Привет, Хабр! В этой статье мы, команда Sber AI, расскажем о пайплайне для распознавания текста и о нюансах обучения HTR‑моделей, а также поделимся датасетом школьных обезличенных тетрадей. Это почти 2 тысячи страниц с полной разметкой полигонов слов (более 300 тысяч текстов). Если нужно, то датасет есть в открытом доступе на hugging face.
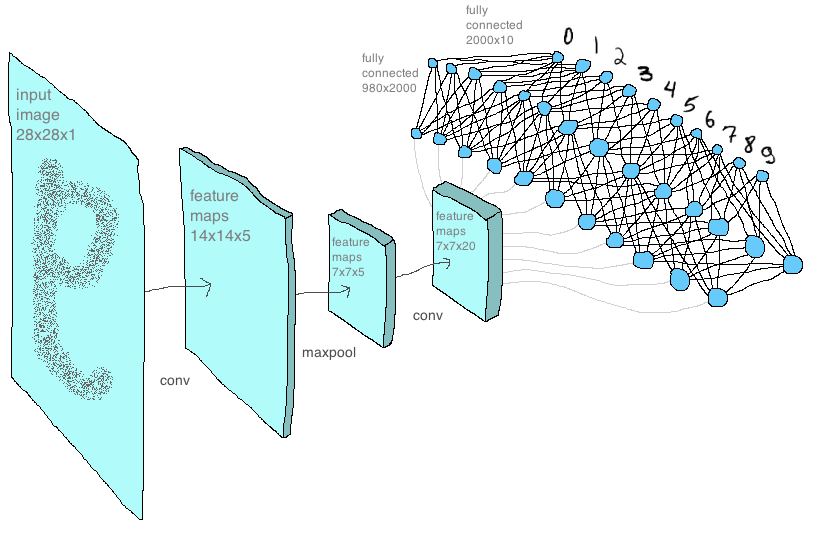
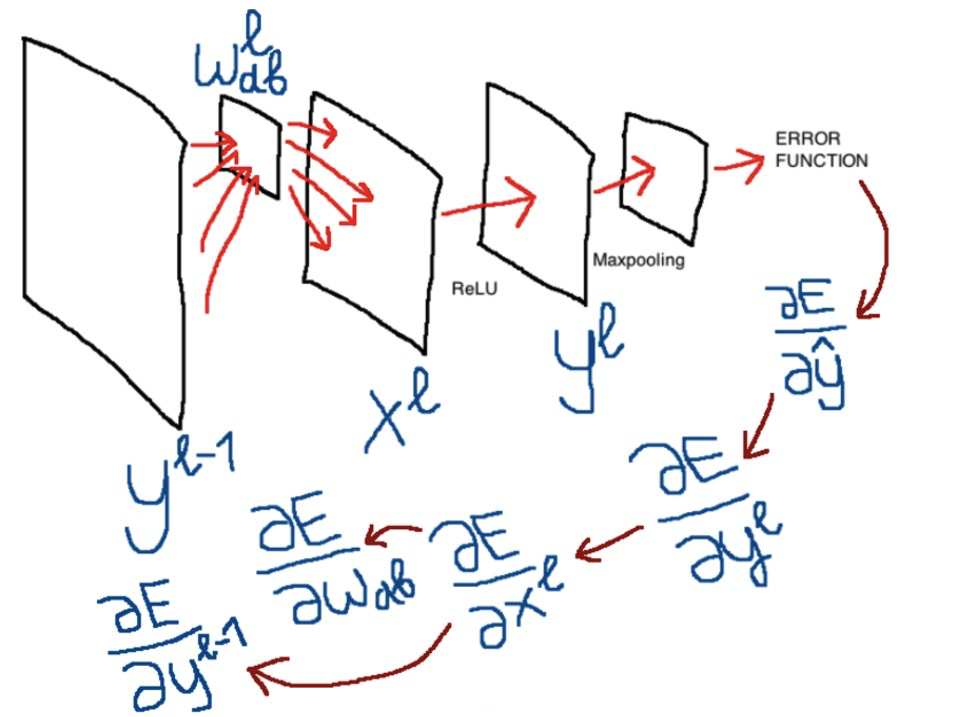
Мы в Sber AI в рамках одного из наших направлений занимаемся распознаванием рукописного текста. В частности наша команда написала пайплайн для более удобного и быстрого проведения экспериментов под разные датасеты. Он состоит из двух модулей — (1) детекция слов и (2) чтение слов. К этому ещё можно добавить этап извлечения связного текста — объединение слов в предложения и страницы. Сложность HTR задачи (handwritten text recognition) в том, что рукопись каждого человека уникальна, на неё влияет множество факторов, включая возраст и настроение. Модель чтения печатного текста можно ускорить добавлением синтетики на основе печати простыми шрифтами на фонах. А вот с HTR‑моделью это не даст такой сильный прирост, так что лучше воспользоваться синтетической рукопиской от GAN.
Отметим, что интересные задачи возникают и в модели для детекции рукописного текста. В таких данных текст, как правило, «прыгает» по странице, каждое слово под своим углом. Некоторые слова накладываются друг на друга, а строка может изгибаться, чтобы она поместилась на одной странице. Есть нюансы и при объединении двух моделей, например, нюансы даунгрейда качества чтения текста при объединении с детекцией (ошибки двух моделей мешают друг другу).