Джефф Прешинг (Jeff Preshing) опубликовал отличную демонстрацию, как нормальный код C++ возвращает непредсказуемый результат на многоядерных процессорах со слабо упорядоченной обработкой очереди запросов (Weakly-Ordered CPU), то есть на ARM-процессорах. Например, на iPhone или каком-нибудь современном Android-устройстве.
Простая программа C++ с двумя потоками 20.000.000 раз прибавляет единичку к значению, защищённому мьютексом, — и каждый раз на выходе получается разный результат, который меньше 20.000.000!
Как говорится, наш враг — CPU.
В своём блоге Джефф Прешинг опубликовал много статей о lock-free программировании, методах неблокирующей синхронизации потоков. В том числе он много говорил об использовании блокировки с двойной проверкой и необходимости ставить барьеры памяти. Сейчас Джефф решил, что одна демонстрация лучше тысячи слов.
Код демонстрационной программы, в которой каждый из двух потоков по 10.000.000 раз прибавляет единичку к общему значению
Вот как выглядит самодельный мьютекс: простейший семафор, который принимает значение 1, если он занят, или 0, если свободен.
Использование аргументов
В своей программе Джефф умышленно убрал аргументы
Вот что генерирует XCode.
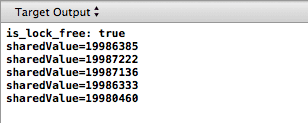
Результат запуска программы на iPhone уже показывался.
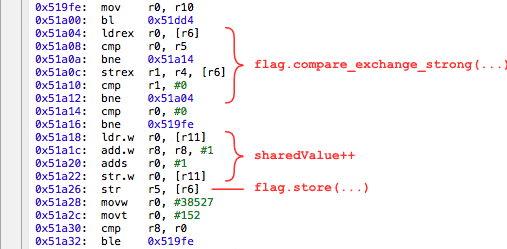
Из-за чего такое происходит? Дело в том, что процессоры со слабо-упорядоченной обработкой (Weakly-Ordered CPU) могут оптимизировать очередь запросов, так что ваши инструкции будут выполнять не в том порядке, в котором вы думали. Например, на диаграмме показано, как два потока из вышеприведённого примера на разных CPU используют общий мьютекс для изменения значения
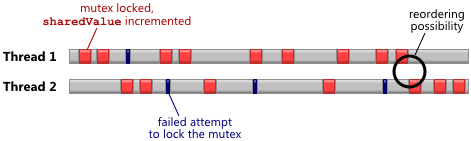
Красным цветом показаны успешные попытки заблокировать мьютекс и изменить значение, чёрным штрихом — неудачные попытки обратиться к мьютексу, который заблокирован другим потоком. Тот момент, когда один поток только освободил мьютекс, а второй готов его заблокировать, — этот момент лучше всего подходит для переупорядочивания очереди запросов, с точки зрения CPU.
Почему CPU осуществляет переупорядочивание очереди запросов, это тема отдельной статьи. Бороться с этим нужно установкой барьеров памяти, которые разделяют пару соседних инструкций и гарантируют, что они не поменяются местами. Вот для чего нужны аргументы
Компилятор в этом случае вставляет инструкции
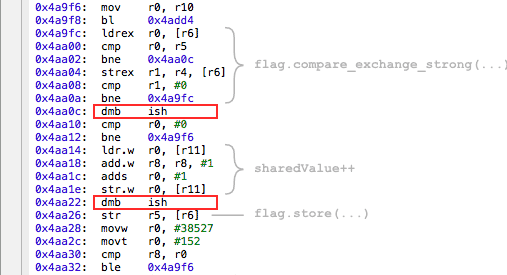
И тогда мьютекс уже начинает нормально выполнять свою работу и надёжно защищать общее значение
Сейчас мы столкнулись с массовым использованием Weakly-Ordered процессоров. Раньше они использовались только в серверах или в высокопроизводительных «маках» прошлого, где были многоядерные PowerPC. Сейчас многоядерные ARM — в каждом мобильном телефоне. Так что этот нюанс нужно учитывать при разработке мобильных приложений.
В «специально глючном» коде Прешинга вероятность ошибки составляет 1 к 1000, а в обычной программе она будет 1 к 1.000.000, то есть такие глюки чрезвычайно трудно выловить на тестировании. Программа может работать идеально 999.999 раз, а при следующем запуске произойдёт сбой.
Простая программа C++ с двумя потоками 20.000.000 раз прибавляет единичку к значению, защищённому мьютексом, — и каждый раз на выходе получается разный результат, который меньше 20.000.000!
Как говорится, наш враг — CPU.
В своём блоге Джефф Прешинг опубликовал много статей о lock-free программировании, методах неблокирующей синхронизации потоков. В том числе он много говорил об использовании блокировки с двойной проверкой и необходимости ставить барьеры памяти. Сейчас Джефф решил, что одна демонстрация лучше тысячи слов.
Код демонстрационной программы, в которой каждый из двух потоков по 10.000.000 раз прибавляет единичку к общему значению
sharedValue, защищённому мьютексом.Вот как выглядит самодельный мьютекс: простейший семафор, который принимает значение 1, если он занят, или 0, если свободен.
int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) { // The lock succeeded }
Использование аргументов
memory_order_acquire и memory_order_release кому-то может показаться излишним, но это необходимая гарантия, что пара тредов скоординированно меняют значение семафора.flag.store(0, memory_order_release);
В своей программе Джефф умышленно убрал аргументы
memory_order_acquire и memory_order_release для демонстрации, к чему это может привести:void IncrementSharedValue10000000Times(RandomDelay& randomDelay) { int count = 0; while (count < 10000000) { randomDelay.doBusyWork(); int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_relaxed)) { // Lock was successful sharedValue++; flag.store(0, memory_order_relaxed); count++; } } }
Вот что генерирует XCode.
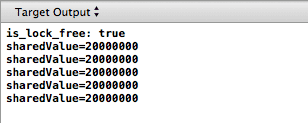
Результат запуска программы на iPhone уже показывался.
Из-за чего такое происходит? Дело в том, что процессоры со слабо-упорядоченной обработкой (Weakly-Ordered CPU) могут оптимизировать очередь запросов, так что ваши инструкции будут выполнять не в том порядке, в котором вы думали. Например, на диаграмме показано, как два потока из вышеприведённого примера на разных CPU используют общий мьютекс для изменения значения
sharedValue. Красным цветом показаны успешные попытки заблокировать мьютекс и изменить значение, чёрным штрихом — неудачные попытки обратиться к мьютексу, который заблокирован другим потоком. Тот момент, когда один поток только освободил мьютекс, а второй готов его заблокировать, — этот момент лучше всего подходит для переупорядочивания очереди запросов, с точки зрения CPU.
Почему CPU осуществляет переупорядочивание очереди запросов, это тема отдельной статьи. Бороться с этим нужно установкой барьеров памяти, которые разделяют пару соседних инструкций и гарантируют, что они не поменяются местами. Вот для чего нужны аргументы
memory_order_acquire и memory_order_release. Возвращаем их на место.void IncrementSharedValue10000000Times(RandomDelay& randomDelay) { int count = 0; while (count < 10000000) { randomDelay.doBusyWork(); int expected = 0; if (flag.compare_exchange_strong(expected, 1, memory_order_acquire)) { // Lock was successful sharedValue++; flag.store(0, memory_order_release); count++; } } }
Компилятор в этом случае вставляет инструкции
dmb ish, которые работают как барьеры памяти в ARMv7.И тогда мьютекс уже начинает нормально выполнять свою работу и надёжно защищать общее значение
sharedValue.Сейчас мы столкнулись с массовым использованием Weakly-Ordered процессоров. Раньше они использовались только в серверах или в высокопроизводительных «маках» прошлого, где были многоядерные PowerPC. Сейчас многоядерные ARM — в каждом мобильном телефоне. Так что этот нюанс нужно учитывать при разработке мобильных приложений.
В «специально глючном» коде Прешинга вероятность ошибки составляет 1 к 1000, а в обычной программе она будет 1 к 1.000.000, то есть такие глюки чрезвычайно трудно выловить на тестировании. Программа может работать идеально 999.999 раз, а при следующем запуске произойдёт сбой.
