В предыдущей статье, Обзор нейронных сетей для классификации изображений, мы ознакомились с основными базовыми понятиями сверточных нейронных сетей, а также лежащими в их основе идеями. В данной статье мы рассмотрим несколько архитектур глубоких нейронных сетей, обладающих большой вычислительной мощностью — таких как AlexNet, ZFNet, VGG, GoogLeNet и ResNet — и подытожим основные преимущества каждой из этих архитектур. Структура статьи основана на записи в блоге Основные понятия сверточных нейронных сетей, часть 3.
В настоящее время основным стимулом, лежащим в основе развития систем машинного распознавания и классификации изображений, служит кампания ImageNet Challenge. Кампания представляет собой соревнование по работе с данными, в рамках которого участникам предоставляется большой набор данных (более миллиона изображений). Задачей конкурса является разработка алгоритма, позволяющего классифицировать требуемые изображения на объекты в 1000 категориях — таких как собаки, кошки, автомобили и другие — с минимальным количеством ошибок.
Согласно официальным правилам проведения конкурса, алгоритмы должны обеспечивать генерацию списка не более чем из пяти категорий объектов в порядке убывания доверия для каждой категории изображений. Качество маркировки изображений оценивается на основании метки, которая наилучшим образом соответствует свойству ground truth (основополагающая истина) для изображения. Идея заключается в том, чтобы позволить алгоритму идентифицировать несколько объектов на изображении и не начислять штрафные очки в том случае, если какой-либо из обнаруженных объектов на самом деле присутствовал на изображении, но не был включен в свойство ground truth.
В первом году проведения конкурса участникам были предоставлены предварительно выделенные признаки изображений для обучения модели. Это могли быть, к примеру, признаки алгоритма SIFT, обработанные с помощью векторного квантования и подходящие для использования в методе «мешок слов» либо для представления в виде пространственной пирамиды. Однако в 2012 году случился настоящий прорыв в данной сфере: группа ученых из Университета Торонто продемонстрировала, что глубокая нейросеть может достичь значительно более высоких результатов по сравнению с традиционными моделями машинного обучения, построенными на базе векторов из предварительно выделенных свойств изображений. В последующих разделах будет рассмотрена первая новаторская архитектура, предложенная в 2012 году, а также архитектуры, являющиеся ее последователями вплоть до 2015 года.
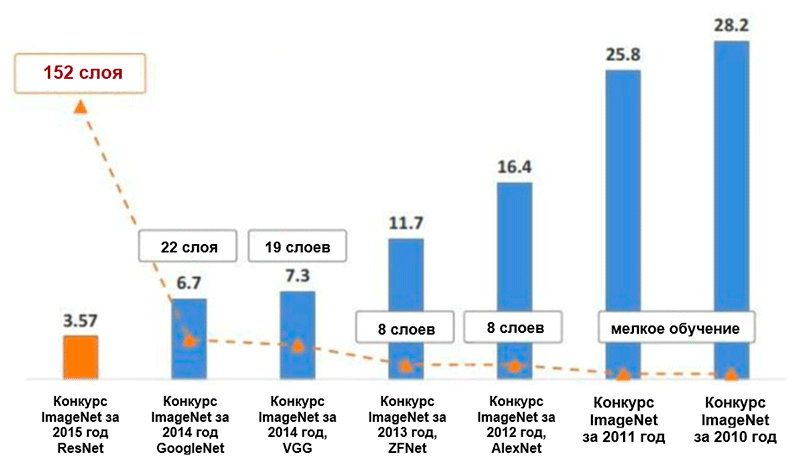
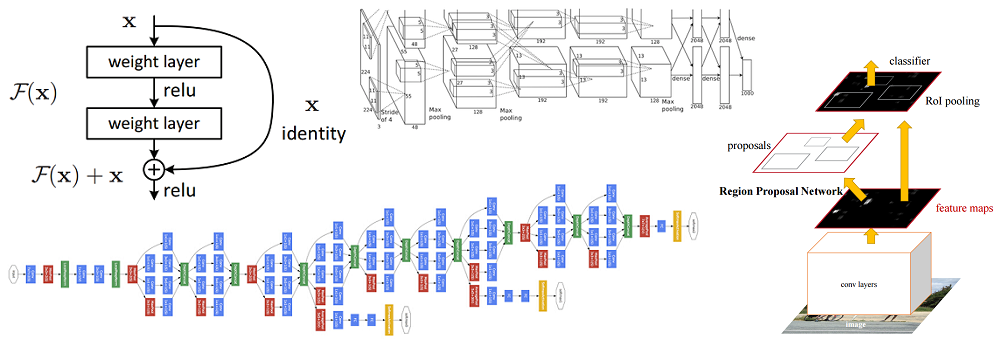
Диаграмма изменения числа ошибок (в процентах) при классификации изображений ImageNet* для пяти ведущих категорий. Изображение взято из презентации Кайминга Хи (Kaiming He), Глубокое остаточное обучение для распознавания изображений
AlexNet
Архитектура AlexNet была предложена в 2012 году группой ученых (А. Крижевским, И. Сатскевером и Дж. Хинтоном) из Университета Торонто. Это была новаторская работа, в которой авторы впервые использовали (на тот момент) глубокие сверточные нейросети с общей глубиной в восемь слоев (пять сверточных и три полносвязных слоя).
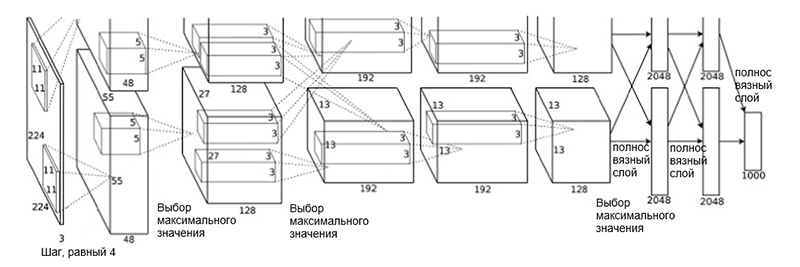
Архитектура AlexNet
Архитектура сети состоит из следующих слоев:
- [Сверточный слой + выбор максимального значения + нормализация] x 2
- [Сверточный слой] x 3
- [Выбор максимального значения]
- [Полносвязный слой] x 3
Такая схема может выглядеть слегка странной, потому что процесс обучения был разделен между двумя графическими процессорами вследствие его высокой вычислительной сложности. Такое разделение работы между графическими процессорами требует ручного разделения модели на вертикальные блоки, которые взаимодействуют друг с другом.
Архитектура AlexNet позволила сократить число ошибок для пяти ведущих категорий до 16,4 процента — почти вдвое по сравнению с предыдущими передовыми разработками! Также в рамках данной архитектуры была представлена такая функция активации, как блок линейной ректификации (ReLU), который является в настоящее время отраслевым стандартом. Далее приведена краткая сводка прочих основных свойств архитектуры AlexNet и процесса ее обучения:
- Интенсивная аугментация данных
- Метод исключения
- Оптимизация с помощью момента SGD (см. руководство по оптимизации «Обзор алгоритмов оптимизации градиентного спуска»)
- Ручная настройка скорости обучения (уменьшение данного коэффициента на 10 при стабилизации точности)
- Итоговая модель представляет собой совокупность из семи сверточных нейросетей
- Обучение проводилось на двух графических процессорах NVIDIA* GeForce GTX* 580 с объемом видеопамяти всего 3 Гбайт на каждом из них
ZFNet
Сетевая архитектура ZFNet, предложенная исследователями М. Цилером (M. Zeiler) и Р. Фергюсом (R. Fergus) из Нью-Йоркского университета, практически идентична архитектуре AlexNet. Единственные существенные отличия между ними заключаются в следующем:
- Размер фильтра и шаг в первом сверточном слое (в AlexNet размер фильтра равен 11 × 11, а шаг равен 4; в ZFNet — 7 × 7 и 2 соответственно)
- Количество фильтров в чистых сверточных слоях (3, 4, 5).
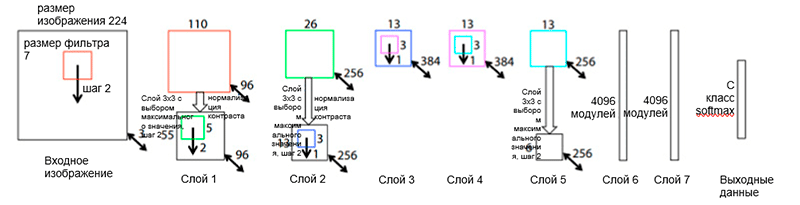
Архитектура ZFNet
Благодаря архитектуре ZFNet число ошибок для пяти ведущих категорий снизилось до 11,4 процента. Возможно, основную роль в этом играет точная настройка гиперпараметров (размер и количество фильтров, размер пакетов, скорость обучения и т. д.). Однако также вероятно и то, что идеи архитектуры ZFNet стали очень весомым вкладом в развитие сверточных нейросетей. Цилер и Фергюс предложили систему визуализации ядер, весов и скрытого представления изображений, которая называется DeconvNet. Благодаря ей стало возможным лучшее понимание и дальнейшее развитие сверточных нейронных сетей.
VGG Net
В 2014 году К. Симонян (K. Simonyan) и Э. Циссерман (A. Zisserman) из Оксфордского университета предложили архитектуру, называемую VGG. Основной и отличительной идеей этой структуры является сохранение фильтров настолько простыми, насколько это возможно. Поэтому все операции свертки выполняются с помощью фильтра размером 3 и шага величиной 1, а все операции субдискретизации — с помощью фильтра размером 2 и шага величиной 2. Однако это не все. Одновременно с простотой сверточных модулей сеть значительно выросла в глубину — теперь она имеет 19 слоев! Важнейшая идея, впервые предложенная в этой работе, заключается в наложении сверточных слоев без слоев субдискретизации. Лежащая в основе этого идея заключается в том, что такое наложение по-прежнему обеспечивает достаточно большое рецептивное поле (например, три наложенных друг на друга сверточных слоя размером 3 × 3 с шагом 1 имеют рецептивное поле аналогичное одному сверточному слою размером 7 × 7), однако количество параметров при этом значительно меньше, чем в сетях с большими фильтрами (служит в качестве регуляризатора). Кроме того, появляется возможность внесения дополнительных нелинейных преобразований.
По существу, авторы продемонстрировали, что даже с помощью очень простых стандартных блоков можно добиться превосходного качества результатов в конкурсе ImageNet. Число ошибок для пяти ведущих категорий сократилось до 7,3 процента.
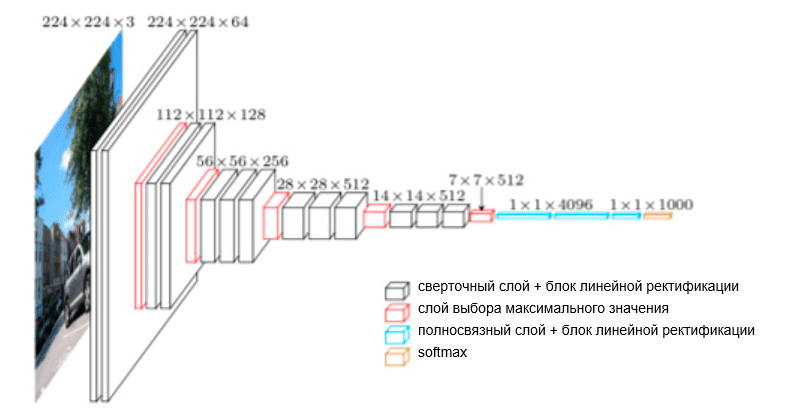
Архитектура VGG. Обратите внимание, что количество фильтров обратно пропорционально пространственному размеру изображения
GoogLeNet
Ранее все развитие архитектуры заключалось в упрощении фильтров и увеличении глубины сети. В 2014 году К. Сегеди (C. Szegedy) совместно с другими участниками предложил совершенно иной подход и создал самую сложную на тот момент времени архитектуру, называемую GoogLeNet.
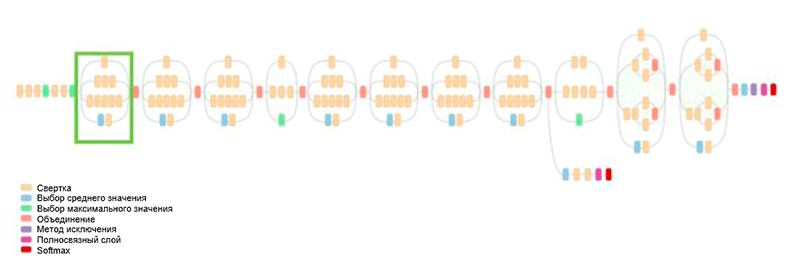
Архитектура GoogLeNet. В ней используется модуль Inception, выделенный на рисунке зеленым цветом; построение сети осуществляется на основе этих модулей
Одним из основных достижений данной работы является так называемый модуль Inception, который показан на рисунке ниже. Сети других архитектур выполняют обработку входных данных последовательно, слой за слоем, в то время как при использовании модуля Inception входные данные обрабатываются в параллельном режиме. Это позволяет ускорить получение вывода, а также минимизировать общее количество параметров.
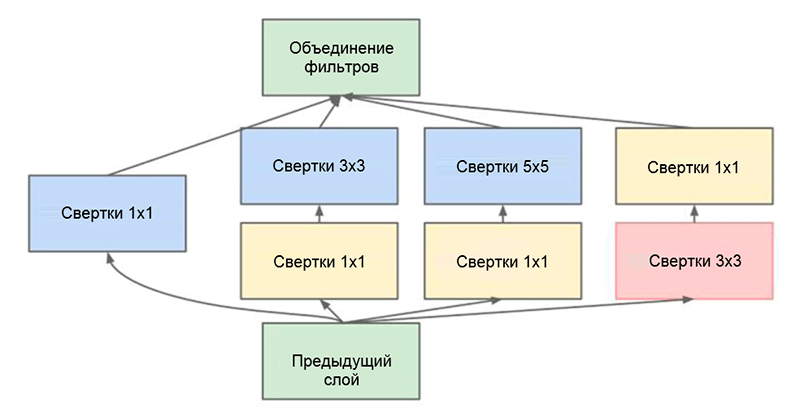
Модуль Inception. Обратите внимание, что модуль использует несколько параллельных ветвей, которые вычисляют различные свойства на основании одних и тех же входных данных, после чего объединяет полученные результаты
Еще один интересный прием, используемый в модуле Inception, заключается в применении сверточных слоев размером 1 × 1. Это может показаться бессмысленным до тех пор, пока мы не вспомним о том факте, что фильтр покрывает всю размерность глубины. Таким образом, свертка размером 1 × 1 является простым способом сокращения размерности карты свойств. Такой тип сверточных слоев впервые был представлен в работе Сеть в сети М. Лина и соавторов, исчерпывающее и понятное объяснение также можно найти в записи блога Свертка [1 × 1] — полезность вопреки интуиции за авторством А. Пракаша.
В конечном счете такая архитектура позволила сократить число ошибок для пяти ведущих категорий еще на полпроцента — до значения 6,7 процента.
ResNet
В 2015 году группа исследователей (Кайминг Хи и другие) из Microsoft Research Asia выступила с идеей, которая в настоящий момент считается большей частью сообщества одним из самых важных этапов в развитии глубокого обучения.
Одной из основных проблем глубоких нейросетей является проблема исчезающего градиента. В двух словах, это техническая проблема, возникающая при использовании метода обратного распространения ошибки для алгоритма вычисления градиента. При работе с обратным распространением ошибки используется цепное правило. При этом, если градиент имеет малое значение в конце сети, то он может принять бесконечно малое значение к тому моменту, как он достигнет начала сети. Это может привести к проблемам совершенно различного свойства, включая невозможность обучения сети в принципе (для получения дополнительной информации см. запись в блоге Р. Капура (R. Kapur) Проблема исчезающего градиента).
Для решения этой проблемы Кайминг Хи со своей группой предложил следующую идею — позволить сети изучать остаточное отображение (элемент, который следует добавить ко входным данным) вместо отображения как такового. Технически это выполняется с помощью обходного соединения, показанного на рисунке.
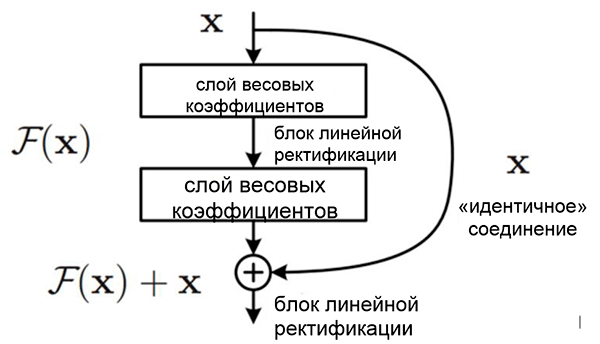
Принципиальная схема остаточного блока: входные данные передаются по сокращенному соединению в обход преобразующих слоев и добавляются к полученному результату. Обратите внимание на то, что «идентичное» соединение не добавляет дополнительные параметры в сеть, поэтому ее структура не усложняется
Эта идея чрезвычайно проста, но в то же время исключительно эффективна. Она решает проблему исчезающего градиента, позволяя ему перемещаться без каких-либо изменений от верхних слоев к нижним посредством «идентичных» соединений. Благодаря этой идее можно обучать очень глубокие, чрезвычайно глубокие сети.
Сеть, победившая в конкурсе ImageNet Challenge в 2015 году, содержала 152 слоя (авторы смогли обучить сеть, содержавшую 1001 слой, однако она выдала примерно такой же результат, поэтому они прекратили работу с ней). Кроме того, данная идея позволила сократить число ошибок для пяти ведущих категорий буквально в два раза — до значения в 3,6 процента. Согласно исследованию Чему я научился, соревнуясь со сверточной нейросетью на конкурсе ImageNet, проведенному А. Карпати (A. Karpathy), производительность человека для этой задачи составляет примерно 5 процентов. Это означает, что архитектура ResNet способна превзойти человеческие результаты, по крайней мере в данной задаче классификации изображений.
