Привет, это снова Максим Рябинин, исследователь в Yandex Research. В прошлом году я рассказывал на Хабре о том, как вместе с Hugging Face, Университетом Торонто и волонтёрами мы обучили state-of-the-art модель для бенгальского языка и написали об этом статью на конференцию NeurIPS. Теперь хотим поделиться новым результатом: оказывается, технологии для обучения на нестабильном железе находят приложение и внутри привычных всем кластеров.
Используя вычислительную платформу Яндекса, мы обучили RuLeanALBERT — нейросеть, показывающую сравнимые с другими открытыми моделями и где-то даже близкие к state-of-the-art результаты на бенчмарках по пониманию русского языка — Russian SuperGLUE и RuCoLA. Наша модель хотя и имеет миллиарды параметров, но вполне способна вместиться в одну домашнюю GPU: вы можете использовать её в своих проектах для классификации предложений, представления текстов и других языковых задач, не требующих генерации. В статье можно прочитать о подробностях обучения, которые мы реализовали в открытом коде, а чекпоинт теперь тоже доступен всем желающим.
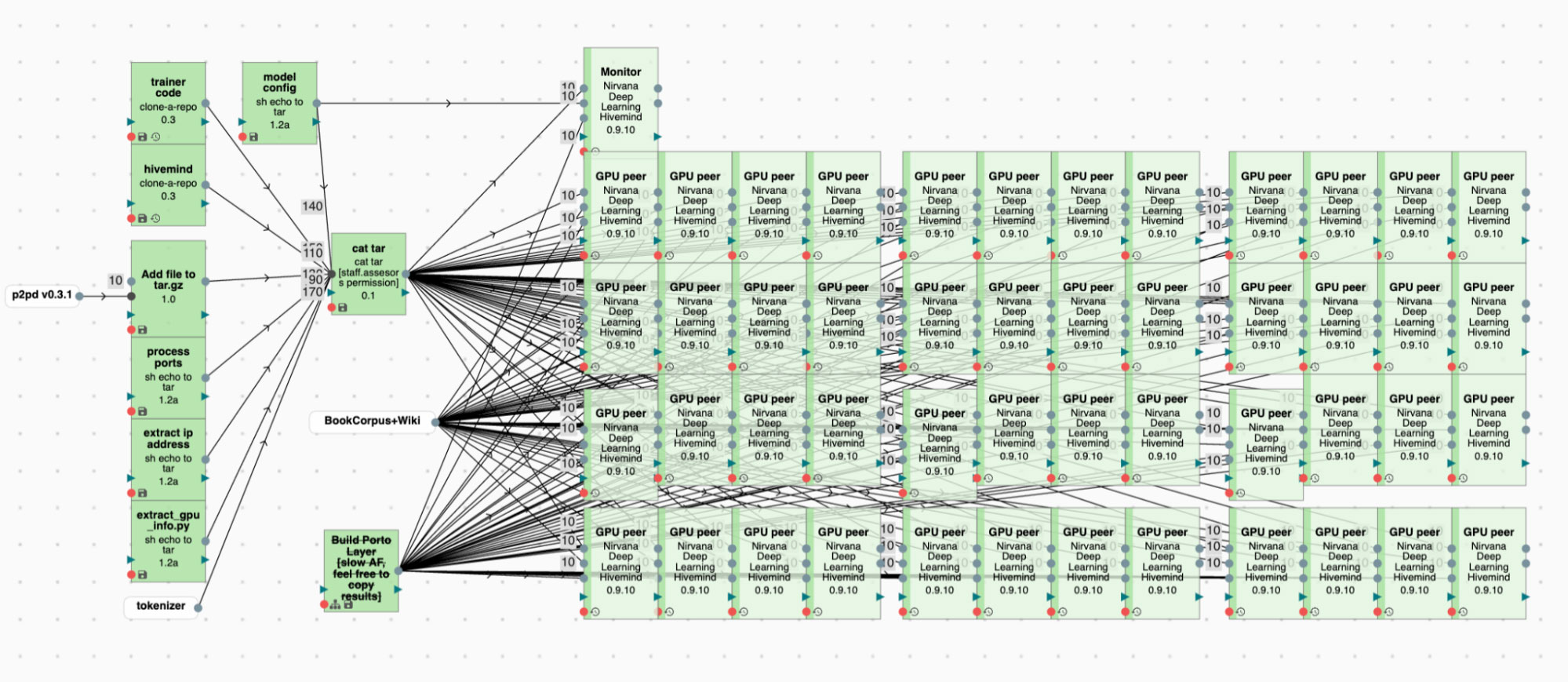
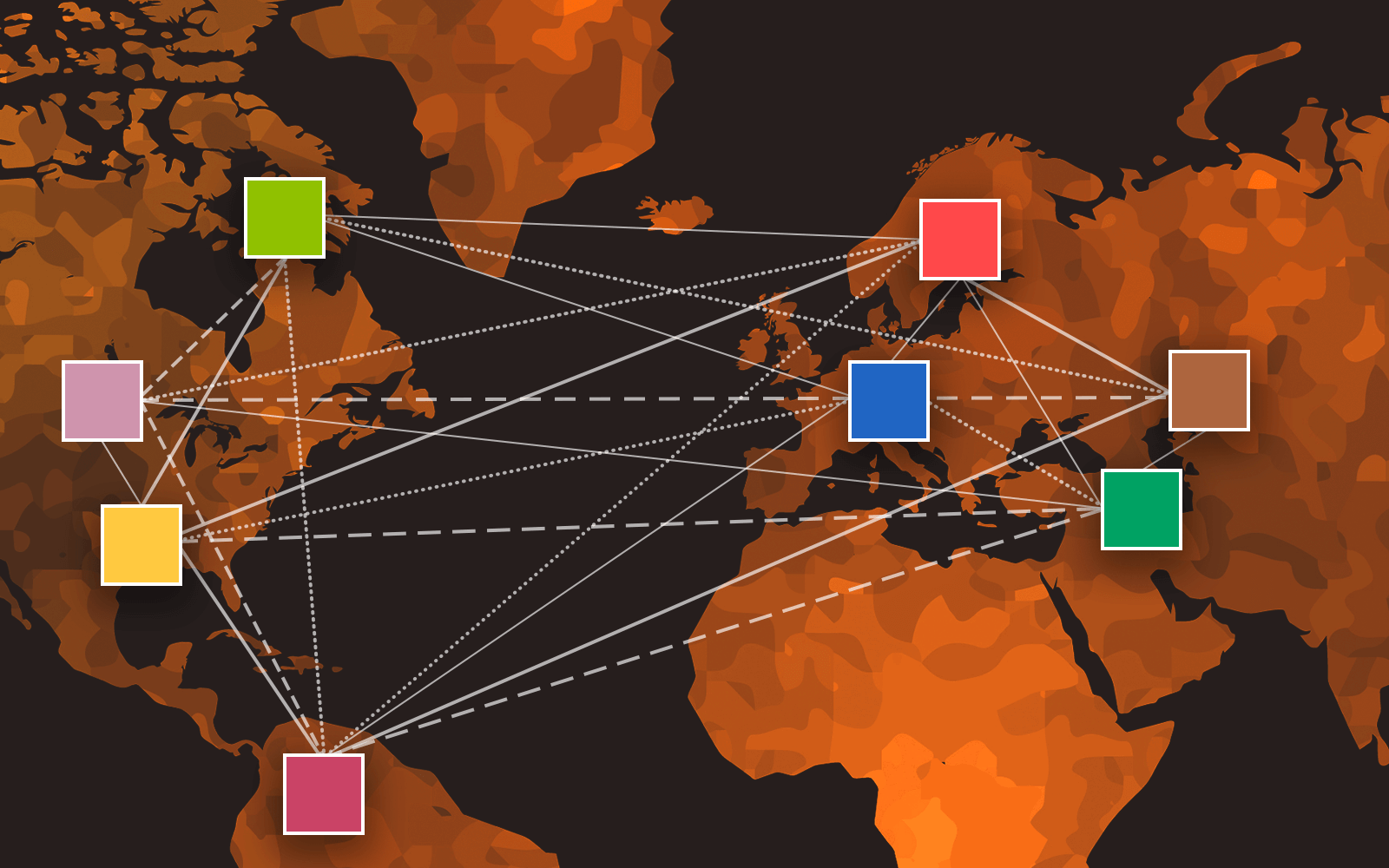
Примерно так выглядит процесс обучения на множестве независимых серверов
Используя вычислительную платформу Яндекса, мы обучили RuLeanALBERT — нейросеть, показывающую сравнимые с другими открытыми моделями и где-то даже близкие к state-of-the-art результаты на бенчмарках по пониманию русского языка — Russian SuperGLUE и RuCoLA. Наша модель хотя и имеет миллиарды параметров, но вполне способна вместиться в одну домашнюю GPU: вы можете использовать её в своих проектах для классификации предложений, представления текстов и других языковых задач, не требующих генерации. В статье можно прочитать о подробностях обучения, которые мы реализовали в открытом коде, а чекпоинт теперь тоже доступен всем желающим.
Примерно так выглядит процесс обучения на множестве независимых серверов