С тех пор как врачи наших клиник начали публиковаться на Хабре, мы узнали много новых слов и успели разгадать главную загадку «злобных» пациентов-айтишников, невероятно расстраивающую врачей. Ну и узнать чуть больше про характерные
«зубы айтишника», про которые так красочно рассказывал мой коллега больше года назад.
Про зубы, очень коротко: множество проблем можно убрать тем, что вы разберётесь, что такое зубной камень, как он образуется и на что влияет. Ниже я расскажу подробнее, в чём дело, это потребует некоторых объяснений принципов образования налёта и камня.
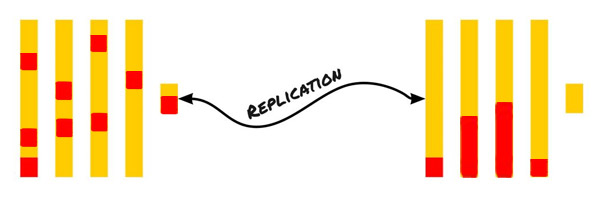
Зубной налёт по консистенции похож на крем. Одна из его составляющих — погибшие бактериальные клетки. В ротовой полости живёт достаточно флоры. Можно сказать, это наши симбионты, в частности, защищающие нас от чего-то гораздо более опасного. Когда экзогенная бактерия попадает к нам в рот, ещё до того, как она соприкоснётся с первыми компонентами иммунитета слизистой и познакомится поближе с лимфоцитами пониже, её встретят бактерии, которые считают нас своим домом. И в жёсткой конкурентной борьбе попытаются её победить.
До слизистой по факту доходит очень мало кто из захватчиков, но не потому, что бактерии нормофлоры хотят нас защитить, а потому что они ведут себя как криминальная «крыша», не пускающая чужаков. «Это наша корова, и мы её доим» — аналог последнего, что слышат случайные колонизаторы.
Погибает и сама нормофлора. Если соседи не успевают растащить остатки на ресурсы, то это всё начинает болтаться у нас во рту, пока не соединится ещё с чем-нибудь. И пока к этому не добавятся укрепляющие минералы, которыми так богата наша слюна, с помощью которой организм старается восстановить эмаль зубов.
Давайте разбираться, что происходит дальше. Почему основное количество камня на нижних шести зубах?