Задача
Привет, Хабр! Увлёкся я навыками для Алисы и стал думать, какую пользу они бы могли принести. На площадке много разных прикольных игр (в том числе мои), но вот захотелось сделать рабочий инструмент, который действительно нужен в голосовом исполнении, а не просто копирует существующего чат-бота с кнопками.
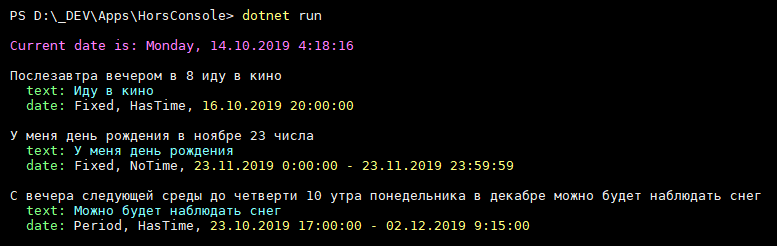
Голос актуален тогда, когда либо руки заняты, либо нужно выполнять много последовательных операций, особенно на экране телефона. Так возникла идея навыка, который по одной команде выделяет из текста указание на дату и время и добавляет событие с этим текстом в Google Calendar. Например, если пользователь скажет Послезавтра в 11 вечера будет красивый закат, то в календарь на послезавтра в 23:00 уходит строка Будет красивый закат.
Под катом описание алгоритма работы библиотеки Hors: распознавателя даты и времени в естественной русской речи. Хорс — это славянский бог солнца.
Существующие решения
dateparser на Python
Заявлена поддержка русского языка, но на русском библиотека не справляется даже с базовыми вещами:
>>> import dateparser
>>> dateparser.parse(u'13 января 2015 г. в 13:34')
datetime.datetime(2015, 1, 13, 13, 34)
>>> dateparser.parse(u'через неделю')
>>> dateparser.parse(u'в следующий четверг в 9 вечера')
>>> dateparser.parse(u'13 октября')
datetime.datetime(2019, 10, 13, 0, 0)
>>> dateparser.parse(u'13 октября в 9 вечера')chronic на Ruby
Известная рубистам библиотека, которая, говорят, делает свою работу отлично. Но поддержка русского не обнаружена.
Google Assistant
Раз мы говорим о добавлении в Google Calendar голосом, спрашивается, а почему бы не воспользоваться Ассистентом? Можно, но идея проекта в том, чтобы делать работу одной фразой без лишних телодвижений и нажатий. И чтобы делать это надёжно. В Ассистенте пока есть проблемы с этим:

Предустановки
Я писал библиотеку на .NETStandard 2.0 (C#). Поскольку изначально библиотека делалась под Алису, то все числительные в тексте полагаются именно числами, потому что Алиса делает такое преобразование автоматически. Если у вас числительные строками, то здесь есть замечательная статья пользователя Doomer3D о том, как превращать слова в числа.
Морфология
При работе с голосовым вводом самым надёжным способом отличать правильные слова от неправильных является использование словоформ. Подробнее мы с другом говорили об этом в видеоуроке для Школы Алисы от Яндекса. В данной же статье я оставлю за кадром работу со словоформами. В коде будут встречаться вот такие конструкции:
Morph.HasOneOfLemmas(t, "прошлый", "прошедший", "предыдущий");Эта функция возвращает true, если слово t является любой формой одного из трёх последующих слов, например: прошлого, прошедшие, предыдущих.
Теория
Чтобы понять, как вылавливать в тексте даты, нужно перечислить типовые фразы, которые мы используем для обозначения дат в реальных беседах. Например:
— завтра пойду гулять
— завтра вечером пойду гулять
— в следующий четверг иду в кино
— в следующий четверг в 9 вечера иду в кино
— 21 марта в 10 утра совещание
Мы видим, что слова в целом делятся на три вида:
- Те, которые всегда относятся к датам и времени (названия месяцев и дней)
- Те, которые относятся к дате и времени при определённом положении относительно других слов ("день", "вечер", "следующий", числа)
- Те, которые никогда не относятся к дате и времени
С первыми и последними всё понятно, но со вторыми есть сложности. Изначальная версия алгоритма была ужасным спагетти-кодом с большим числом if, потому что я пытался учесть все возможные комбинации и перестановки нужных мне слов, но потом придумал вариант получше. Дело в том, что человечество уже изобрело систему, позволяющую быстро и просто учитывать перестановки и комбинации символов: движок регулярных выражений.
Готовим строку
Разобьём строку на токены, убрав знаки препинания и приведя всё к нижнему регистру. После чего заменим каждый непустой токен на какой-то единичный символ, чтобы работать с регулярными выражениями было проще.
| Токен (слово) | Символ, на который заменяем |
|---|---|
| "год" | Y |
| название месяца | M |
| название дня недели | D |
| "назад" | b |
| "спустя" | l (lower L) |
| "через" | i |
| "выходной" | W |
| "минута" | e |
| "час" | h |
| "день" | d |
| "неделя" | w |
| "месяц" | m |
| "прошлый", "прошедший", "предыдущий" | s |
| "этот", "текущий", "нынешний" | u |
| "ближайший", "грядущий" | y |
| "следующий", "будущий" | x |
| "послезавтра" | 6 |
| "завтра" | 5 |
| "сегодня" | 4 |
| "вчера" | 3 |
| "позавчера" | 2 |
| "утро" | r |
| "полдень" | n |
| "вечер" | v |
| "ночь" | g |
| "половина" | H |
| "четверть" | Q |
| "в", "с" | f |
| "до", "по" | t |
| "на" | о |
| "число" | # |
| "и" | N |
| число больше 1900 и меньше 9999 | 1 |
| неотрицательное число меньше 1901 | 0 |
| уже обработанная алгоритмом дата | @ |
| любой другой токен | _ |
Вот что получается для строк, которые мы упоминали:
| Строка | Результат |
|---|---|
| завтра пойду гулять | 5__ |
| завтра вечером пойду гулять | 5v__ |
| в следующий четверг иду в кино | fxD_f_ |
| в следующий четверг в 9 вечера иду в кино | fxDf0v_f_ |
| 21 марта в 10 утра совещание | 0Mf0r_ |
Распознавание
— О, ужас! — скажете вы, — Стало только хуже! Такую абракадабру и человек понять не сможет. Да, пришлось пойти на некоторый компромисс между удобством чтения человеком и удобством работы с регулярками, ниже увидите, как именно.
Дальше применяем паттерн, который называется цепочка обязанностей: входной массив данных подаётся последовательно в разные обработчики, которые могут его менять или не менять и передавать дальше. Обработчик я назвал Recognizer и сделал по такому обработчику на каждый вариант типовой (как мне показалось) фразы, относящейся к дате и времени.
Recognizer ищет заданный regex-паттерн в строке и запускает для каждого найденного соответствия функцию обработки, которая может изменять входную строку и добавлять пойманные даты в специальный массив.
Причем, обработчики нужно вызывать в правильном порядке: от более "уверенных" к менее. Например, в самом начале нужно запустить обработчики, связанные со "строгими" словами, которые точно относятся к датам: названия дней, месяцев, слова вроде "завтра", "послезавтра" и так далее. А в конце обработчики, которые пытаются по необработанным остаткам определить, а может ли там быть ещё что-то, связанное с датой.
Например:
Число и месяц
"((0N?)+)(M|#)"; // 24, 25, 26... и 27 января/числаТут начинает проявляться прелесть применения регулярных выражений. Достаточно простым образом мы обозначили сложную последовательность токенов: ненулевое количество неотрицательных чисел меньше 1901 идут друг за другом, возможно, разделяясь союзом "и", а за ними идёт либо название месяца, либо слово "число".
Причем, в мэтч-группы мы сразу ловим конкретные элементы, если они есть, и не ловим, если их нет, и из этого набора составляем конечную дату. В коде ниже будет пока что непонятный участок, связанный с функциями Fix, FixPeriod, к этому мы перейдем в конце статьи.
Промежуток времени
"(i)?((0?[Ymwdhe]N?)+)([bl])?";
// (через) год и месяц и 2 дня 4 часа 10 минут (спустя/назад)Тут важно отметить, что иногда просто факт совпадения с регуляркой недостаточен, и нужно ещё добавлять какую-то логику в обработчик. Хотя, можно было сделать на такие случаи два отдельных обработчика, но мне показалось это излишеством. В итоге я мэтчу и начальное "через" и конечное "спустя/назад", но код обработчика начинается с проверки:
if (match.Groups[1].Success ^ match.Groups[4].Success)Где ^ это исключающее ИЛИ.
Кстати, для работы таких вот функций в движок нужно передавать текущую дату пользователя.
Год
"(1)Y?|(0)Y"; // [в] 15 году/2017 (году)Не могу ещё раз не отметить удобство подхода с регулярками. Опять же простым выражением мы обозначали сразу варианты: пользователь называет число, похожее на год, но без слова "год", либо пользователь называет двузначное число (которое может быть и датой), но добавляет слово "год", и появляется поддержка выражений "в 18 году", впрочем, имеется ли ввиду 1918 или 2018 мы не знаем, поэтому полагаем, что 2018.
Время
"([rvgd])?([fot])?(Q|H)?(h|(0)(h)?)((0)e?)?([rvgd])?";
// (в/с/до) (половину/четверть) час/9 (часов) (30 (минут)) (утра/дня/вечера/ночи)Самое сложное выражение в моей подборке отвечает за варианты фраз для обозначения времени суток, от строгой в 9 часов 30 минут до четверть 11 вечера
Все обработчики в порядке применения
Система модульная, подразумевается, что можно добавлять/удалять обработчики, менять их порядок и так далее. Я сделал 11 таких (сверху вниз в порядке применения):
| Обработчик | Regex | Пример строки |
|---|---|---|
| HolidaysRecognizer.cs 1 | W |
выходной, выходные |
| DatesPeriodRecognizer.cs | f?(0)[ot]0(M|#) |
с 26 до 27 января/числа |
| DaysMonthRecognizer.cs | ((0N?)+)(M|#) |
24, 25, 26… и 27 января/числа |
| MonthRecognizer.cs | ([usxy])?M |
[в] (прошлом/этом/следующем) марте |
| RelativeDayRecognizer.cs | [2-6] |
позавчера, вчера, сегодня, завтра, послезавтра |
| TimeSpanRecognizer.cs | (i)?((0?[Ymwdhe]N?)+)([bl])? |
(через) год и месяц и 2 дня 4 часа 10 минут (спустя/назад) |
| YearRecognizer.cs | (1)Y?|(0)Y |
[в] 15 году/2017 (году) |
| RelativeDateRecognizer.cs | ([usxy])([Ymwd]) |
[в/на] следующей/этой/предыдущей год/месяц/неделе/день |
| DayOfWeekRecognizer.cs | ([usxy])?(D) |
[в] (следующий/этот/предыдущий) понедельник |
| TimeRecognizer.cs | ([rvgd])?([fot])?(Q|H)?(h|(0)(h)?)((0)e?)?([rvgd])? |
(в/с/до) (половину/четверть) час/9 (часов) (30 (минут)) (утра/дня/вечера/ночи) |
| PartOfDayRecognizer.cs | (@)?f?([ravgdn])f?(@)? |
(дата) (в/с) утром/днём/вечером/ночью (в/с) (дата) |
1 Этот обработчик заменяет слово "выходной" на "суббота" и "выходные" на "суббота и воскресенье", чтобы передать обработчику по названию дней
Сшиваем воедино
Окей, мы определили некоторые элементарные токены даты-времени. Но теперь нам ещё нужно каким-то образом учесть все комбинации всех видов токенов: пользователь может сначала назвать день, а потом время. Или назвать месяц и день. Если он скажет только время, то, вероятно, речь идёт про сегодня, и так далее. Для этого придумаем концепцию фиксации.
Фиксация в нашем случае — это битовая маска внутри каждого токена даты-времени, которая показывает, какие элементы даты и времени в нём заданы.
public enum FixPeriod
{
None = 0,
Time = 1,
TimeUncertain = 2,
Day = 4,
Week = 8,
Month = 16,
Year = 32
}TimeUncertain — фиксация для обозначения времени, после которого может следовать уточнение, например вечера/утра. Нельзя сказать 18 часов утра, но можно сказать 6 вечера, поэтому число 6 обладает как бы меньшей "уверенностью" в том, какое время оно обозначает, чем число 18.
| Фраза | Фиксация | Маска |
|---|---|---|
| 26 марта 2019 года | год, мес, нед, ден, врм1, врм2 | 111100 |
| 26 числа | год, мес, нед, ден, врм1, врм2 | 000100 |
| понедельник | год, мес, нед, ден, врм1, врм2 | 000100 |
| следующий понедельник | год, мес, нед, ден, врм1, врм2 | 111100 |
| на следующей неделе | год, мес, нед, ден, врм1, врм2 | 111000 |
| в 9 часов | год, мес, нед, ден, врм1, врм2 | 000010 |
| в 9 часов вечера | год, мес, нед, ден, врм1, врм2 | 000011 |
Дальше воспользуемся двумя правилами:
- Если даты стоят рядом, и у них нет общих битов, то мы объединяем их в одну
- Если даты стоят рядом, и мы их не объединили, но при этом у одной из них есть биты, которых нет у второй, то мы занимаем биты (и соответствующие им значения) у той, где они есть, в ту, где их нет, но только в бОльшую сторону: то есть мы не можем занять день, если задан только месяц, но можем занять месяц, если задан только день.

Таким образом, если пользователь говорит в понедельник в 9 вечера, то токен в понедельник, где задан только день, объединяется с токеном в 9 вечера, где задано время. Но если он скажет в марте 10 и 15 числа, то последний токен 15 числа просто займёт месяц март у предыдущего токена.
Объединение тривиально, а с заимствованием поступим просто. Будем называть базовой дату, для которой мы занимаем, и второстепенной вторую, у которой мы хотим что-то занять. Затем скопируем второстепенную дату и оставим только те биты, которых нет у базовой:
var baseDate = data.Dates[firstIndex];
var secondDate = data.Dates[secondIndex];
var secondCopy = secondDate.CopyOf();
secondCopy.Fixed &= (byte)~baseDate.Fixed;Например, если у базовой был год, мы не будем у копии второстепенной оставлять фиксацию года (даже если он был). Если у базовой не было месяца, а у второстепенной есть — он останется у копии второстепенной. После этого проводим процесс объединения базовой даты и копии второстепенной.
При объединении у нас тоже есть базовая дата и поглощаемая. Идём сверху вниз от самого большого периода (год) до самого маленького (время). Если у базовой даты нет какого-то параметра, который есть у поглощаемой, мы добавляем его в базовую из поглощаемой.
Отдельно нужно учесть пару нюансов:
- У базовой даты может быть зафиксирован день, но не зафиксирована неделя. В таком случае нужно взять неделю из поглощаемой даты, но сам день недели из базовой.
- Однако, если у поглощаемой даты не зафиксирован день, но зафиксирована неделя, нам нужно взять из неё день (то есть год+месяц+число) и задать таким способом неделю, потому что отдельной сущности "Неделя" в объекте
DateTimeнет. - Если у базовой даты зафиксировано
TimeUncertain, а у поглощаемойTime, и при этом у поглощаемой количество часов больше 12, а у базовой меньше, то к базовой нужно прибавить 12 часов. Потому что нельзя сказать с 5 до 17 вечера. Время "неуверенной" даты не может быть из одной половины дня, если время "уверенной" даты рядом с ней — из другой половины дня. Люди так не говорят. Если же мы сказали фразу с 5 утра до 17, то здесь обе даты обладают "уверенным" временем, и проблемы не возникает.
После объединения, если у каких-то дат остались пустые биты, мы заменяем их на значения из текущей даты пользователя: например, если пользователь не назвал год, речь идёт о текущем годе, если не назвал месяц, то о текущем месяце и так далее. Разумеется в параметр "текущая дата" можно передать любой объект DateTime для гибкости.
Костыли
Не все моменты библиотеки удалось продумать изящно. Чтобы она работала должным образом, были добавлены следующие костыли:
- Объединение дат производится отдельно для токенов, которые начинаются с "в\с\со" и отдельно для токенов, которые начинаются с "по\до\на". Потому что, если пользователь назвал период, то объединять между собой токены из даты начала и даты конца нельзя.
- Не стал вводить отдельный уровень фиксации для дня недели, потому что нужен он ровно в одном месте: там где явно задан словом с названием дня недели. Сделал флаг для этого.
- Отдельным прогоном объединяются даты, которые стоят на некотором расстоянии друг от друга. Это контролируется параметром
collapseDistance, по умолчанию равным 4 токена. То есть, например, сработает фраза: Послезавтра встреча с другом в 12. Но не сработает: послезавтра встреча с моим любимым и замечательным другом в 12.
Итог
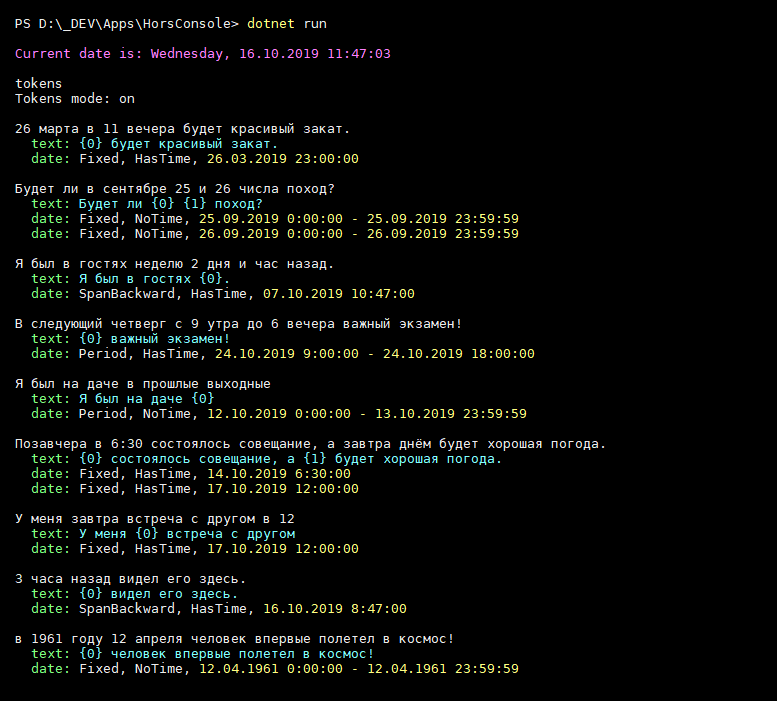
- Библиотеку можете использовать в своих проектах. Она справляется уже с многими вариантами, но я её дорабатываю и рефакторю. Пулл-реквесты с тестами приветствуются. И вообще, придумайте тест, который звучит реалистично (как люди говорят в жизни), но при этом ломает библиотеку.
- Live demo на .NET Fiddle тоже работает, хотя код подчёркивается якобы с ошибками, но запускается. Внизу в консоли можно вводить фразы на русском, не забывая о том, что числительные должны быть числами.
- Та же демка в виде консольного приложения
Вживую получилось так:
