Comments 24
Немного оффтоп: журнал «Знание (серия „Знак вопроса“) Другому как понять тебя?»
Простым языком рассматривается лингвистический анализ текстов для чайников.
p.s. Ну ооочень древний, с детства запомнился.
Простым языком рассматривается лингвистический анализ текстов для чайников.
p.s. Ну ооочень древний, с детства запомнился.
Даже интересно стало, вы про Маринину или про Донцову в конце рассказали?
Вы же понимаете, я не хочу получить иск о защите деловой репутации, поэтому никаких фамилий в тексте нет :) Готовый код выложен, можете поэкспериментировать самостоятельно. В принципе, для подобных авторов, издающих книги на потоке «раз в месяц» (я до сих пор не понимаю как это возможно:) может быть интересно проанализировать тексты по сериям, годам, количеству книг и пр.
Одно другому не мешает. Если цель — определение (или опровержение) авторства, то базовыми методами можно отсечь наименее правдоподобные варианты, затем уже переходить к более глубокому анализу.
Так-то да, идей, что можно проанализировать много, словосочетания, часто используемые слова, пары слов и пр.
Так-то да, идей, что можно проанализировать много, словосочетания, часто используемые слова, пары слов и пр.
Тут еще нужна LDA (пост на хабре). Если кому интересны инструменты по теме, то вот один из вариантов с обилием ссылок
Интересная заготовка! А можно свести все эти и другие синтетические параметры, полученные по различным книгам одного автора, и построить нормальный такой классификатор. И в теории он сможет определять авторство текста с какой-то вероятностью. Другой вопрос, что фичи придется поискать более сложные. Частотность маркерных слов и словосочетаний, средняя частотность глаголов/существительных/прилагательных/местоимений/… и т.д.
А еще забавнее было бы прогнать, например, по массиву диссертаций и поискать кластера предположительно одного авторства.
А еще забавнее было бы прогнать, например, по массиву диссертаций и поискать кластера предположительно одного авторства.
Есть практически готовая библиотека на эту тему: github.com/jpotts18/stylometry
Метод predict там есть, насколько хорошо работает, не изучал.
Метод predict там есть, насколько хорошо работает, не изучал.
Добавлю, библиотека старая, и перед использованием её придется портировать на Python 3.7.
Скорее всего, русскую морфологию не подхватит. Ну и как они сами пишут, одноразовый фан проект, который не поддерживается 6 лет. Но все равно спасибо! Нет идей что-то сделать дополнительно с вашим сабжевым проектом? Ведь наверняка из него можно выжать больше?
Они используют тот же NLTK, так что в принципе заработает, но разумеется, никаких склонений/падежей (или чего-то более сложного) для русского там нет.
Нет идей что-то сделать дополнительно с вашим сабжевым проектом? Ведь наверняка из него можно выжать больше?
Самое простое что можно сделать, это подать данные с частотного парсинга на вход нейросети в keras и посмотреть, будет ли оно как-то определяться. Но внутренний голос подсказывает, что точность на коротких фрагментах будет весьма низкая.
Интересно, существуют ли нейросети для стилизации текста? Не для генерации, а именно для копирования стилистики? Чтобы сначала скормить сетке пару книг желаемого автора, а потом — текст собственного фанфика, и сеть стилизовала этот фанфик так, чтобы читатель не отличил его по слогу от оригинала?
Для рисованных картин такое есть, и работает вполне неплохо. А для текстов?
Для рисованных картин такое есть, и работает вполне неплохо. А для текстов?
>> Ответ лично для меня стал очевиден, на графике определенно видна статистическая аномалия — стиль как минимум, одной книги заметно отличается от остальных:
Странный вывод. Даже если предположить, что на графике мы видим не разброс, а тенденцию, и далее следовать вашему предположению, что автор должен всегда писать в одном стиле, и не может его менять намеренно, с какими-то своими литературными целями, — то все равно, формально следует, что все остальные книги она написала сама, только пара книг не ее? И тогда это мало что меняет?
Но по-настоящему поражает само ваше предположение. А вы как-то пытались, действуя в научном стиле, проверить его? Ну скажем, сравнить рассказы Льва Толстого для детей, и «Войну и Мир»? Дадут ли они одинаковый отпечаток автора по вашему методу? Или разные тексты Сорокина? Или первый роман про Гарри Поттера, и первый роман про Корморона Страйка?
Странный вывод. Даже если предположить, что на графике мы видим не разброс, а тенденцию, и далее следовать вашему предположению, что автор должен всегда писать в одном стиле, и не может его менять намеренно, с какими-то своими литературными целями, — то все равно, формально следует, что все остальные книги она написала сама, только пара книг не ее? И тогда это мало что меняет?
Но по-настоящему поражает само ваше предположение. А вы как-то пытались, действуя в научном стиле, проверить его? Ну скажем, сравнить рассказы Льва Толстого для детей, и «Войну и Мир»? Дадут ли они одинаковый отпечаток автора по вашему методу? Или разные тексты Сорокина? Или первый роман про Гарри Поттера, и первый роман про Корморона Страйка?
Жанры совпадают естественно, детские книги со взрослыми никто не сравнивал. Хотя в тексте и было указано, что «возможно это совпадение». Все исходные коды выложены, пробуйте если есть интерес.
А если вы думаете, что случаев когда кто-то писал за другого, в литературном мире не существует, почитайте:
www.m24.ru/articles/literatura/26022014/38594
versia.ru/skolko-zarabatyvayut-literaturnye-negry
Я разумеется никого не обвиняю, все совпадения могут быть случайными :)))
Вы случайно не путаете науч-поп статью с диссертацией? Цели что-то доказать здесь не было.
А если вы думаете, что случаев когда кто-то писал за другого, в литературном мире не существует, почитайте:
www.m24.ru/articles/literatura/26022014/38594
versia.ru/skolko-zarabatyvayut-literaturnye-negry
Я разумеется никого не обвиняю, все совпадения могут быть случайными :)))
А вы как-то пытались, действуя в научном стиле, проверить его? Ну скажем, сравнить рассказы Льва Толстого для детей, и «Войну и Мир»? Дадут ли они одинаковый отпечаток автора по вашему методу? Или разные тексты Сорокина? Или первый роман про Гарри Поттера, и первый роман про Корморона Страйка?
Вы случайно не путаете науч-поп статью с диссертацией? Цели что-то доказать здесь не было.
Вы зря так негативно воспринимаете. Я просто хотел вас предупредить, что среди стилометристов встречаются насильники.
И если речь шла все-таки про Донцову, то вы просто ошибаетесь. И в конкретно ее случае, и вообще — может ли человек выдавать на-гора столько текста? Может. Возможно, вы слышали про Азимова? О числе его научно-популярных работ? А он начинал еще во времена, когда основным инструментом писателя была пишмашинка, и редактирование текста было куда труднее, чем сейчас на компьютере.
И если речь шла все-таки про Донцову, то вы просто ошибаетесь. И в конкретно ее случае, и вообще — может ли человек выдавать на-гора столько текста? Может. Возможно, вы слышали про Азимова? О числе его научно-популярных работ? А он начинал еще во времена, когда основным инструментом писателя была пишмашинка, и редактирование текста было куда труднее, чем сейчас на компьютере.
Спасибо за мнение. Никакого негатива и не было, фраза «лично для меня» в тексте по-моему вполне определенно указывает что это лишь личное мнение, а не доказательство теоремы :) Может я и ошибаюсь, а может и нет, гипотетически не исключаю что у некоторых авторов больше бизнес чем творчество. Полный анализ того или иного автора (особенно если там 100-500 книг) это не формат Хабра разумеется, ни по стилю, ни по трудозатратам.
Есть одна довольно известная (и на мой дилетантский взгляд, довольно правдоподобная) конспирологическая теория о том, что автором «12 стульев» и «Золотого телёнка» является на самом деле Булгаков. Не хотите проверить?
Взял для теста 4 книги Булгакова и 2 книги Ильфа и Петрова. Длина предложения и лексическое разнообразие более-менее схожи, но по количеству запятых различие довольно заметно.
Имхо не очень похоже, чтобы писал один человек, на графике разделение на 2 группы четко видно.
График
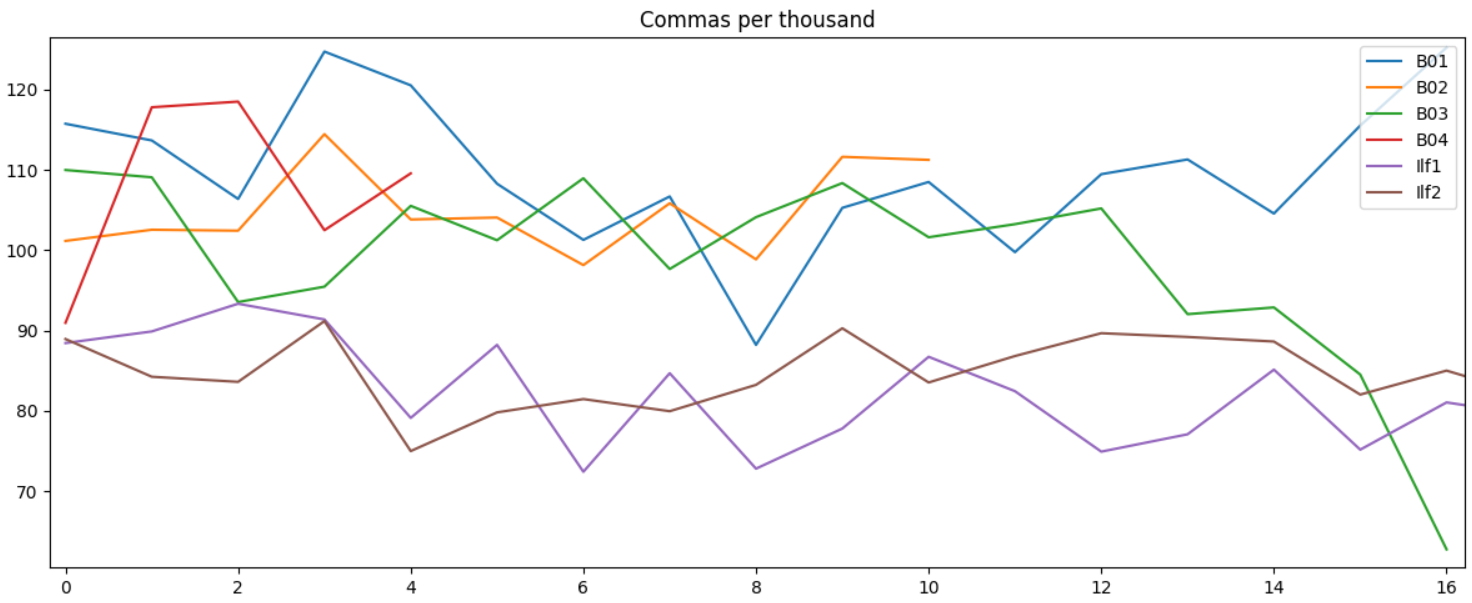
Имхо не очень похоже, чтобы писал один человек, на графике разделение на 2 группы четко видно.
Ну давно же есть подобные онлйн-игралки, причем куда более продвинутые, чем предлагаемый хеллоуворлд: fantlab.ru/rating/work/lingvo
Очень сложно, но в то же время очень интересно!
Спасибо. Давно есть идея спарсить онлайн издания, и отследить как менялся стиль в зависимости от редакторов или модных слов.
А как можно найти автора по определенным оборотам речи или словосочетаниям?
А как можно найти автора по определенным оборотам речи или словосочетаниям?
>как найти автора по
Я бы брал пласт тематических текстов. Т.е. если ищем футпринт автора художественной литературы, то берем художку, причем желательно максимально близкого жанра. Считаем частотность слов и выражений по всему пласту. Затем считаем по отдельным авторам авторскую частотность. Находим разность между авторской частотностью и средней. Пики — авторские словечки. Смотрим, какие слова характерны для конкретного текста и ищем наиболее близкого автора. Хотя, конечно, внутри море подводных камней. Придется искать что-то в духе «автор чаще использует „этот“ чем „который“, „и“ чем „а“ и т.п. Важно не хватануть слов, которые относятся к сюжету, а не самому автору. Т.е. не начать считать, что маркерное для Булгакова слово — »яйцо", тк оно часто встречается в роковых яйцах.
Я похожим образом в свое время делал модуль автопоиска ключевиков для статьи на сайте. В том приложении работало хорошо.
Я бы брал пласт тематических текстов. Т.е. если ищем футпринт автора художественной литературы, то берем художку, причем желательно максимально близкого жанра. Считаем частотность слов и выражений по всему пласту. Затем считаем по отдельным авторам авторскую частотность. Находим разность между авторской частотностью и средней. Пики — авторские словечки. Смотрим, какие слова характерны для конкретного текста и ищем наиболее близкого автора. Хотя, конечно, внутри море подводных камней. Придется искать что-то в духе «автор чаще использует „этот“ чем „который“, „и“ чем „а“ и т.п. Важно не хватануть слов, которые относятся к сюжету, а не самому автору. Т.е. не начать считать, что маркерное для Булгакова слово — »яйцо", тк оно часто встречается в роковых яйцах.
Я похожим образом в свое время делал модуль автопоиска ключевиков для статьи на сайте. В том приложении работало хорошо.
Я люблю перечитывать запомнившиеся места в книгах, но в большом произведении с невнятно названными главами их бывает сложно находить.
Сделал простейший анализатов — берем самые популярные слова в главе, убираем из них самые популярные в тексте.
Результат неплохо подсказывает содержание главы github.com/vashu1/data_snippets/tree/master/bag_of_words_chapters
Это конечно несколько оффтоп, но имхо хорошая демонстрация силы простых методов даже в такой сложной теме как тексты.
Сделал простейший анализатов — берем самые популярные слова в главе, убираем из них самые популярные в тексте.
Результат неплохо подсказывает содержание главы github.com/vashu1/data_snippets/tree/master/bag_of_words_chapters
Это конечно несколько оффтоп, но имхо хорошая демонстрация силы простых методов даже в такой сложной теме как тексты.
Sign up to leave a comment.
Стилометрия, или как отличить Акунина от Булгакова с помощью 50 строк кода?