Comments 18
Очень крутые посты, спасибо большое.
К чему этот подъездный сленг? Только портит статью, ИМХО.
> И есть у меня ощущение, что много там автоматики в построении архитектуры, но они пока не палятся.
Согласен. Вот что они пишут в первой статье про Inception: «This suggest promising future work towards creating sparser and more refined structures in automated ways».
Больше всего печалит, что Imagenet challenge сейчас доступен только для компаний типа гугла. Побеждающие алгоритмы — усреднения по 10-20 разным сетям, каждая из которых обучалась с неделю на распределенном кластере из десятков машин. Ну и как с этим соперничать какой-нибудь университетской лабе? Как мне кажется, единственный вариант тут — это что-то принципиально новое. Любопытно выглядит recurrent visual attention, что-то вроде [1]. В теории, можно очень сильно уменьшить количество вычислений. На практике все как обычно. Я сейчас как раз над этим работаю, если интересно — запилю пост, как будут какие-то вменяемые результаты на imagenet-е.
Согласен. Вот что они пишут в первой статье про Inception: «This suggest promising future work towards creating sparser and more refined structures in automated ways».
Больше всего печалит, что Imagenet challenge сейчас доступен только для компаний типа гугла. Побеждающие алгоритмы — усреднения по 10-20 разным сетям, каждая из которых обучалась с неделю на распределенном кластере из десятков машин. Ну и как с этим соперничать какой-нибудь университетской лабе? Как мне кажется, единственный вариант тут — это что-то принципиально новое. Любопытно выглядит recurrent visual attention, что-то вроде [1]. В теории, можно очень сильно уменьшить количество вычислений. На практике все как обычно. Я сейчас как раз над этим работаю, если интересно — запилю пост, как будут какие-то вменяемые результаты на imagenet-е.
Пардон, забыл добавить ссылку.
[1] https://arxiv.org/abs/1502.04623
[1] https://arxiv.org/abs/1502.04623
Конечно интересно, пиши обязательно.
Насчет ImageNet да, чего-то прорывного и быстросходящегося пока не придумали… но, например, для физиономий пацаны из Google/Facebook тренировались десяткаях и сотнях миллионов картинок, а потом до задачи идентификации лиц дотунялись руки у Андрея Зисермана и он уделал всех, натренировавшись на базе всего из ~1 миллиона изображений лиц…
Это вы про какую работу? Последнее, что я читал из face recognition — DeepFace от фейсбука. Подозреваю, что за два года там много чего поменялось.
Про Deep Face Recognition от чуваков из VGG. Работа уже старенькая, но результаты впечатляют, учитывая разницу в размере датасетов. Наглядный пример того, как университетская исследовательская группа уделала IT-гигантов… хотя, это скорей исключение из правил)
Я тут случайно прочитал статью про VGGFace, и там таки 2.6 мильена! И он уделал не во всех бенчрмарках. Но все равно показательный результат, конечно.
У Джеффа Хокинса в «Об Интеллекте» есть такая мысль, что в процессе обучения высокоуровневая функция, типа распознавания слов может сместиться из более высокого слоя сети в более низкий. Это как учимся читать сначала по буквам, складывая буквы в слова, а с накоплением опыта начинаем читать слово сразу.
Возможно, как дополнительный бонус, identity-слои сделают возможным такое поведение, «дав функциям пространство для манёвра», когда один слой склеивается с другим, оставляя на своём прежнем месте identity. Впрочем, механизм такого перемещения я себе не представляю.
Возможно, как дополнительный бонус, identity-слои сделают возможным такое поведение, «дав функциям пространство для манёвра», когда один слой склеивается с другим, оставляя на своём прежнем месте identity. Впрочем, механизм такого перемещения я себе не представляю.
А какие перспективы у ResNet-1001 и выше относительно Inception-v4 и Inception-ResNet-2?
ResNet-1001 на https://arxiv.org/abs/1603.05027
Современные сети типа Inception-v4 и Inception-ResNet-2 как-то учитывают, что большинство объектов могут изменяться не сильнее, чем эластичная трансформация (перспективная трансформация + изгибы ...) или даже чем жесткая перспективная трансформация (повороты, сдвиги, изменение масштаба и изменение перспективы) — то что активно использовалось в Feature-based алгоритмах для Representation Learning?
Например, насколько разными для сети будут эти 2 изображения, на которых все features повернуты и наклонены, и взаимное расположение этих features повернуто и наклонено?


ResNet-1001 на https://arxiv.org/abs/1603.05027
Современные сети типа Inception-v4 и Inception-ResNet-2 как-то учитывают, что большинство объектов могут изменяться не сильнее, чем эластичная трансформация (перспективная трансформация + изгибы ...) или даже чем жесткая перспективная трансформация (повороты, сдвиги, изменение масштаба и изменение перспективы) — то что активно использовалось в Feature-based алгоритмах для Representation Learning?
Например, насколько разными для сети будут эти 2 изображения, на которых все features повернуты и наклонены, и взаимное расположение этих features повернуто и наклонено?
Сверх-глубокие сети на 1000+ слоев пока не получается тренировать на картинках разрешения тех, что в ImageNet (тупо не тянет железо), поэтому сравнивать их с описанными решениями тяжело. Их тренируют на CIFAR-10 и CIFAR-100, где картинки 32x32.
Про трансформации — непосредственно в архитектурах зашита только устойчивость к сдвигу (из-за того как работают convolution layers), устойчивости к остальным трансформациями люди добиваются так называемым augmentation — т.е. создают новые тренировочные картинки из старых и учат сеть на них тоже. Чем меньше данных для обучения, тем более важным становится augmentation.
Про трансформации — непосредственно в архитектурах зашита только устойчивость к сдвигу (из-за того как работают convolution layers), устойчивости к остальным трансформациями люди добиваются так называемым augmentation — т.е. создают новые тренировочные картинки из старых и учат сеть на них тоже. Чем меньше данных для обучения, тем более важным становится augmentation.
Сверх-глубокие сети на 1000+ слоев пока не получается тренировать на картинках разрешения тех, что в ImageNet (тупо не тянет железо), поэтому сравнивать их с описанными решениями тяжело. Их тренируют на CIFAR-10 и CIFAR-100, где картинки 32x32.
Хм, а в чем там проблема? Неужели даже 1 картинка не влазит в память для прямого/обратного прохода? А под батч >1 картинки масштабировать за счет кучи GPU устройств. Вроде бы в статьях обычно пишут аля "на ImageNet мы еще не успели посчитаться, да и лень нам, т.ч. вот результаты на CIFAR", при этом вроде бы железо теоретически позволяет параллелить:)
Предполагаю, что Inception-сети оптимальнее по соотношению скорость/качество, чем MSRA ResNet. Т.е. если есть достаточно вычислительных мощностей, то добивая ещё слоев в Inception-сеть и сравняв по скорости с ResNet-1001 мы получим меньше ошибок на Inception.
Ещё помимо времени обучения есть time limit в процессе самого распознования. Например Amax, которая тоже победила в нескольких категориях на ImageNet 2015, пишет следующее в категории «Task 3b: Object detection from video with additional training data»:
http://image-net.org/challenges/LSVRC/2015/results#vid
Можно параллелить батчи при обучении на множество GPU.
Например, на nVidia DGX-1 из 8 x P100 можно обучить AlexNet примерно в 4 раза быстрее, чем на 1 x P100.
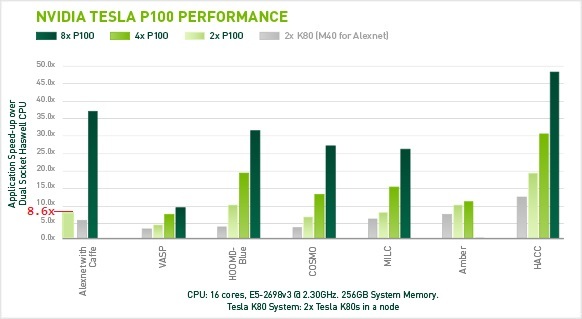
Но DGX-1 вышел только месяц назад и в нем впервые для лучшей масштабируемости используется nvLink со скоростью обмена на 1 чип до 80 GB/s, что в 5 раз быстрее, чем 16 GB/s (PCIe 3.0 16x). Плюс сам P100 быстрее на 40%, чем предыдущая GPU M40.
Интересно за сколько на DGX-1 обучиться сеть на ResNet-1001 для FasterRCNN обнаружения объектов?
Ещё помимо времени обучения есть time limit в процессе самого распознования. Например Amax, которая тоже победила в нескольких категориях на ImageNet 2015, пишет следующее в категории «Task 3b: Object detection from video with additional training data»:
only half of the videos are tracked due to deadline limits, others are only detected by Faster RCNN (VGG16) without tempor smooth.
http://image-net.org/challenges/LSVRC/2015/results#vid
Можно параллелить батчи при обучении на множество GPU.
Например, на nVidia DGX-1 из 8 x P100 можно обучить AlexNet примерно в 4 раза быстрее, чем на 1 x P100.
Но DGX-1 вышел только месяц назад и в нем впервые для лучшей масштабируемости используется nvLink со скоростью обмена на 1 чип до 80 GB/s, что в 5 раз быстрее, чем 16 GB/s (PCIe 3.0 16x). Плюс сам P100 быстрее на 40%, чем предыдущая GPU M40.
Интересно за сколько на DGX-1 обучиться сеть на ResNet-1001 для FasterRCNN обнаружения объектов?
А какой минимальной глубины должна быть ResNet с accuracy как у AlexNet?
Sign up to leave a comment.
Эволюция нейросетей для распознавания изображений в Google: Inception-ResNet