о том — зачем собственно это все и кому это надо? Отвечаю — последние несколько месяцев я, сам начинающий программист, активно пытаюсь обучать ребят из других сфер. В этом нелегком труде мне приходится шерстить интернет в поисках в первую очередь интересных материалов, чтобы разбить их стереотипы насчет того что код — это скучно и нудно. К моему глубокому сожалению, таких материалов не так уж много. Я уверен, есть огромное количество новичков, которые регулярно читают хабр и эта статья будет им крайне интересна и полезна.
Традиционно рекомендации по обучению десятипальцевой печати сводятся к двум советам:
тратить нервы на клавиатурные тренажеры вроде пресловутого «Соло на клавиатуре»;
заклеить подписи на клавишах.
Научиться печатать на клавиатуре вслепую при помощи этих способов — издевательство над собой. Каждый, кто пробовал «Соло», хотя бы раз в ярости бил по клавиатуре кулаком, и практически никто не дошел до конца. А кто пробовал заклеивать надписи на клавишах, вскоре отрывал наклейки обратно, потому что без навыка и без подписей печатать невозможно, а жить дальше как-то надо.
Что если я скажу вам, что есть абсурдно простой, состоящий из одного пункта способ научиться слепой печати без этих дурацких органичений?