(Части 1, 2, 3) В четвёртой части мы поговорим о проверке грамматики за пределами токенизированных передложений.
Как уже упоминалось, разбиение предложения на токены и POS-разметка уже позволяют создать простой инструмент проверки грамматической корректности текста. По крайней мере, LanguageTool плагин к Open Office работает именно так. Очевидно, что массу ошибок можно выловить на уровне размеченных токенов. Однако также очевидно, что не менее обширные классы ошибок остаются за пределами возможностей нашего модуля. Взять хотя бы такую простую вещь как согласование подлежащего и сказуемого: «дама любил собак», «любил собак дама», «собак дама любил»… как составить паттерн для правила «сказуемое должно иметь тот же род, что и подлежащее?» Даже для английского языка с более-менее чётким порядком слов это трудно, говорить о русском и вовсе не приходится.
Авторы LanguageTool пытаются формулировать отдельные грамматические паттерны. На практике получаются довольно сложные конструкции, работающие в ограниченном числе случаев. Например:
«Предложение начинается с определяющего слова, затем идёт существительное во множественном числе, затем глагол в третьем лице, единственном числе». Под такое определение попадают фрагменты вроде «The cats drinks milk». Очевидно, что глагол должен стоять в форме первого лица (drink). Как видите, это правило срабатывает лишь в начале предложения и только для чётко определённой ситуации. Вероятно, авторы перестраховываются, чтобы избежать ложных срабатываний (понятно, что не каждая пара близко расположенных слов «существительное + глагол» является связкой вида «подлежащее + сказуемое»).
Более надёжным мне видится вариант с привлечением синтаксического анализатора (парсера) естественного языка.

Существуют разные представления о том, как именно следует соединять слова. Вместо непосредственных рёбер «слово-слово» можно, например, выделять составные члены предложения:
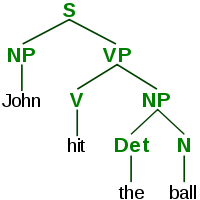
Этот подход пропагандировал Хомский, и он до сих пор популярен среди англоязычных исследователей. Однако сторонников связей «слово-слово» (dependency links) сейчас становится всё больше, особенно в Европе, так как считается, что деревья Хомского не очень хорошо подходят для языков с более свободным порядком слов (а в Европе таких языков масса).
Пожалуй, на парсере у меня случился первый затык в работе. Сложно найти хороший парсер (кстати, sentence splitter и POS tagger тоже, но их быстро можно написать самостоятельно, благо вспомогательные библиотеки есть). У нас всё-таки практический проект, и хотелось бы, чтобы этот модуль был (а) на C/C++ (поскольку весь наш проект на нём); (б) был бесплатен или стоил разумных денег; (в) поддерживал dependency links; (г) был адаптируем к новым языкам.
Я провёл кучу времени в поисках, опробовал массу парсеров. Тут царит полный разброд — кто-то за парсер не держится (LGPL), кто-то хочет нереальных денег (мне называли цены в 100 и даже в 300 тысяч евро — по-моему, это за пределами добра и зла), а кому-то надобен процент от продаж. Ладно бы парсер был основным модулем в системе, но это ж не так, это всего лишь часть модуля грамматической проверки!
Несколько месяцев назад я решил остановиться на проекте MaltParser. Он всем хорош (даже поддерживает так называемые непроективные связи, что приятно), кроме выбранного авторами языка — Java. Я уже приготовился стиснуть зубы и переписать код на C++ (а кода там много...), но буквально недавно нарисовался новый проект под названием LDPar. Не знаю, как у него с качеством разбора, но по остальным критериям подходит. Китайцы спасут мир! Ну или, по крайней мере, наш проект :)
По правде говоря, я пока не готов приводить здесь конкретные примеры грамматических правил, анализируемых с помощью парсера — мы только начали экспериментировать с этим модулем. Но простейшие идеи уже ясны. Например, как проверить сочетаемость подлежащего со сказуемым (для английского):
Берём корень дерева, проверяем, что корень является глаголом — тогда это сказуемое.
Ищем первое связанное с ним существительное или местоимение — это подлежащее.
Проверяем сочетаемость в лице и числе.
Из очевидных потенциальных проблем могу назвать непонятное качество разбора некорректных предложений. То есть сходу неясно, сочтёт ли парсер слова I и has подлежащим и сказуемым в предложении «I has dogs». На эту тему нужно проводить исследования, пока таковых нет. В комментариях как-то упоминали корпус с ошибками (авторства J. Foster) — вот на нём я лично тестировал некоторые синтаксические анализаторы. Большинство из них корректно разбирали даже фразы с ошибками, но дополнительное изучение вопроса точно не повредит.
Так, на сегодня заканчиваю, а в следующей части поговорим ещё немного о трибанках.
Как уже упоминалось, разбиение предложения на токены и POS-разметка уже позволяют создать простой инструмент проверки грамматической корректности текста. По крайней мере, LanguageTool плагин к Open Office работает именно так. Очевидно, что массу ошибок можно выловить на уровне размеченных токенов. Однако также очевидно, что не менее обширные классы ошибок остаются за пределами возможностей нашего модуля. Взять хотя бы такую простую вещь как согласование подлежащего и сказуемого: «дама любил собак», «любил собак дама», «собак дама любил»… как составить паттерн для правила «сказуемое должно иметь тот же род, что и подлежащее?» Даже для английского языка с более-менее чётким порядком слов это трудно, говорить о русском и вовсе не приходится.
Авторы LanguageTool пытаются формулировать отдельные грамматические паттерны. На практике получаются довольно сложные конструкции, работающие в ограниченном числе случаев. Например:
<token postag=«SENT_START»></token>
<token postag=«DT»></token>
<token postag=«NNS»></token>
<token postag=«VBZ»></token>
* This source code was highlighted with Source Code Highlighter.
«Предложение начинается с определяющего слова, затем идёт существительное во множественном числе, затем глагол в третьем лице, единственном числе». Под такое определение попадают фрагменты вроде «The cats drinks milk». Очевидно, что глагол должен стоять в форме первого лица (drink). Как видите, это правило срабатывает лишь в начале предложения и только для чётко определённой ситуации. Вероятно, авторы перестраховываются, чтобы избежать ложных срабатываний (понятно, что не каждая пара близко расположенных слов «существительное + глагол» является связкой вида «подлежащее + сказуемое»).
Более надёжным мне видится вариант с привлечением синтаксического анализатора (парсера) естественного языка.
О синтаксическом анализе
Синтаксический анализатор — это модуль, строящий для входного предложения дерево связей между словами. Пример такого дерева для фразы «я люблю больших собак» приводился во второй части заметок:Существуют разные представления о том, как именно следует соединять слова. Вместо непосредственных рёбер «слово-слово» можно, например, выделять составные члены предложения:
Этот подход пропагандировал Хомский, и он до сих пор популярен среди англоязычных исследователей. Однако сторонников связей «слово-слово» (dependency links) сейчас становится всё больше, особенно в Европе, так как считается, что деревья Хомского не очень хорошо подходят для языков с более свободным порядком слов (а в Европе таких языков масса).
Пожалуй, на парсере у меня случился первый затык в работе. Сложно найти хороший парсер (кстати, sentence splitter и POS tagger тоже, но их быстро можно написать самостоятельно, благо вспомогательные библиотеки есть). У нас всё-таки практический проект, и хотелось бы, чтобы этот модуль был (а) на C/C++ (поскольку весь наш проект на нём); (б) был бесплатен или стоил разумных денег; (в) поддерживал dependency links; (г) был адаптируем к новым языкам.
Я провёл кучу времени в поисках, опробовал массу парсеров. Тут царит полный разброд — кто-то за парсер не держится (LGPL), кто-то хочет нереальных денег (мне называли цены в 100 и даже в 300 тысяч евро — по-моему, это за пределами добра и зла), а кому-то надобен процент от продаж. Ладно бы парсер был основным модулем в системе, но это ж не так, это всего лишь часть модуля грамматической проверки!
Несколько месяцев назад я решил остановиться на проекте MaltParser. Он всем хорош (даже поддерживает так называемые непроективные связи, что приятно), кроме выбранного авторами языка — Java. Я уже приготовился стиснуть зубы и переписать код на C++ (а кода там много...), но буквально недавно нарисовался новый проект под названием LDPar. Не знаю, как у него с качеством разбора, но по остальным критериям подходит. Китайцы спасут мир! Ну или, по крайней мере, наш проект :)
По правде говоря, я пока не готов приводить здесь конкретные примеры грамматических правил, анализируемых с помощью парсера — мы только начали экспериментировать с этим модулем. Но простейшие идеи уже ясны. Например, как проверить сочетаемость подлежащего со сказуемым (для английского):
Берём корень дерева, проверяем, что корень является глаголом — тогда это сказуемое.
Ищем первое связанное с ним существительное или местоимение — это подлежащее.
Проверяем сочетаемость в лице и числе.
Из очевидных потенциальных проблем могу назвать непонятное качество разбора некорректных предложений. То есть сходу неясно, сочтёт ли парсер слова I и has подлежащим и сказуемым в предложении «I has dogs». На эту тему нужно проводить исследования, пока таковых нет. В комментариях как-то упоминали корпус с ошибками (авторства J. Foster) — вот на нём я лично тестировал некоторые синтаксические анализаторы. Большинство из них корректно разбирали даже фразы с ошибками, но дополнительное изучение вопроса точно не повредит.
Так, на сегодня заканчиваю, а в следующей части поговорим ещё немного о трибанках.
