In previous post I've described an example of kogito-based microservice on quarkus in native mode, containing one embedded pmml model with decision tree. While it can be successfully used for prototyping purposes, in the real life microservice might contain several prediction models. From the first view I've got an impression, that inclusion of several models should be a trivial extension of the prototype with one model. We were completely wrong in our assumption, that's the reason, why I've decided to write this post. Another reason, is absence of guides, in which 2 (or more models) are put inside DMN diagrams in kogito framework.
Again, oversimplified use case
As in the previous post, extension of the prototype is based on the oversimplified use case: based on location we would like to retrieve recommendations regarding outerwear and underwear.
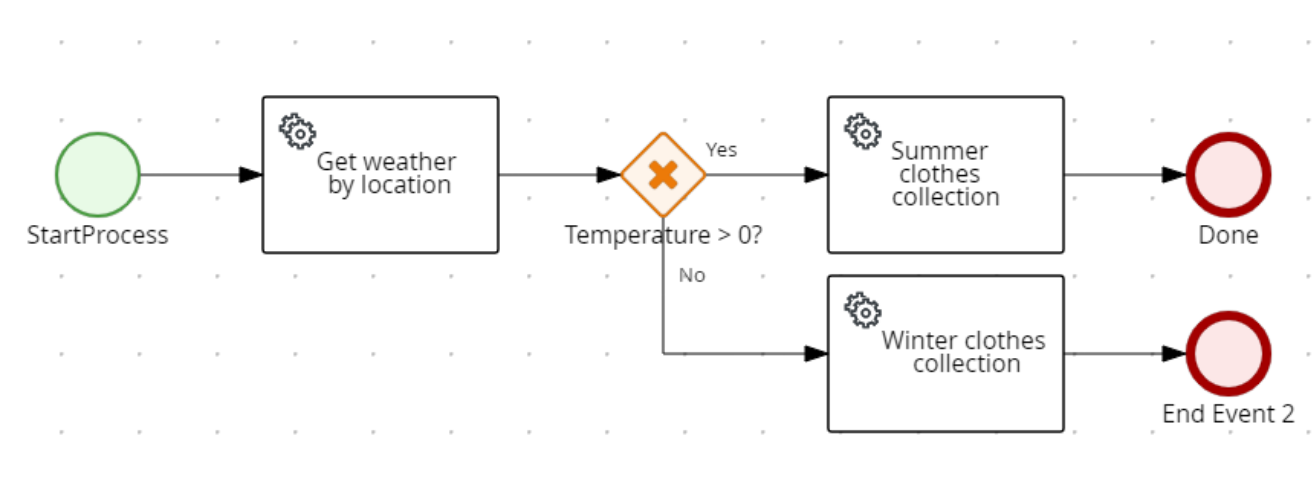
So, while BPMN diagram looks exactly in the same way, as in the previous article, result of execution should contain clothes structure with underwear and outerwear record. Data for underwear and outerwear record are delivered from 2 separate decision tree models, as a result of data mining in Knime. This separation of underwear and outerwear into 2 different decision tree models, is some kind on artificial separation, in the real-life scenario, it wouldn't make sense to do it. The main target here is to test possibility to use several pmml models inside of kogito microservice.
Technical implementation, 9000 feet view
Technical implementation is very similar to the one, which has been described in the previous post. The only difference is that now underwear field in clothes structure might be filled with socks or warm sock, depending on the temperature and also color might be magenta one in case of Bonn location.

Since the technical implementation of this prototype is the same, as the one mentioned in the first post, below only differences will be described.
BPMN and DMN
BPMN looks in the same manner except that now mapping from internal representation into external is done for the clothes structure, which contains underwear and outerwear string fields.

Embedded DMN diagram now contains 2 functions based on pmml models:

So, there are 2 input structures (main with weather information and location with location information). The stuff on the right hand side represents Functions based on embedded pmmls and it's invocation. The content of the functions and their invocations for underwear and outerwear is almost identical up to the pmml model used as decision tree.


Finally in clothes decision DMN we use dmn context to combine results of function invocations to the right field inside of tClothes structure.

PMML models created form Knime are very similar (even created from the same data set) to the ones, described in previous post. The difference between them is only the column considered as decision, and hence column, which is filtered out from the input data before training of the model is happening.
Finally we import both models to the DMN as follows:

JPMML instead of standard kie-pmml
Generally, having the most tricky stuff of setting result fields using context table, I was hoping, that no additional changes to the project are necessary. Unfortunately I was wrong with this assumption.
If standard libraries import (taken from basic 1 pmml tutorials) is kept, then you have an issue, that both fields of the clothes structure in the result are filled with the same value (resulting either from outerwear model or underwear model, most probably depending on the fact, which model was initialized first). Sadly, I haven't found any kind of reference to such behavior. The clue for solution was finally found in one of the manuals regarding commercial version of BPMN engine (namely from Red Hat Process Automation Manager) :
implementation 'org.kie:kie-dmn-jpmml:7.67.0.Final' implementation 'org.jpmml:pmml-evaluator:1.5.1' implementation 'org.jpmml:pmml-evaluator-extension:1.5.1'
This set of libraries provides full support of PMML specification implementation with the Java Evaluator API for PMML (JPMML).
Putting all together
Having all the actions, described above, done kogito-quarkus based microservice, containing 2 embedded pmml models, has been executed locally. When enabling native compilation via GraalVM, we haven't met any additional problems except of shifting initialization to run-time for several classes related to model prediction caching. Naturally, in resources for native compilation you should specify both pmml models.
Natively compiled microservice was embedded into our favorite ubi-minimal image, corresponding helm chart has been created and finally microservice was deployed to Kubernetes platform.
Conclusions
Surprisingly for us, migration from 1 to 2 embedded pmml models inside of DMN turned out to be non-trivial task. Nevertheless, having solved all the problems, we've got a common way for creation of microservice, which contains several decisions tree models in pmml format.
Native compilation of such microservices was rather straightforward. Native applications with pmml models provide good known benefits regarding resource consumption and shorter start times.
