В обучении с подкреплением (Reinforcement Learning) одним из ограничивающих факторов является быстродействие физических симуляторов, на основе которых происходит обучение нейросети. Из-за специфики расчетов, лишь малую часть из них можно вынести в GPU, а большая часть вычислений в физических движках делается на CPU. Для примера, один GPU может обучать нейросеть десятками тысяч параллельных "потоков" в секунду. Но один CPU с запущенным на нем физическим симулятором, может выдавать лишь 60-200 кадров в секунду.
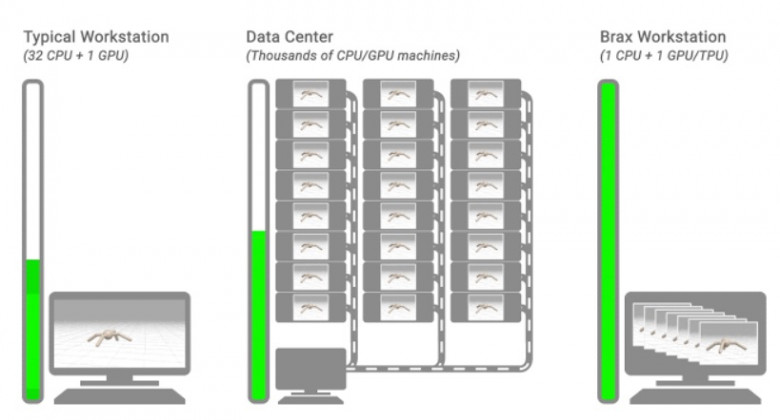
Для борьбы с этим ограничением, обычно запускается большой кластер из сотен или тысяч CPU с запущенными на них параллельными физическими симуляторами. А результаты их расчета передаются в единственную GPU, обучающую нейросеть.
Исследователи из Google AI разработали новый физический движок Brax, который эффективно работает на одном GPU и способен выдавать до 10 миллионов шагов симуляции в секунду, выполняя при этом до 10 тысяч запущенных параллельных симуляторов физики.
Это позволяет эффективно обучать нейросети на одном или нескольких локальных GPU, что раньше требовало внешнего сетевого кластера из десятков тысяч CPU.