 Любительская локализация — явление, затронувшее многих игроманов, и порой даже сыгравшее не последнюю роль в формировании их интересов и отношения к игровой индустрии в целом. Наверное, благодаря тому, что оно издавна преследовало в основном благие цели, у большинства любителей интерактивных развлечений при его упоминании возникают преимущественно положительные ассоциации, а порой даже и ностальгические эмоции.
Любительская локализация — явление, затронувшее многих игроманов, и порой даже сыгравшее не последнюю роль в формировании их интересов и отношения к игровой индустрии в целом. Наверное, благодаря тому, что оно издавна преследовало в основном благие цели, у большинства любителей интерактивных развлечений при его упоминании возникают преимущественно положительные ассоциации, а порой даже и ностальгические эмоции.В прошлый раз я излагал свой взгляд на явления как любительской, так и официальной локализации. Поскольку нашлись люди, которым эта тема близка или интересна, а также не обошлось и без желающих побольше узнать о технических деталях процесса, то мне ничего не остаётся, как об этом рассказать, пусть и в несколько специфичном стиле.
На картинке изображён логотип российского ромхакинг-сообщества по версии проекта Russian Romhacking.
Перед прочтением
Прежде всего, хочу сказать, что я обозреваю только тот опыт, который я имел возможность наблюдать или практиковать лично. Так что далеко не факт, что все неофициальные локализаторы придерживались описанных ниже методик и уж тем более это касается упомянутого инструментария. В первую очередь я буду рассказывать о подходе, который применял сам. Я считаю, что он в достаточной степени показателен и выигрывает у многих других методик, практикуемых иными энтузиастами. Впрочем, понятие методики тут довольно расплывчато и у многих оная отсутствует вовсе.
На всякий случай упомяну и о том, что мои действия, на которых основывается весь описанный опыт, никогда не преследовали корыстных целей и не носили деструктивный характер. Всё это делалось, в первую очередь, ради самого процесса и саморазвития, и было просто моим хобби.
Честно говоря, я долго думал, как именно структурировать статью и что именно в неё включить — сперва я хотел рассказать не только о технических особенностях процесса, но и расписать суть социальной составляющей. Однако, в какой-то момент я поймал себя на мысли, что из-за обилия критики статья пригодна скорей для несколько другого места, нежели для Хабра — корить большинство непрофессионалов за проявление непрофессионализма и отсутствие стремления к совершенствованию техник несколько цинично.
В итоге я решил описать только техническую часть и только в общем виде — подробного описания с примерами хватило бы на десяток таких статей, а то и на очередную бесполезную книгу, так что пока отложим это в долгий ящик. Несмотря на это, статья даже в незавершённом виде получилась довольно большая, и я решил разбить её на несколько постов. Насколько она вышла интересной или полезной — судить вам.
Техническая сторона вопроса
Если сделать небольшое разбиение процесса перевода на подзадачи, то можно получить примерно такой список:
- Обратная разработка — процесс, многим более известный под термином реверс-инжиниринг. Игру исследуют, разбирают форматы, определяют алгоритмы, находят нужные данные.
- Извлечение ресурсов — преобразование необходимых для перевода ресурсов в удобный для редактирования вид. Текст — в текстовые файлы, графику — в распространённые форматы изображений и т.п. Всё это может осуществляться как вручную (неисповедимы пути дилетантские), так и посредством инструментария — в лучшем случае написанного самими переводчиками.
- Перевод и редактирование — самая суть процесса. Результат именно этих трудов оценивают игроки.
- Сборка перевода — конвертирование ресурсов обратно в игровые форматы и замена ими оригинальных данных игры. В идеале этот процесс должен заключаться только лишь в запуске инструментария для автоматической сборки, но, к сожалению, у большинства переводчиков он заключается в ручном редактировании каждый раз при необходимости внести изменения.
- Тестирование — обязательный этап, позволяющий выявить многие ошибки и порой улучшить перевод. Среди вожделеющих поиграться в любимую игру на родном языке отбираются наиболее ответственные и грамотные, затем им вручается бета-версия перевода с просьбой воспроизвести как можно больше игровых ситуаций. Да и свежий взгляд со стороны — всегда хорошо, многие ошибки команда может просто не видеть.
Если углубляться в детали, то не существует одинаковой для всех случаев последовательности действий, которую необходимо выполнить, чтобы подготовить игру к переводу. Так же не существует универсальных методов, с помощью которых можно выполнить те или иные шаги. По сути это всегда импровизация, но всё же есть список задач, которые встречаются практически всегда.
Я постараюсь выделить наиболее часто возникающие и важные задачи, рассказав про каждую из них отдельно. В качестве платформы не будем рассматривать ничего конкретного — т.е. всё описанное ниже справедливо как для PC, так и для любой другой платформы — будь то любая из PlayStation, XBOX, да хоть Sega или Dendy (NES).
Поскольку в данном контексте большинство задач по реверс-инжинирингу можно решить средствами отладчика или дизассемблера, я буду упоминать о них только в отдельных случаях.
Определение кодировки текста
 Казалось бы, вполне тривиальная задача — определить, в какой кодировке хранится текст. И в большинстве случаев это и правда не составляет труда, но и здесь мысль разработчиков не знает предела.
Казалось бы, вполне тривиальная задача — определить, в какой кодировке хранится текст. И в большинстве случаев это и правда не составляет труда, но и здесь мысль разработчиков не знает предела.Далеко не всегда выводимый текст хранится именно как текст, чаще это просто набор индексов символов в шрифте, которые необходимо отобразить. Нередко их делают совместимыми или частично совместимыми с какой-либо кодировкой, преимущественно это первые 256 символов юникода. Как бы там ни было, всё равно надо установить точное соответствие между символами и их кодами. Впрочем, в современных играх всё чаще вместо индексов используют обыкновенные кодировки и сериализуют текст в форматы вроде XML — о производительности давно никто особо не задумывается.
Для представления кодировки используются «таблицы кодировки» — текстовые файлы, где в каждой строке некой последовательности байт сопоставлена определённая последовательность символов. Выглядит это примерно так:
41=A 42=B ... 5A=Z 1E20=Hero 1E21=Item 1E22=Bonus
Например, текст «Hero obtains Item!» был бы закодирован следующим образом: «
1E 20 20 6F 62 74 61 69 6E 73 20 1E 21 21». Однако, если оказывается, что полученная кодировка в достаточной мере совместима с какой-либо пригодной для использования кодировкой (скажем, с юникодом), то таблица в общем-то не нужна и этот шаг можно пропустить.Самым распространённым способом определить кодировку и найти текст является так называемый «относительный поиск» (relative search). Суть его в том, что ищутся не какие-то абсолютные значения: критерием поиска служит разница между значениями искомой последовательности. Для этого достаточно взять какое-нибудь не слишком короткое слово, встречающееся в игре, и будут найдены все последовательности байт, в которых разница между элементами равна разнице между кодами символов исходного слова.
Например, для слова «WORLD» найдётся как последовательность «57 4F 52 4C 44», так и «77 6F 72 6C 64». Да хоть «13 0B 0E 08 00»! Найдя такие последовательности и убедившись, что это именно закодированное слово, мы может запросто составить таблицу кодировки. Самой известной программой, обладающей таким функционалом, является хекс-редактор Translhexion. Имеется и куча специализированных утилит вроде Search Relative. Да и многие из технически грамотных переводчиков писали для себя подобные утилиты.
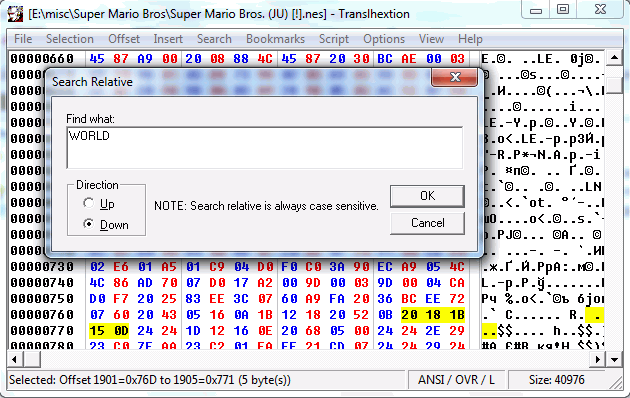
Типичный случай: если сравнить данный скриншот с полотном шрифта, то видно, что найденная последовательность — это индексы символов в шрифте:

В целом, такая методика хоть и применима в подавляющем большинстве случаев, но без некоторых ухищрений действует далеко не всегда. Ведь никто не гарантирует, что коды символов в кодировке идут в том же порядке, что и буквы в алфавите.
Например, в переизданиях многих частей Final Fantasy для GameBoy Advance и Nintendo DS символы в шрифте отсортированы по частоте встречаемости, а для кодирования индексов используется способ, напоминающий UTF-8. Т.е. любой символ с кодом больше 0x7F кодируется двумя байтами, в то время как первые 128 символов кодируются всего одним:
uint16 encode(uint16 code) { return 0x8000 | ((code << 2) & 0x1F00) | (code & 0x3F); }
Более суровый случай на моей памяти — это Final Fantasy: 20th Anniversary Edition для PlayStation Portable. Для каждой локации там существовал свой шрифт, свой текст и, как следствие, своя кодировка. Шрифт состоял только из встречаемых в тексте символов, которые так же были упорядочены по частоте встречаемости. Впору бы использовать нейронные сети для распознавания кодировки каждой локации, но благо хватило попиксельного сравнения масок прозрачности символов.
В этих случаях относительный поиск тоже подходит для решения задачи, но необходимо искать не по разнице между номерами букв, а по разнице между индексами их символов в шрифте. Т.е. можно просто записать последовательность индексов — это вполне сгодится для такого поиска.
Как и другие ресурсы, текст может быть запакован или зашифрован. В таком случае поиск среди данных игры поможет только в случаях, когда в запакованных или зашифрованных данных всё же присутствуют хотя бы обрывки слов (такое часто бывает при использовании алгоритмов вроде LZ77 или RLE). Поэтому выходом может быть поиск в дампе оперативной памяти. Возможность добычи дампа зависит от платформы, для которой делается перевод. Для эмулируемых консолей и PC трудностей быть не должно — есть куча средств для получения доступа к памяти игры. А вот в других случаях нужна возможность во время игры запустить на консоли необходимый код, для чего, как правило, консоль должна быть «взломана». Про методики разбора самих алгоритмов я расскажу в следующей статье.
Поиск указателей
 Если данные хранятся в сериализованном виде, этот пункт можно смело пропускать. Если же ресурсы хранятся в исполняемом файле (что практически всегда верно для консолей, использующих картриджи) в готовом для использования виде, то, как правило, на каждый такой ресурс есть указатель. Естественно, текста это тоже касается. Тем более, чтобы стало возможным свободно модифицировать текст, надо найти все указатели и ссылки на каждую из изменяемых строк.
Если данные хранятся в сериализованном виде, этот пункт можно смело пропускать. Если же ресурсы хранятся в исполняемом файле (что практически всегда верно для консолей, использующих картриджи) в готовом для использования виде, то, как правило, на каждый такой ресурс есть указатель. Естественно, текста это тоже касается. Тем более, чтобы стало возможным свободно модифицировать текст, надо найти все указатели и ссылки на каждую из изменяемых строк.Забавно, что для ряда новичков понимание концепции указателей является одним из самых сложных препятствий в освоении искусства любительского перевода. Как правило, такие люди долгое время не утруждают себя технической стороной процесса и переводят текст так, чтобы он вмещался в длину оригинальной строки. Ещё более забавно то, что для совершенствования навыков многие из них в итоге осваивают программирование. Стоило бы это сделать в обратном порядке — и всё было бы гораздо проще. Хотя стоит заметить, что люди, ставшие полноценными IT-специалистами, часто уходят с этой сцены и начинают заниматься вещами посерьёзней.
Очень часто все указатели хранятся в едином месте, которое обычно называют «таблицей указателей» — оно представляет собой массив из указателей или элементов, их содержащих. В таких случаях игра обращается к строкам по индексам, по которым, в свою очередь, из такой таблицы берётся указатель. Тогда достаточно найти указатель на любую строку в блоке текста — и таблица найдена!
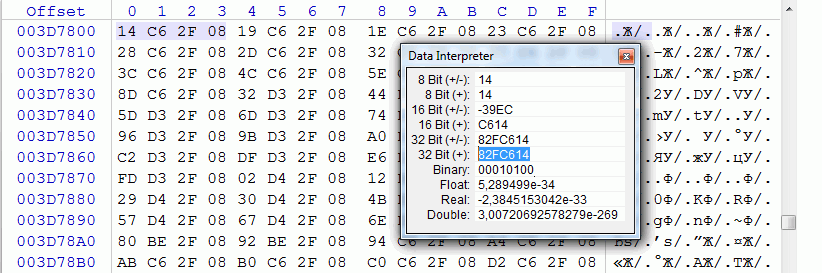
Но не всё так просто… вернее, не всегда всё так просто. Одна из сложностей, мешающих искать указатели, называется «разницей смещений». Дело в том, что указатель может быть не только абсолютным (указывающим на логический или физический адрес ресурса), но и относительным (указывающим на смещение относительно какого-то адреса). Или же, скажем, на старых дисковых консолях вроде PlayStation данные часто хранятся в подготовленном для загрузки в память виде — т.е. пока они лежат в файле, невозможно просто так вычислить, на что будет указывать указатель, не зная адреса, куда будет происходить загрузка.
Пока не известна разница смещений, нельзя однозначно вычислить указатель. Поэтому первым делом обычно проверяют наличие таблицы — для этого может помочь тот же самый относительный поиск. В качестве элементов искомой последовательности берутся расстояния между началами строк — разница между значениями указателей будет точно такой же. Если таблица не находится — поиск повторяют, перебирая возможные размеры указателей и возможные расстояния между ними (если помимо указателей в таблицах содержатся другие данные).
// Может быть так char* strings[] = {...}; // А может быть и так... struct Message { int characterId; int messageType; char* string; }; Message messages[] = {...};
Однако, не всё коту масленица — некоторые игры обращаются к строке прямиком по указателю без использования таблиц. Тогда уже разницу вычисляют как могут: например, путём визуального анализа данных или с помощью дизассемблера. Есть ещё один «дедовский» способ: участки данных «поганят», подменяя байты, и смотрят, отразилось ли это как-нибудь на игре. Таким образом, сокращая диапазон поиска методом исключения, можно локализовать участок кода, отвечающий за вывод какой-либо строки, и найти указатель. Для таких целей даже существуют целые специализированные инструменты вроде Поганка или Visual Poganka.
Без использования таблиц указатели будут раскиданы по всему пространству кода в исполняемом файле, и порой далеко не в единичном экземпляре. Если текст складирован в одном месте, эту проблему можно решить, просканировав его и найдя все указатели на начало каждой строки. И в большинстве случаев это не составляет труда — из-за особенностей адресного пространства вероятность коллизии значения указателя с другим значением минимальна (например, память адресуется в диапазоне 0x08000000-0x09FFFFFF или секция данных начинается с адреса 0x00472000).
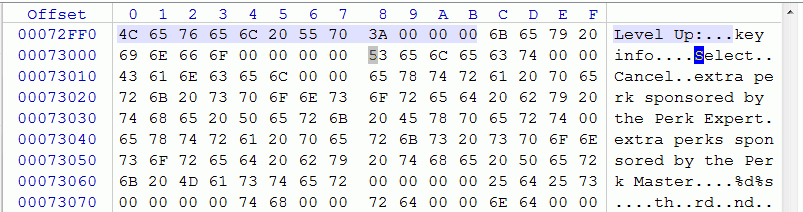
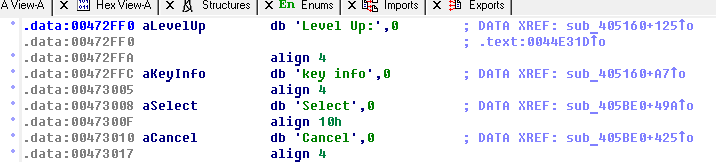
Но бывает и так, что память адресуется менее удачным для переводчика способом: например, начиная с нулевого адреса. И тогда коллизий уж точно не избежать… Придётся вручную проверять каждое значение, встречающееся более одного раза, на предмет того, является ли оно указателем или же данными с таким же значением. А если ещё и сам текст разбросан по файлу, то автоматизировать процесса поиска указателей можно разве что написав какой-нибудь скрипт или плагин к IDA Pro.
Так или иначе, терпение и труд всё перетрут. Достаточно найти указатели один раз и дальше с этой задачей можно не заморачиваться, переходя к следующему шагу.
Извлечение текста
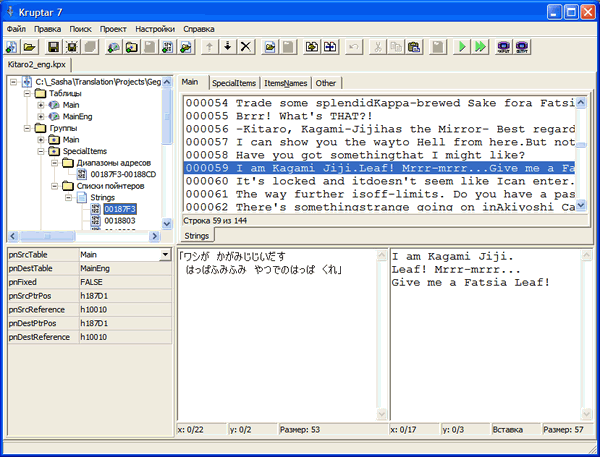
 Способ «выемки» текста по таблицам зависит от уровня организации переводчиков. Так, самые неорганизованные ребята (как правило, новички) вообще не заморачиваются и переводят текст прямо в хекс-редакторах. Чуть посерьёзней — используют для извлечения программы-всёделалки вроде PokePerevod или тот же Translhexion. Люди с более глубокими познаниями используют более специализированные средства автоматизации вроде Kruptar. Самые продвинутые специалисты обычно пишут для этого свои скрипты или инструменты, что и вовсе позволяет им контролировать процесс полностью.
Способ «выемки» текста по таблицам зависит от уровня организации переводчиков. Так, самые неорганизованные ребята (как правило, новички) вообще не заморачиваются и переводят текст прямо в хекс-редакторах. Чуть посерьёзней — используют для извлечения программы-всёделалки вроде PokePerevod или тот же Translhexion. Люди с более глубокими познаниями используют более специализированные средства автоматизации вроде Kruptar. Самые продвинутые специалисты обычно пишут для этого свои скрипты или инструменты, что и вовсе позволяет им контролировать процесс полностью.В любом случае, в чаще всего процесс сводится к преобразованию потока байт в пригодный к чтению и редактированию вид, используя информацию о кодировках, бинарных тегах и применяемом игрой байткоде, если он имеет место быть.
Но вовсе не факт, что разработчики изначально хранили текст отдельно и в чистом виде. Очень часто он является лишь частью других данных — карт уровней, сценариев и т.п. Если кто-нибудь знаком с игровыми редакторами вроде TES Construction Set, то он поймёт, о чём речь. В таких случаях, поскольку текст хранится совместно с другими данными, необходимо «распарсить» их структуру и аккуратно извлечь текст и прочую необходимую информацию — например, иногда помимо текста необходимо изменять ещё и такие данные, как координаты его вывода и размеры диалоговых окон. Порой для этого пишутся целые редакторы, которые частично воспроизводят функционал средств, которыми пользовались разработчики.
В целом, к извлечению текста у меня свой подход. Начнём с того, что стандартный формат таблиц кодировки довольно прост и не покрывает все случаи. Например, иногда важно знать, какие последовательности байт служат для индикации конца текста, переноса строки или очистки экрана. Также в игре могут быть использованы, к примеру, коды разметки, где определённая часть битов выступает в качестве параметра. В таком случае пришлось бы записывать всё это дело примерно так:
1E40=[size=0] 1E41=[size=1] 1E42=[size=2] ... 1E4F=[size=15]
Поэтому существует множество надстроек над этим форматом — я даже разрабатывал своё собственное расширение, которое позволяло описать даже коды разметки и прочие байты с параметрами, а также поддерживало директивы вроде include (удобно, когда есть таблицы для разных языков, но в них есть одинаковые элементы).
Рассмотрим пример таблицы в расширенном формате:
; Включаем поддержку escape-последовательностей (для \n и т.п.) .format ; Аватарка и имя главного героя (вводится игроком) ; Имя берём в скобки, чтобы случайно не склонили C2A5=[Av-0] C2B3={Hero} ; Команды очистки диалогового окна, перед «равно» ставится тильда ("~") ; Бывают разных типов (требуют нажатия кнопки, не требуют и т.п.) C2B7C391~=\n-> C2B7~=\n- ; Перенос строки — чтобы сказать о нём, перед «равно» ставим "^" ; В тексте перенос строки будет являться... переносом строки :) C28E^=\n ; Подключаем другие таблицы .include opcodes.tbl .include avatars.tbl ; Признак конца строки (аналог нуль-терминатора в C string), перед «равно» восклицательный знак ; Справа пусто, потому что в тексте нам никак не надо его обозначать, ; но при конвертации надо на нём остановиться 0D!=
Несмотря на некоторую кашу в таблице, на выходе получался довольно опрятный для игрового скрипта текст:
Jenica: I've served in this castle for quite
some time. I looked after both Princess
Lenna and Princess Sarisa.
-
[Av-0]{Hero}: Sarisa?
->
Jenica: Princess Lenna's older sister.
Sarisa was sailing with her father when
a storm hit, and she was lost at sea.
О роли опрятности будет сказано чуть ниже, а сейчас рассмотрим проблему байткода. В некоторых играх используются даже свои скриптовые языки, и хорошо, если текст в них используется в качестве внешних ресурсов. Но порой всё же приходится разгребать мешанину из текста и кода.
Если невозможно отделить код от текста, то обычно для каждой инструкции придумывают мнемонику и форму записи исходя из её назначения. Составив базу с информацией о всех инструкциях, несложно написать транслятор. Но чтобы не писать такие вещи каждый раз, я придумал ещё одно расширение для таблицы кодировки.
Инструкция в байткоде идентифицируется по определённым значениям некоторых битов. Допустим, у нас есть две инструкции размером с байт. У одной инструкции биты с первого по четвёртый равны
0101, т.е. выглядит она как 0101nnnn; у другой — первые два бита равны 11, т.е. запишем её как 11nnnnnn. Самым простым способом идентифицировать инструкцию является сравнение по маске — т.е. надо произвести логическое умножение опознаваемого кода на битовую маску, выделив тем самым нужные биты, и сравнить результат с эталонными данными (далее по тексту будем называть это идентификатором инструкции). Таким образом, для первой инструкции маской будет 11110000, поскольку мы должны взять только первые 4 бита, а идентификатором, соответственно, будет 01010000. Для второй инструкции и маска, и идентификатор равны 11000000.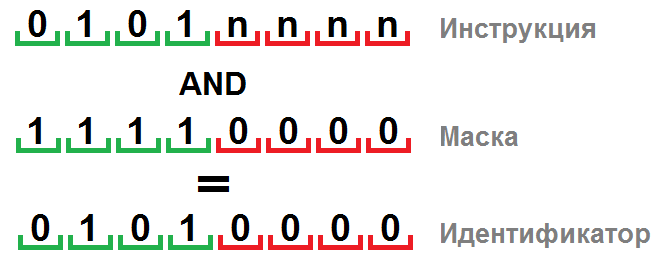
Суть расширения в том, что для инструкций можно прямо в таблице записать битовые маски и идентификаторы, которые нужны для их определения и чтения параметров. А вместо простой последовательности символов можно использовать специальную строку, которая будет говорить о том, как форматировать и конвертировать текстовое представление инструкции обратно в байткод. Т.е. по таким таблицам можно было бы даже примитивно дизассемблировать исполняемые файлы.
Форма такой записи инструкции в таблице кодировки такова:
<OpcodeMask>?<OpcodeID>:<ValuesMasks>=<FormatString>
Где OpcodeMask — маска, OpcodeID — идентификатор, ValueMasks — перечисленный через запятую список битовых масок параметров, а FormatString — строка для форматирования текстового представления инструкции и конвертации её обратно в байткод (представляет из себя модифицированный эквивалент форматных строк для функции printf).
Например, у нас есть инструкция вида
1010iiii cccccccc, показывающая во всплывающем окне цвета с предмет с номером i. Назовём её «popup(item, color)». Маска данной инструкции равна 11110000 00000000, что в шестнадцатеричном представлении будет F000. Идентификатор инструкции будет равен 10100000 00000000, т.е. C000, а маски параметров — 00001111 00000000 и 00000000 11111111, то бишь 0F00 и 00FF соответственно.Пусть у нас имеется такой вот закодированный текст:
0000: 4F 62 74 61 69 6E 65 64 20 61 6E 20 69 74 65 6D Obtained an item0010: 21 C1 0F 0A 4E 6F 77 20 79 6F 75 20 63 61 6E 20 !##\nNow you can0020: 6F 70 65 6E 20 74 68 65 20 64 6F 6F 72 2E open the door.Попробуем декодировать его с помощью таблицы, в которой есть такая запись:
F000?C000:0F00,00FF=popup(%d, %d)
Получаем такой результат:
Obtained an item!popup(1, color)
Now you can open the door.
Не совсем удачно сочетается с текстом. Поэтому попробуем прибегнуть к помощи тегов. Пусть это будут XML-теги:
F000?C000:0F00,00FF=<popup item="%d" color="%d"/>
Уже гораздо лучше:
Obtained an item!<popup item="1" color="255"/>
Now you can open the door.
Но ещё лучше было бы, если бы вместо «магических констант» мы видели текстовое представление параметров. Для этого я ввёл возможность объявления перечислений в виде:
%{<member1>[=value],<member2>[=value],...}
Допустим, такая инструкция применяется только для трёх предметов: бомбы с номером 0, ключа с номером 1 и монеты с номером 10:
F000?C000:0F00,00FF=<popup item="%{Bomb,Key,Coin=10}" color="#%2x"/>
Как видно, заодно и для цвета я применил более привычную запись. Конечно, глупо поступать таким образом с восьмибитным представление цвета, но это лишь пример, взятый из головы для наглядности.
Дальше нам остаётся только включить подсветку тегов и можем получить более-менее читабельный текст:
Obtained an item!<popup item="Key" color="#0F"/> Now you can open the door.
Если семантика инструкций не так важна (т.е. перевод не подразумевает их редактирования), то лучше прибегнуть к более краткой записи, а то в некоторых местах кода может получиться больше, чем текста. Например, так:
Obtained an item!{popup:Key,0F}
Now you can open the door.
Для инструкций с ровно одним параметром я предусмотрел укороченную форму записи. Ниже следует две эквивалентных по смыслу строки:
FF00?3C00:00FF=<pause time="%d"> 3C??=<pause time="%d">
Как видно из записи, вопросительными знаками я выделил биты параметра, остальные биты считаются единичными битами маски, а идентификатор получается путём замены вопросительных знаков на нули. К сожалению, такая запись возможна только для инструкций, где размеры параметра и идентификатора кратны четырём битам, т.е. размеру одного шестнадцатеричного символа.
Представление текста
 Это одна из самых важных частей процесса, потому что извлечённый текст попадёт прямиком к переводчикам, и от того, насколько он опрятен, зависит не только продуктивность их работы, но и количество структурных и семантических ошибок, которые они допустят. По сути этот процесс — доработка механизма извлечения текста таким образом, чтобы максимально упростить работу переводчиков.
Это одна из самых важных частей процесса, потому что извлечённый текст попадёт прямиком к переводчикам, и от того, насколько он опрятен, зависит не только продуктивность их работы, но и количество структурных и семантических ошибок, которые они допустят. По сути этот процесс — доработка механизма извлечения текста таким образом, чтобы максимально упростить работу переводчиков.Если рассматривать описанный в предыдущем пункте текст, то для переводчика достаточно краткого экскурса о назначении тегов и прочей белиберды, особо его напугать ничего не должно. Но, надо заметить, что основной, на мой взгляд, ошибкой в представлении текста является зашкаливающее количество технической информации. У большинства дилетантов такой текст выглядел бы совсем по-другому:
Jenica: I've served in this castle for quite^
some time. I looked after both Princess^
Lenna and Princess Sarisa.^{CLS}
[#C2][#A5][#C2][#B3]: Sarisa?^{CLS}[#C3][#91]
Jenica: Princess Lenna's older sister.^
Sarisa was sailing with her father when^
a storm hit, and she was lost at sea.{END}
На месте переводчика я бы сказал: «и как прикажете это переводить?»
Увы, судя по обрывочным сведениям, такое встречается и в процессе официальных локализаций: вот дадут текст в формате XML или INI с «\n» в качестве переноса строк, и переводи как хочешь. При этом многие люди даже в таких случаях не изменяют Word'у, который какой-нибудь автозаменой способен убить структуру практически любого подобного формата или ещё чего хуже.
Это, конечно же, запросто может быть чревато тотальными ошибками, ибо обычно весь контроль качества производится вручную, несмотря на простор для его автоматизации. Как-то раз у «коллег» в релиз укатился очень крупный перевод без единого тире — все их молча скушал Word, подменив на «правильные», которые конвертору текста были не знакомы.
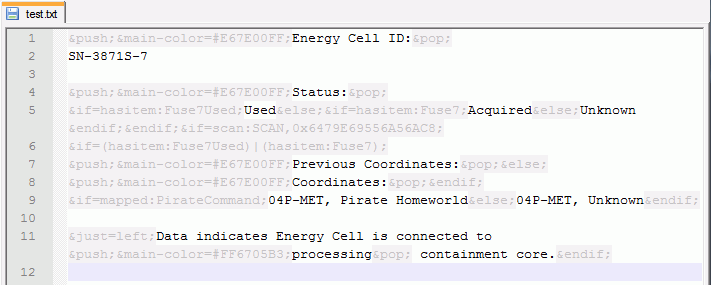
К сожалению, порой от трудно читаемого текста не спасает ничего. К тому же, в некоторых играх теги не компилируются в байткод, а так и хранятся в текстовом виде, т.е. игра обрабатывает их при выводе текста. Да что там говорить, вот вам пример:
&push;&main-color=#E67E00FF;Energy Cell ID:&pop;
SN-3871S-7
&push;&main-color=#E67E00FF;Status:&pop;
&if=hasitem:Fuse7Used;Used&else;&if=hasitem:Fuse7;Acquired&else;Unknown&endif;&endif;&if=scan:SCAN,0x6479E69556A56AC8;
&if=(hasitem:Fuse7Used)|(hasitem:Fuse7);
&push;&main-color=#E67E00FF;Previous Coordinates:&pop;&else;
&push;&main-color=#E67E00FF;Coordinates:&pop;&endif;
&if=mapped:PirateCommand;04P-MET, Pirate Homeworld&else;04P-MET, Unknown&endif;
&just=left;Data indicates Energy Cell is connected to &push;&main-color=#FF6705B3;processing&pop; containment core.&endif;
Согласитесь, глаза сломать можно, что уж говорить о неустойчивости к ошибкам (легко сделать, трудно заметить). Выходом из ситуации мог бы послужить WYSIWYG-редактор, или, по крайней мере, конвертация текста в формат любого такого редактора и последующая конвертация обратно. Но это довольно дорогостоящее (в плане человекочасов) решение, да и от тегов и инструкций оно не сильно-то и спасает.
Раньше я пытался производить декомпозицию (разделение на две сущности) текста и других данных настолько, насколько позволяет конкретный случай. Например, теги можно группировать, заменяя на один тег вроде «{code}» или «{<group_number>}», при этом вынося в отдельный файл. Но, поскольку теги тесно связаны с текстом, да и головной боли от такого решения только прибавляется, я впоследствии от этого отказался.
Но какой-никакой выход всё-таки нашёлся, и заключается он в подсветке синтаксиса. Т.к. все технические данные обычно легко обрабатываются автоматически, то и выделить их среди остального текста тоже не проблема.
Для этих целей я использовал возможности всем известного Notepad++ — в нём есть инструмент для создания своего механизма подсветки. Мне повезло с тем, что переводчик, с которым я работал, сам использовал Notepad++, поэтому уговаривать никого не пришлось. Несмотря на ограниченность в создании правил подсветки, этой возможности оказалось вполне достаточно, хоть и приходилось порой прибегать к разнообразным костылям.
С этим уже вполне можно жить. А иногда я заходил ещё дальше и писал визуализаторы — программы, которые отображали текст так же, как бы он выглядел в игре. Ну, или почти так же…
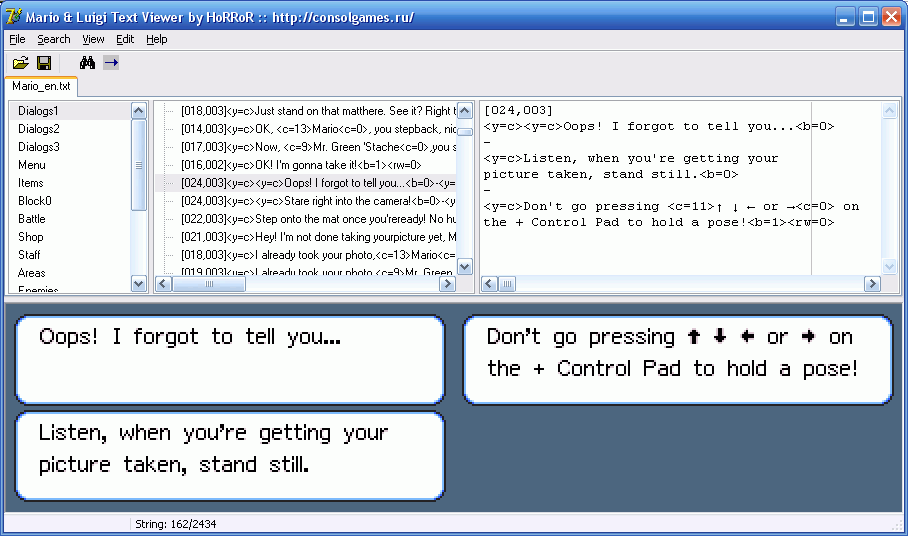
Впрочем, это обычно касалось случаев, когда необходим был жёсткий контроль качества на предмет корректного вывода текста в диалоговых окнах. А гораздо проще контролировать это ещё на этапе перевода, чем потом отлавливать тысячи косяков, связанных с выходом текста за отведённые ему рамки. Хорошо, что во многих играх всё же существует автоперенос.
Продолжение следует
В следующих частях читайте:
- Разбор алгоритмов — о том, какими методами определяются алгоритмы, производными которых являются исследуемые данные.
- Перерисовка шрифтов — о разнообразии способов хранения и использования графического представления символов, а также о методах их обработки и редактирования.
- Перевод графики — про способы кодирования, сжатия и оптимизации графики на различных платформах и о том, как с этим работают.
- Озвучка — немного информации об особенностях работы со звуком и о том, как некоторые переводчики делают озвучку «на коленке».
- Перевод видеороликов — секреты любительского видеомонтажа и работы с кодированием видеопотоков в немного нестандартных примерах.
- Сборка перевода — будут рассмотрены подходы к организации проектов и способы компиляции всех данных в готовый для использования вид.
- Тестирование — про тяжёлый, но приятный труд исследователей виртуальных миров на фронте контроля качества перевода.
- Дистрибьюция — в каком виде распространяют переводы, как распространяют, что для этого делают и кому это в итоге нужно.
