Обзор техник реализации игрового ИИ
55 мин
Перевод
Введение
Эта статья познакомит вас с широким диапазоном концепций искусственного интеллекта в играх («игрового ИИ»), чтобы вы понимали, какие инструменты можно использовать для решения задач ИИ, как они работают совместно и с чего можно начать их реализацию в выбранном движке.
Я буду предполагать, что вы знакомы с видеоиграми, немного разбираетесь в таких математических концепциях, как геометрия, тригонометрия и т.д. Большинство примеров кода будет записано псевдокодом, поэтому вам не потребуется знание какого-то конкретного языка.
Что же такое «игровой ИИ»?
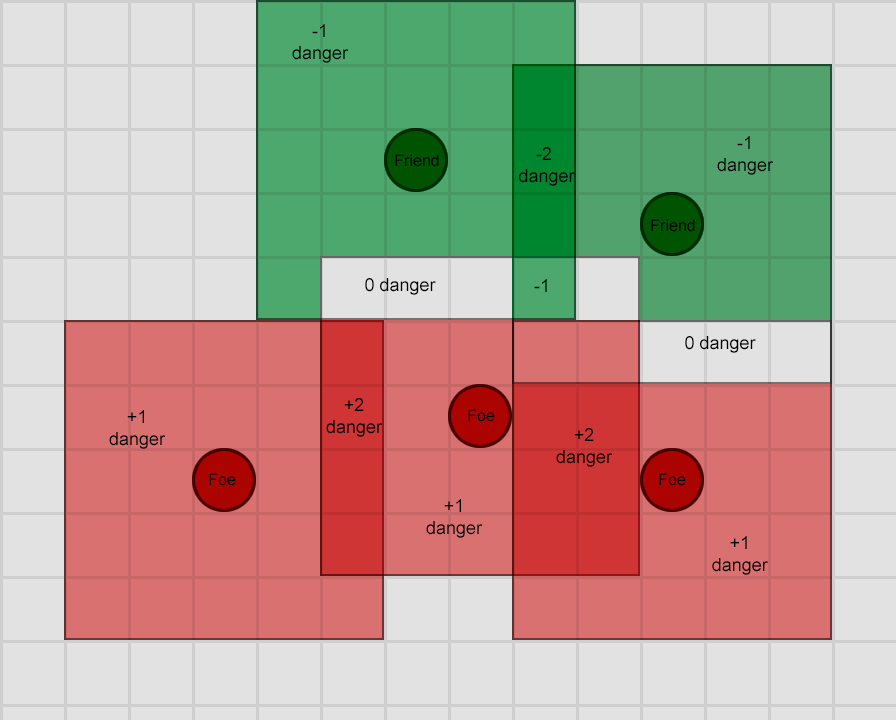
Игровой ИИ в основном занимается выбором действий сущности в зависимости от текущих условий. В традиционной литературе по ИИ называет это управлением "интеллектуальными агентами". Агентом обычно является персонаж игры, но это может быть и машина, робот или даже нечто более абстрактное — целая группа сущностей, страна или цивилизация. В любом случае это объект, следящий за своим окружением, принимающий на основании него решения и действующий в соответствии с этими решениями. Иногда это называют циклом «восприятие-мышление-действие» (Sense/Think/Act):
- Восприятие: агент распознаёт — или ему сообщают — информацию об окружении, которая может влиять на его поведение (например, находящиеся поблизости опасности, собираемые предметы, важные точки и так далее)
- Мышление: агент принимает решение о том, как поступить в ответ (например, решает, достаточно ли безопасно собрать предметы, стоит ли ему сражаться или лучше сначала спрятаться)
- Действие: агент выполняет действия для реализации своих решений (например, начинает двигаться по маршруту к врагу или к предмету, и так далее)
- … затем из-за действий персонажей ситуация изменяется, поэтому цикл должен повториться с новыми данными.













 Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.
Здравствуйте, коллеги. Рассмотрим обычный онлайн-эксперимент в некоторой компании «Усы и когти». У неё есть веб-сайт, на котором есть красная кнопка в форме прямоугольника с закругленными краями. Если пользователь нажимает на эту кнопку, то где-то в мире мурлычет от радости один котенок. Задача компании — максимизация мурлыкания. Также есть отдел маркетинга, который усердно исследует формы кнопок и то, как они влияют на конверсию показов в клико-мурлыкания. Потратив почти весь бюджет компании на уникальные исследования, отдел маркетинга разделился на четыре противоборствующие группировоки. У каждой группировки есть своя гениальная идея того, как должна выглядеть кнопка. В целом никто не против формы кнопки, но красный цвет раздражает всех маркетологов, и в итоге было предложено четыре альтернативных варианта. На самом деле, даже не так важно, какие именно это варианты, нас интересует тот вариант, который максимизирует мурлыкания. Маркетинг предлагает провести A/B/n-тест, но мы не согласны: и так на эти сомнительные исследования спущено денег немерено. Попробуем осчастливить как можно больше котят и сэкономить на трафике. Для оптимизации трафика, пущенного на тесты, мы будем использовать шайку многоруких байесовских бандитов (bayesian multi-armed bandits). Вперед.