
Или, точнее, задача, поскольку в этом году мы попробовали другой формат: задача была всего одна, но большая. Требовалось написать SQL-запрос, играющий в крестики-нолики «пять в ряд».

Пользователь
Или, точнее, задача, поскольку в этом году мы попробовали другой формат: задача была всего одна, но большая. Требовалось написать SQL-запрос, играющий в крестики-нолики «пять в ряд».

Вдохновившись прошлогодним опытом, мы продолжили начинание и снова проводим конкурс по SQL на международной олимпиаде «IT-Планета».
Конкурс состоит из трех этапов. Заочный теоретический тест собрал почти 3000 человек, из которых на следующий этап мы отобрали примерно 200. Вопросы для этого этапа были подготовлены моим коллегой, Евгением Давыдовым.
Второй этап — также заочный. Здесь участником было предложено подумать над пятью задачами моего авторства, о которых я сегодня и хочу рассказать.
Третий — очный — этап пройдет в конце мая; постараюсь не затягивать с отчетом, но пока храню интригующее молчание.
Поскольку все вводные слова про мотивацию я уже сказал в прошлый раз, сразу приступим к делу.

В шахматы меня когда-то легко обыгрывал восьмибитный компьютер, а действующего чемпиона мира IBM-овский Deep Blue одолел уже в 1997 году. Но игра Го держалась значительно дольше: победить обладателя девятого дана Ли Седоля удалось только в 2016 году компании Гугл с машиной AlphaGo. В Го простые правила, которые, однако, приводят к очень сложным стратегическим построениям. Ровно то, что нужно: простое условие, не дающее намека на то, как справиться с задачей одним SQL-запросом. Тема Го и легла в основу задач финала олимпиады, про которую я уже начал рассказывать в прошлый раз.
Финал проходил в Сочинском государственном университете. Пользуясь случаем, хочу сказать спасибо гостеприимным сотрудникам университета и организаторам, оперативно устранявшим все трудности.

В этом году наша компания впервые провела конкурс по базам данных в рамках международной олимпиады IT-Планета по информационным технологиям. Раньше на олимпиаде использовалась СУБД Oracle; наш коллега Евгений Бредня в свое время делился таким опытом.
Олимпиада проходила в три этапа. Первым шел заочный теоретический тест, который преодолели примерно двести человек из двух тысяч зарегистрировавшихся.
На втором этапе участникам было предложено подумать над пятью задачами, каждую из которых следовало решить одним SQL-запросом. Этот этап также проводился заочно: на раздумья было дано примерно три недели. Условия всех задач были опубликованы одновременно, но у каждой был свой крайний срок; поэтому первыми шли задачи полегче, чтобы на более сложные осталось больше времени. Задачи проверялись на корректность (автоматическими тестами) и на качество кода (вручную). По результатам мы отобрали двадцать человек для последнего, очного этапа.
Третий этап состоялся 27 мая в Сочи. К сожалению, из двадцати приглашенных приехать смогли только четырнадцать; между ними и состоялось соревнование. Задачи этого этапа также предполагали решение одним запросом, но сами задания были объединены общей темой, навеянной игрой Го, и строились так, что решение одной задачи помогало подступиться к следующей.
Я занимался придумыванием задач для второго и третьего этапов. Хочу поблагодарить участников олимпиады, которым пришлось их решать, организаторов, собравших нас вместе, и своих коллег: Дарью Рисухину, взвалившую на себя все оргвопросы, Евгения Моргунова, предоставившего задания для первого этапа, а также всех помогавших мне с задачами.
В предыдущих статьях я писал про этапы выполнения запросов, про статистику, про два основных вида доступа к данным — последовательное сканирование и индексное сканирование, — и успел рассказать о двух способах соединения — вложенном цикле и соединении хешированием.
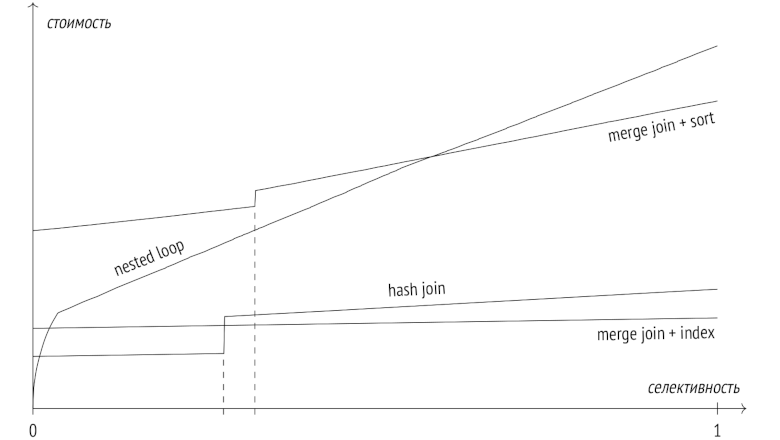
В заключительной статье этой серии я расскажу про алгоритм слияния и про сортировку, и сравню все три алгоритма соединения между собой.
В предыдущих статьях я рассказал про этапы выполнения запросов, про статистику, про два основных вида доступа к данным — последовательное сканирование и индексное сканирование, — и перешел к способам соединения.
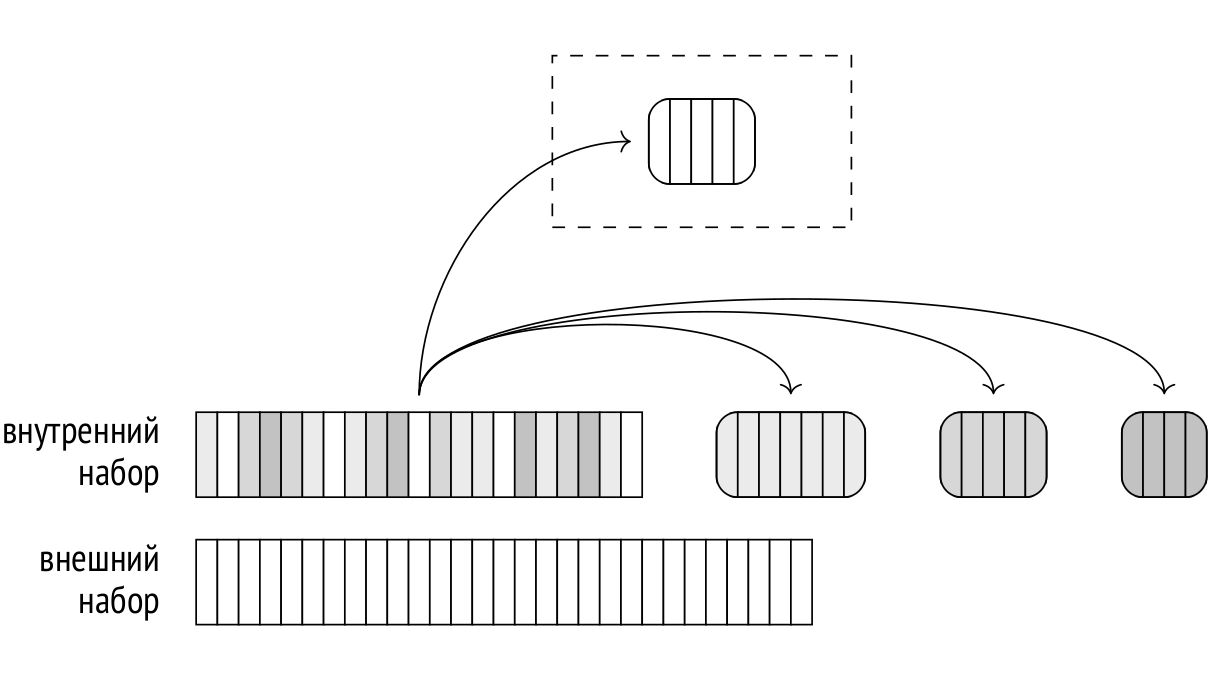
Прошлая статья была посвящена вложенному циклу, а сегодня поговорим про соединение хешированием. Заодно затронем группировку и поиск уникальных значений.
Я уже рассказал об этапах выполнения запросов и о статистике, и о двух основных видах доступа к данным: о последовательном сканировании и об индексном сканировании.
Настал черед способов соединения. В этой статье я кратко напомню, какие бывают логические типы соединений, и расскажу о первом из трех физических способов соединения — о вложенном цикле. Заодно посмотрим и на новую для 14-й версии мемоизацию строк.
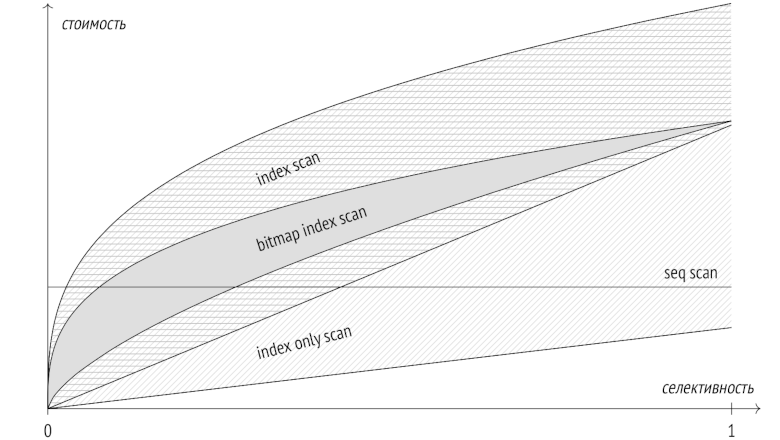
Я уже рассказал об этапах выполнения запросов и о статистике и перешел к способам доступа к данным. В прошлый раз темой статьи было последовательное сканирование, а сегодня поговорим о сканировании индексном.
Прежде чем погружаться в детали индексного доступа, надо было бы рассказать про интерфейс индексных методов. Но я это уже делал в статье про индексы, и, хотя та серия несколько устарела, повторяться не буду. Если слова «класс операторов» и «свойства методов доступа» не находят отклика в душе, статью лучше перечитать.
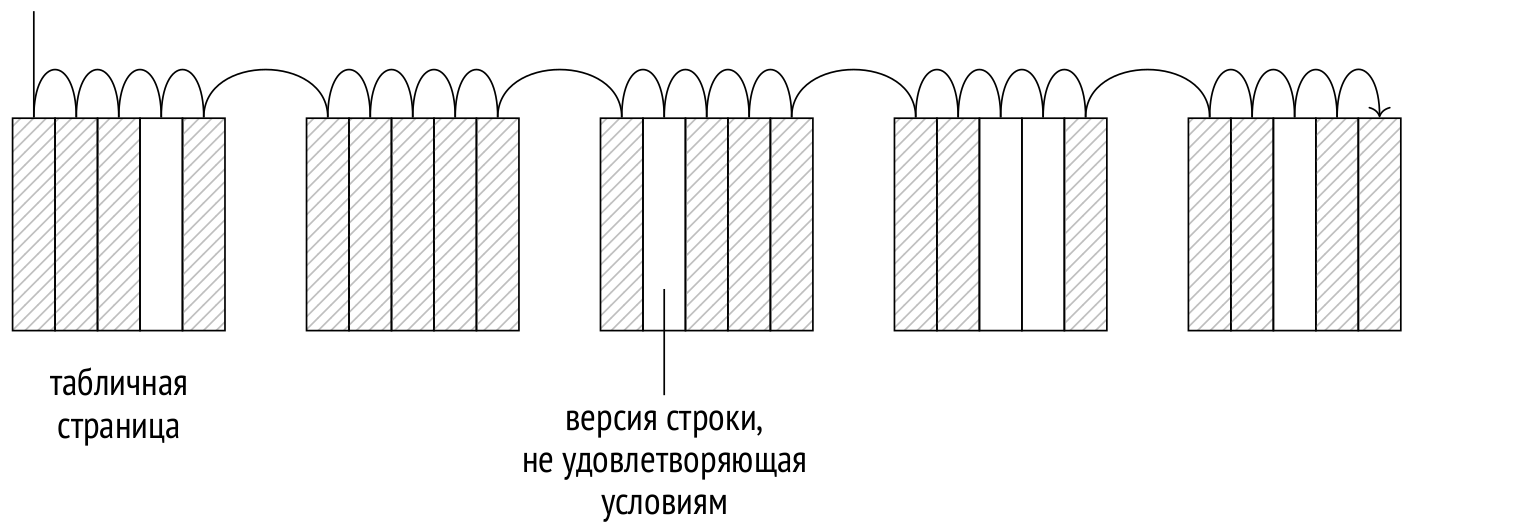
В предыдущих статьях я рассказал об этапах выполнения запросов и о статистике.
Теперь пришла пора рассмотреть самые важные узлы, из которых может состоять план. Я начну со способов доступа к данным, и в этой статье расскажу о последовательном сканировании.
В прошлый раз я показывал, как на основе статистики вычисляется кардинальность, а в этой и следующих буду демонстрировать, как рассчитывается стоимость узлов плана. Не то, чтобы конкретные формулы оценки имели большое значение для понимания деталей работы планировщика, но мне хочется показать, что все цифры выводятся из статистики без привлечения черной магии.
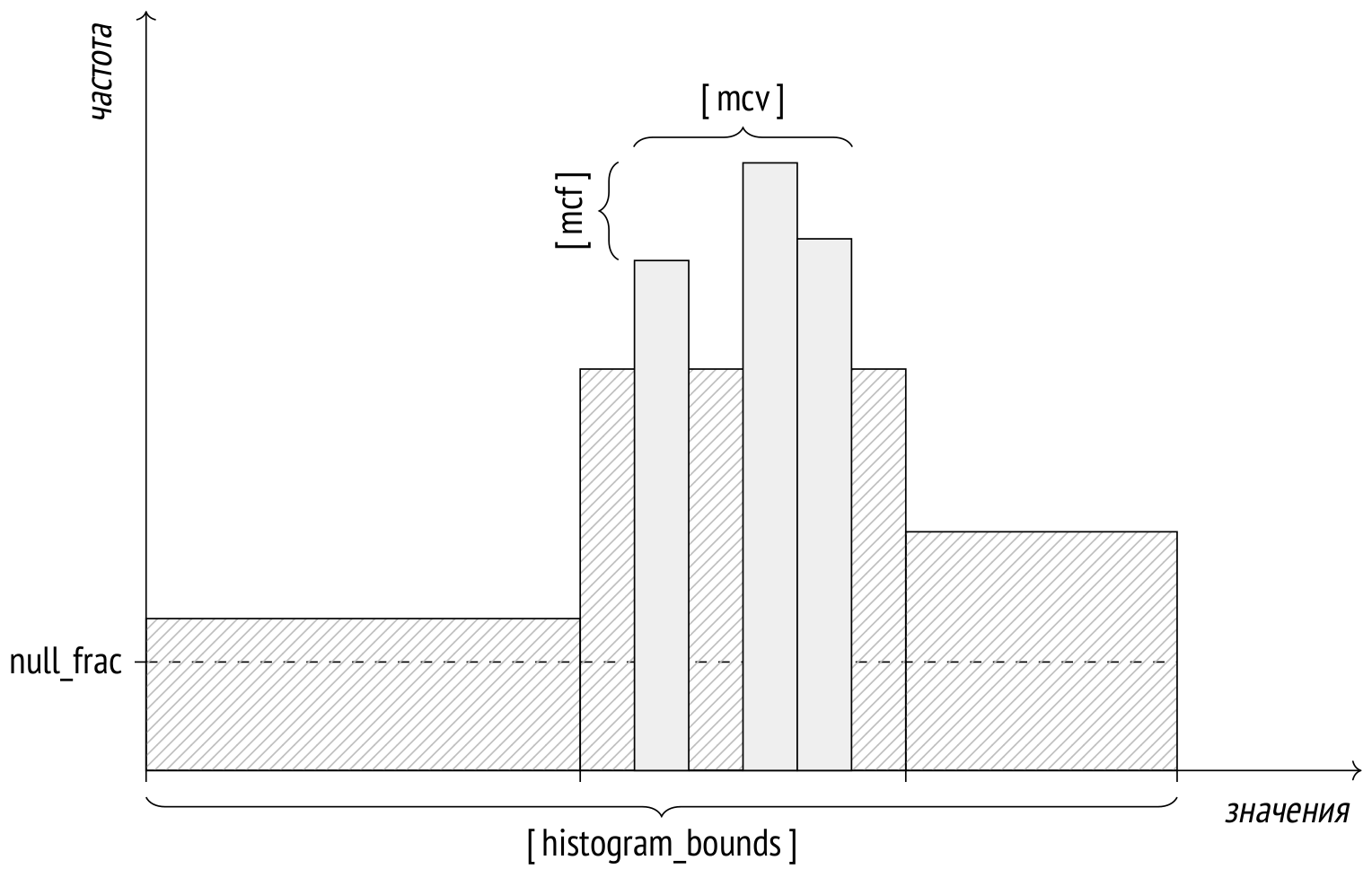
В прошлый раз я рассказал об этапах выполнения запросов. Прежде чем переходить к тому, как работают различные узлы плана (способы доступа к данным и методы соединения), надо разобраться с той основой, на которую опирается стоимостной оптимизатор — со статистикой.
Как обычно, я буду приводить примеры из демобазы. В этой статье будет довольно много планов выполнения, но про их составные части я буду рассказывать только в следующих статьях. Здесь же нас в первую очередь будут интересовать оценки количества строк (кардинальности), то есть числа, указанные в верхней строке плана в позиции rows.
Привет, Хабр! Начинаю еще один цикл статей об устройстве PostgreSQL, на этот раз о том, как планируются и выполняются запросы.
Предыдущие циклы были посвящены изоляции и многоверсионности, журналированию и блокировкам.
В этом цикле я собираюсь рассмотреть этапы выполнения запросов, статистику, последовательное сканирование, индексное сканирование, соединение вложенным циклом, соединение хешированием, сортировку и соединение слиянием.
Материал перекликается с нашим учебным курсом QPT «Оптимизация запросов», но ограничивается только подробностями внутреннего устройства и не затрагивает оптимизацию как таковую. Кроме того, я ориентируюсь на еще не вышедшую версию PostgreSQL 14. А курс мы тоже скоро обновим (правда, на версию 13; приходится бежать со всех ног, чтобы только оставаться на месте).
Использование специальных инструментов не по назначению часто вызывает негатив со стороны профессионалов. Однако решение бессмысленных, но интересных задач тренирует нестандартное мышление и позволяет изучить инструмент с разных точек зрения в поиске подходящего решения.
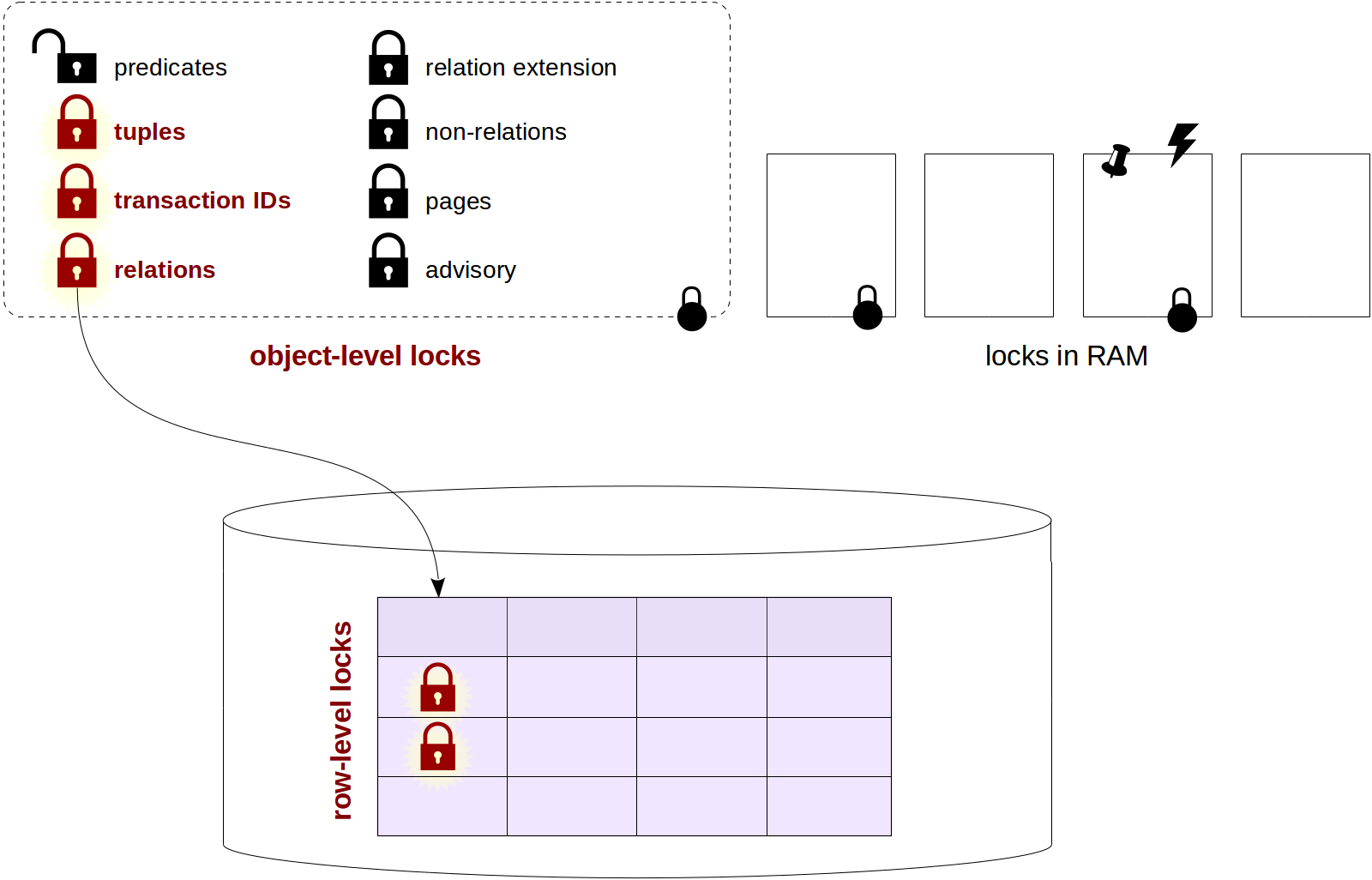
Many thanks to Elena Indrupskaya for the translation of these articles into English.
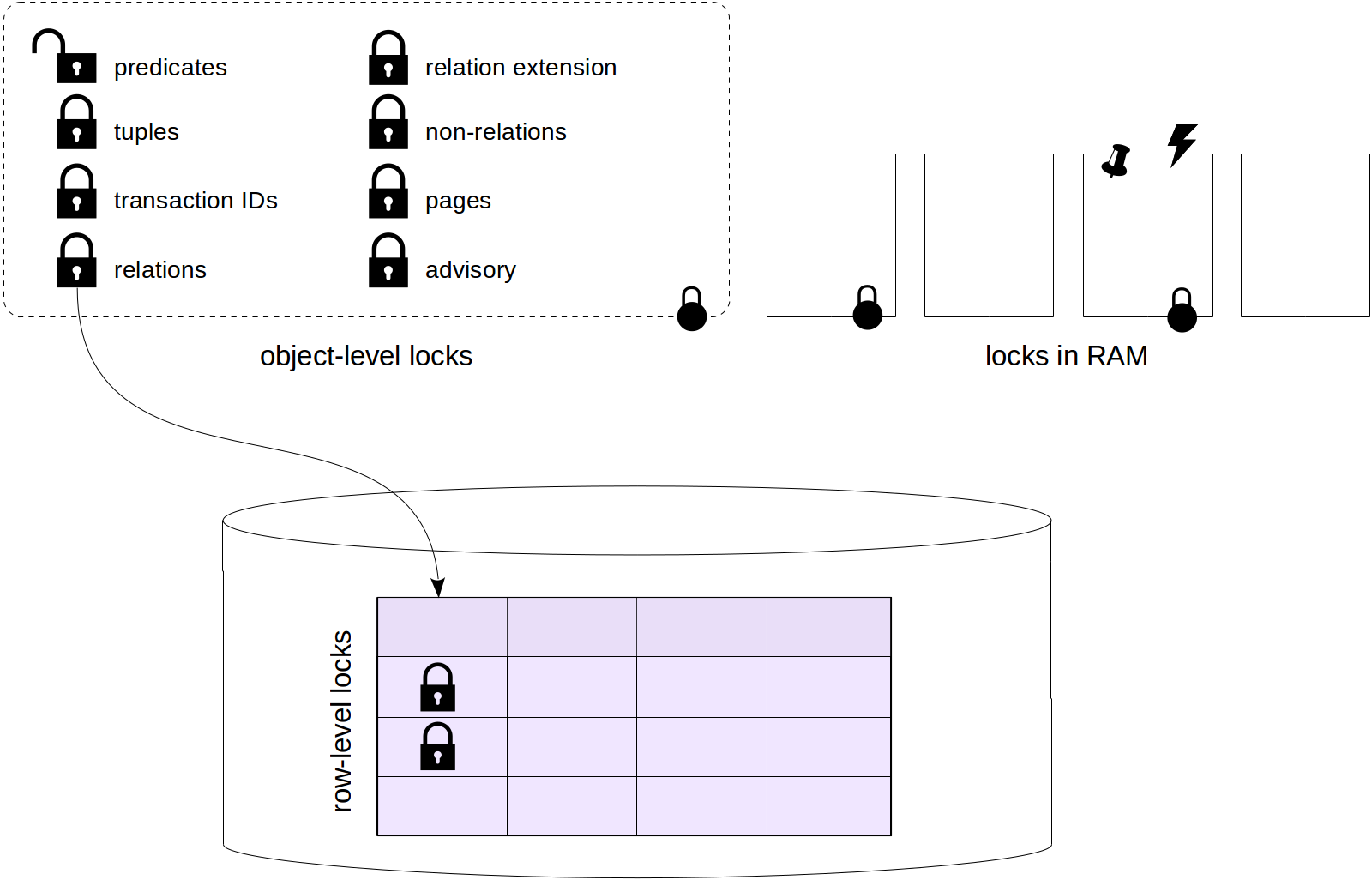
Many thanks to Elena Indrupskaya for the translation of these articles into English.