
Сейчас модно писать, что ML пришел туда и все стало отлично, DL пришел сюда и все стало замечательно. А к кому-то пришел сам AI, и там все стало просто сказочно! Возможна ли ситуация, когда к нам пришел волшебный ML/DL и все стало сложнее, тяжелее и на порядок запутаннее? Безусловно! Разберем такой пример.
Десятки лет при сравнении кодеков и алгоритмов обработки видео исследователи использовали старые добрые метрики PSNR и SSIM с довольно простыми формулами и были счастливы. Но прогресс невозможно остановить! На их место пришли новые метрики и… тут выяснилось, что они взламываются.
— Погодите, погодите… — скажет взволнованный читатель, — А как это вообще выглядит, взломать метрику???
— Добро пожаловать в 21 век, дорогой товарищ! Благодаря неудержимому прогрессу, сегодня можно хакнуть не только утюг, колонку, автопилот машины и домашний пылесос, но и метрику качества видео.
В этот момент собеседники обычно дружно спрашивают, кому это надо? О, поверьте, есть люди, которым не просто надо, а сильно надо! Представьте себе, что вы руководитель подразделения и у вас жесткие KPI (маркетинг требует обогнать конкурентов, от этого зависят нехилые годовые бонусы у всех сотрудников и особенно у вас). Чтобы улучшить видеокодек на условные 4%, требуются десятки человеко-месяцев труда весьма высокооплачиваемых инженеров, причем, бывает, получается, а бывает, не очень. И тут выясняется, что можно за пару недель работы одного зеленого стажера подшаманить метрику на 7%. Ваши действия? Вспоминается жизненный анекдот «тут-то мне карта и поперла»…
Далее мы популярно затронем взлом методом черного ящика, белого ящика, взлом недифференцируемых метрик (привет дистилляция!) и цирк с дифференцируемыми.
Впрочем обо всем по порядку…
Кому интересен цирк с конями взлом метрик — го под кат.
Взлом VMAF или как мы курощали Netflix
Так сложилось, что уже добрых 19 лет мы проводим крупнейшие в мире профессиональные сравнения кодеков. Если в гугловом поиске по картинкам набрать video codec comparison, то там будет полно наших графиков за разные годы (или графиков на основе наших данных).
В 2016 году компания Netflix предложила новую метрику VMAF. На тот момент ежегодно выходило порядка 2500 научных статей по метрикам качества видео, и направление бурно развивалось. Мы с коллегами внимательно следили за новинками, но по разным причинам все они не оправдывали ожиданий (отдельная тема, почему так происходит снова, и снова, и снова). На этом фоне разработка Netflix выглядела весьма перспективно. В узких кругах специалистов по видеостримингу эта компания была известна тем, что платила заметно больше рынка и собрала у себя очень профессиональную команду. В 2017 году мы тестировали VMAF (она показала себя очень хорошо), а в 2018 году добавили ее в основные отчеты сравнения.
Стоит сказать, что наши сравнения заметно отличаются от других тем, что мы работаем непосредственно с авторами кодеков, т. е. все коммерческие кодеки, результаты которых мы показываем, получены от авторов и с авторскими настройками (последнее важно). Это добавляет нам адскую головную боль по организации, но дает много интереснейших данных в первую очередь по коммерческим кодекам, поскольку их невозможно скачать — они доступны только в виде корпоративных или облачных решений. При этом такие кодеки, как правило, наиболее продвинуты (во всех смыслах).
В последнем утверждении мы имели счастье в очередной раз убедиться, когда кодек одной из компаний (неважно какой) внезапно на «новой» VMAF показал себя заметно лучше, чем по «старым» метрикам. Наши ребята копнули тему, и открылась чудная картина. Оказалось, что VMAF можно накрутить, т. е. увеличить ее значения, специальным образом обработав видео. Причем возможен вариант, когда видео обрабатывается не после сжатия (что требует своего декодера и не слишком практично), а до сжатия, и в процессе кодирования-декодирования накрутка сохраняется. При этом декодер, вообще говоря, может быть любым, соответствующим нужному стандарту. Это уже крайне интересно, поскольку появляется реальное использование! Когда копнули еще глубже (глубже авторов кодека), выяснилось, что, хотя многие методы накрутки роняют качество (т. е. метрика показывает, что качество растет, а на практике оно падает), есть методы, которые визуальное качество увеличивают. Это вообще просто праздник какой-то, поскольку серьезно увеличивает практическую применимость подхода и кардинально меняет правила интерпретации результатов метрик в ближайшем будущем!
Впрочем, обо всем по порядку. Совсем кратко VMAF устроена так:

Источник: Картинка из лекций автора
Метрика использует три признака, извлекаемых из исходного видео: Visual Information Fidelity (VIF), Detail Loss Metric (DLM) и Mean Co-Located Pixel Difference (учет составляющей изменений во времени). На основе этих признаков и субъективного датасета (который, кстати, не был полностью раскрыт Netflix) был обучен SVM регрессор, т. е. это ML метрика, имеющая относительно высокую скорость работы. Есть активно поддерживаемый github репозиторий с оптимизированными реализациями.
Когда мы обнаружили способы накрутки, думали, что с этим делать. Решили пойти по открытому пути и опубликовать результат. Публикация произвела в узких кругах профессионалов эффект маленькой бомбы, поскольку независимые проверки в разных местах показали великолепное соотношение скорости работы и качества VMAF и метрика активно набирала популярность. Известный американский эксперт по кодекам Ян Озер легко воспроизвел наши результаты и в некотором обалдении написал об этом в своем известном среди разработчиков кодеков блоге, популяризировав наше исследование:

Источник: VMAF is Hackable: What Now?
Вопрос, поставленный им в заголовке статьи, очень хороший, поскольку уже понятно, что это только самое начало открывания чудесного ящика Пандоры и обнародованные способы взлома VMAF не единственные. Для многих экспертов также очевидно, что это большая проблема, поскольку метрика, безусловно, удачная, но, как дальше интерпретировать ее результаты, — вопрос открытый. Какая доля увеличения результата реальная, а какая — благодаря деликатной (или не очень) накрутке? И как быстро производители внедрят этот подход в код? Даже в своей статье Озер ссылается на iSIZE Technologies — компанию, которая подняла 6 миллионов долларов инвестиций на косплее Джобса "deep neural networks for data-driven video preprocessing". И призывает крайне скептично относиться к декларируемым ими (и не только ими!) результатам во VMAF.
Что тема «зашла в народ», буквально через полгода делом подтвердила Google, добавив в продвигаемый ими open source кодек AV1 «тюнинг» (накрутка) под VMAF описанным нами способом:
Источник: Репозиторий AV1
Теперь вкатить соответствующий код в свой препроцессор или кодек стало совсем просто! Cut, paste, обертка, и у вас начальная версия (ну или конечная, в зависимости от навыков программиста и требований к уникальности кода), которую можно использовать в продукте.
Очевидно, Netflix понимали, что это проблема, и еще через полгода выкатили новую модель NEG, что означает — "No Enhancement Gain" (т. е. «нет гейна от улучшения», или «нет улучшающей накрутке» — как вам больше нравится):

Источник: On VMAF’s property in the presence of image enhancement operations
Это, безусловно, замечательно. Всегда здорово, когда производители оперативно патчат дырки. Но с этой моделью, как часто бывает с костылями, возникло много проблем.
Сколько способов вычислить VMAF вы знаете?
Когда я где-то в рассказе (или докладе) вижу ссылку на график с VMAF, а особенно VMAF без опознавательных знаков и уточнений, я очень люблю спрашивать — а какой это вариант метрики? Особенно интересно задавать этот вопрос господам из индустрии, которые, во-первых, чаще остальных приводят графики без указания даже версии VMAF, а во-вторых, часто не знают, сколькими способами можно ее рассчитать.
Краткий ликбез: у VMAF существует три разных версии и пять модификаций, что дает девять разных «официальных» способов ее посчитать (поскольку не для каждой версии существует соответствующая модификация модели):

Но это еще не все! «Из коробки» VMAF оценивает только искажение яркости, что не всегда бывает адекватно реальному кейсу использования. Более того, если ее использовать для оценки потерь цветовых компонент, то корреляция с субъективной оценкой даже возрастает (т. е. это не только удобно на практике, но и улучшает метрику). Поэтому при профессиональном использовании делают такое подмешивание, заодно точнее контролируя «одним числом», что происходит в стриме. И все бы ничего, если бы даже с разными вариантами подмешивания результаты VMAF NEG не были столь плохи. Желтые столбцы в конце длинного неполного списка разных способов подсчитать VMAF — это многострадальная NEG:
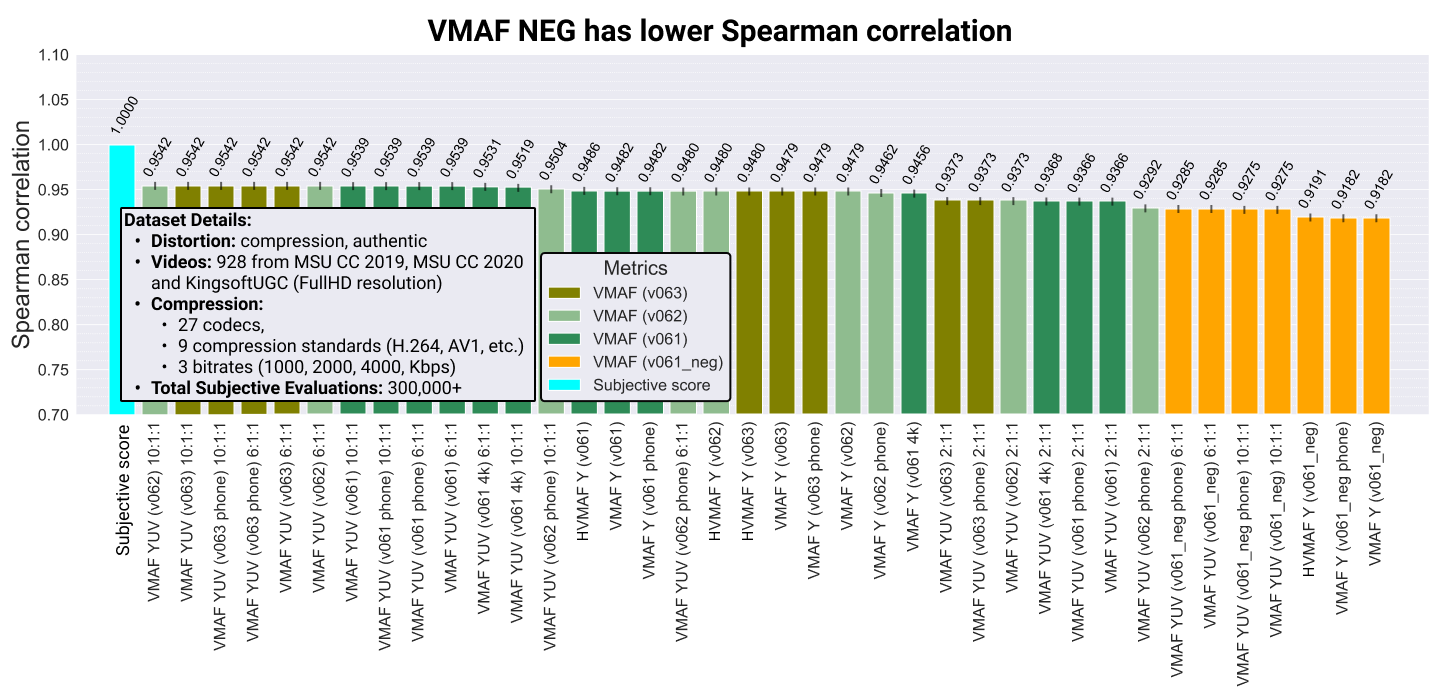
Источник: Материалы MSU Full-Reference Video Quality Metrics Benchmark 2022
По сути получается, что увеличение устойчивости метрики к взлому существенно просадило ее главную характеристику — корреляцию с человеческим восприятием. Что самое печальное, просадка, во-первых, постоянная, а во-вторых, наиболее велика на исходных (только Y) моделях с самой высокой корреляцией. Вот наглядное сравнение (кстати, тут хорошо видно, как «подмешивание» цвета частично «защищает» VMAF NEG от падения и на чистых Y просадка стабильно выше):
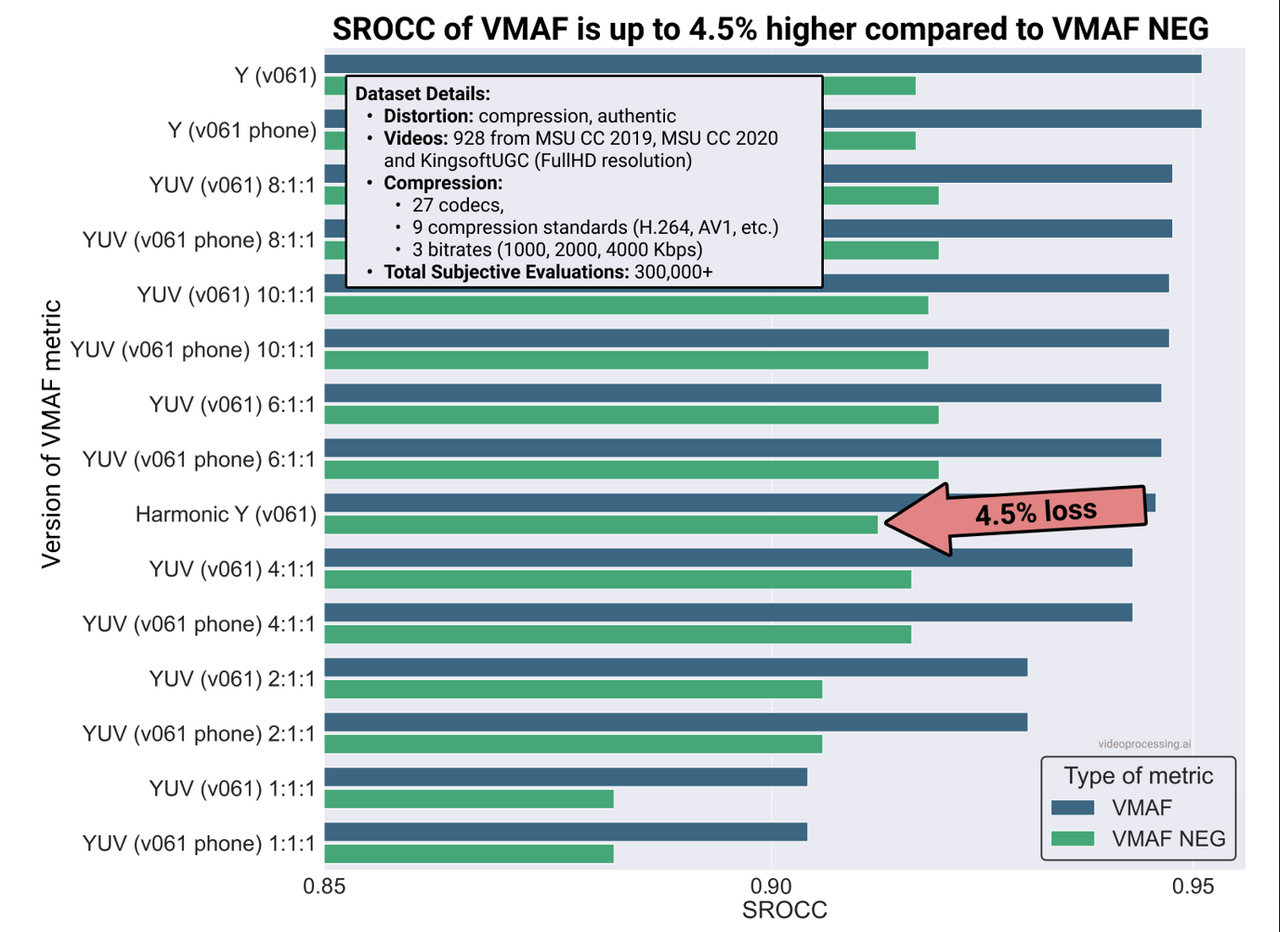
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Внимательные читатели хабра нередко замечают, как провокационный вопрос остается нераскрытым в статье. Исправляемся! Так сколько же способов посчитать VMAF существует? Девять моделей из коробки на шесть популярных способов подмешать цвет на два наиболее частых способа посчитать среднее (гармоническим и арифметическим усреднением) дают 108 способов. В ситуации, когда люди (и компании) покупают цифры, а тем более, платят за них дорого, очевидно, что это разнообразие можно (выражаясь политкорректно) креативнейшим образом использовать в маркетинговых целях:
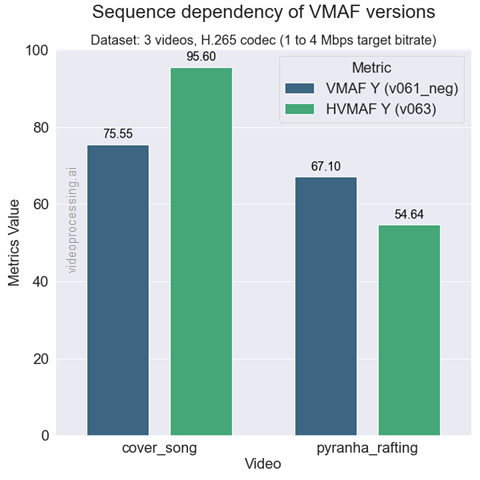
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Например, интересно, что разные версии VMAF для одного и того же кодека на одинаковых видео могут показывать СУЩЕСТВЕННО отличающиеся результаты. Поэтому берем «нужную» версию VMAF, «нужные» видео и вуаля — у нас результат А существенно лучше результата Б. Ну или наоборот. В зависимости от того, что заказал его величество бизнес. Более того, для VMAF NEG у нас серьезное различие возможно даже на большой выборке кодеков разных стандартов (результаты для 15 кодеков!):
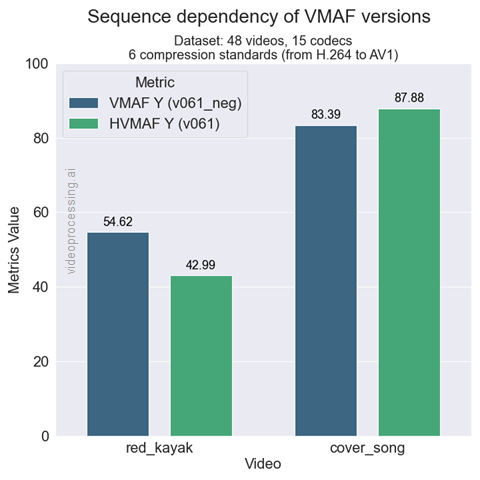
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Т. е. «правильно» подобрав, на чем сравниваться, и версию метрики, можно в значительных пределах варьировать результат, причем именно для VMAF NEG. Но на этом проблемы не заканчиваются. Пока мы сравнивали версии VMAF только с собой. Если сравнить ее с другими метриками, то выясняется, что «старая добрая» MS-SSIM может обгонять VMAF NEG по корреляции(!):
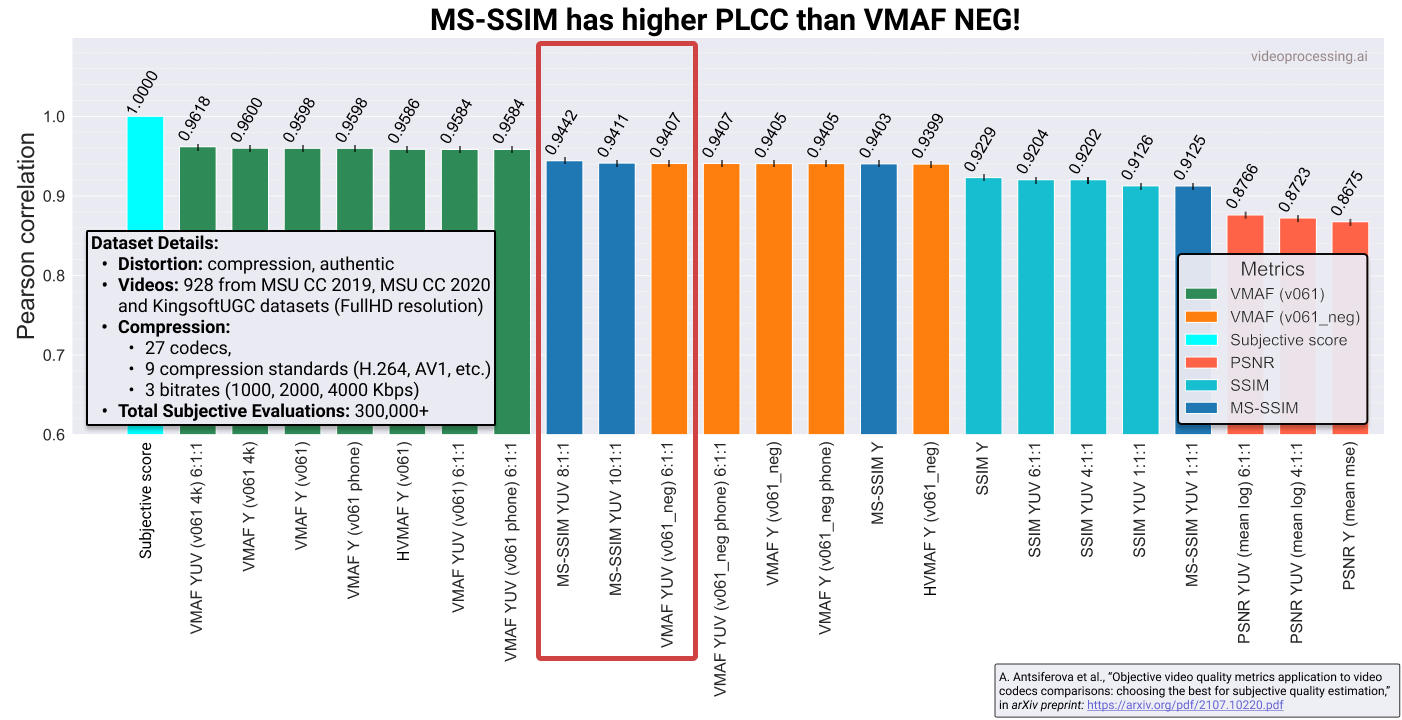
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Это фатальный недостаток, поскольку кодеки в индустриальных решениях гоняют на машинах без GPU (снижая стоимость прогона), а даже оптимизированная по скорости версия VMAF, на минуточку, в 22 раза (!!!) медленнее оптимизированной по скорости версии MS-SSIM (из-за которой компании любят MSU VQMT SDK):

Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Это, по сути, смертный приговор метрике в глазах многих практиков.
Вообще быстрый подсчет метрик — отдельная крайне интересная тема. Обычно люди берут метрики, например, из ffmpeg, не задумываясь насколько там при оптимизации скорости проседает качество метрики и сколько из нее вообще можно выжать. А при желании особенно на машине с GPU там можно выжать в абсолютных значениях очень существенно (это важно, когда считаются машино-годы метрик), при том, что, без оптимизаций, людей удовлетворяет считать в 4 раза медленнее и одновременно хуже по корреляции (варианты 52 оптимизаций 6 метрик):
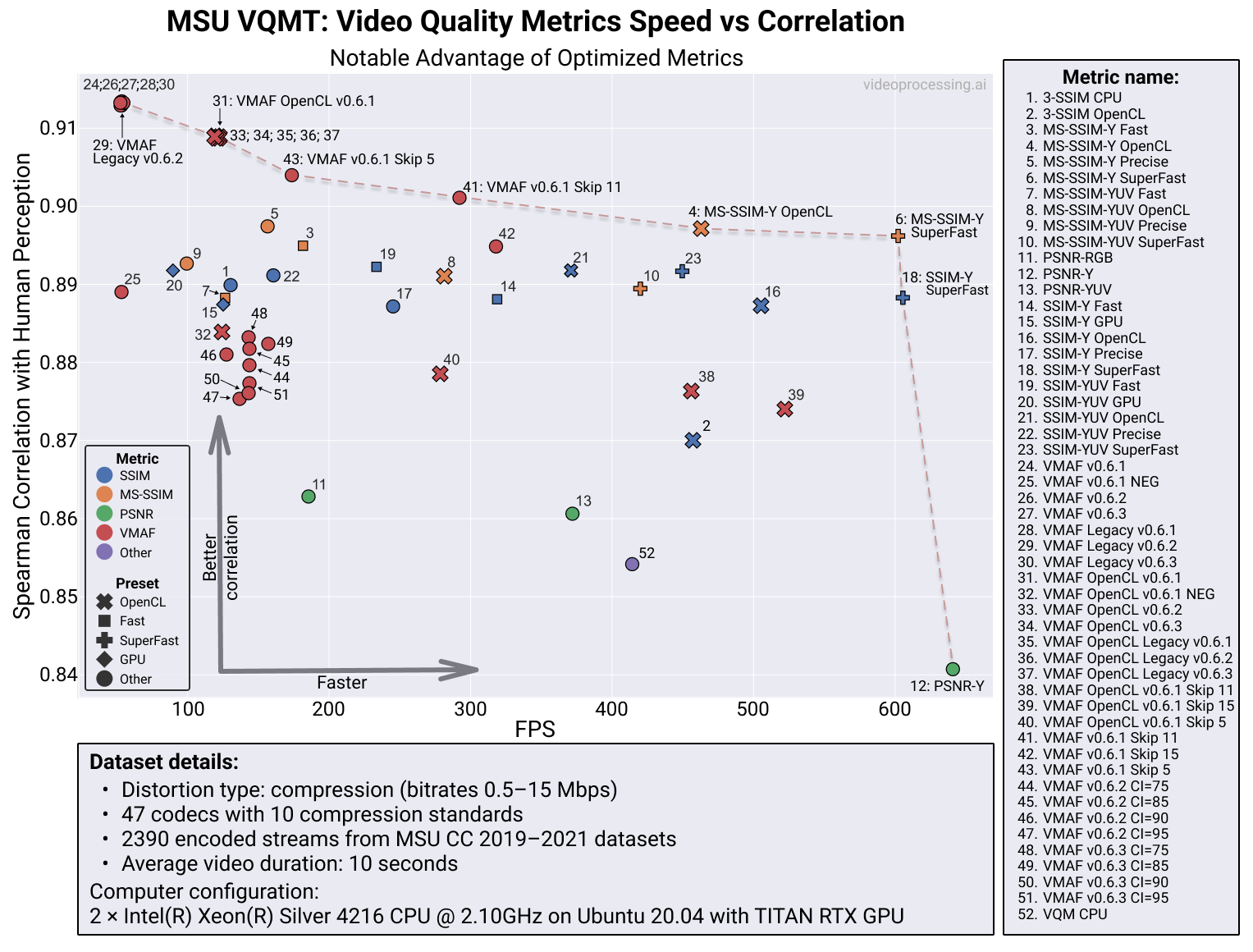
Источник: результаты ускорения метрик в MSU VQMT на CPU и GPU
Но на этом приключения VMAF NEG не заканчиваются. Естественно, после ее выхода проклятые русские хакеры мы с коллегами взяли ее в работу и еще через год, летом 2021, опубликовали статью, описывающую новые способы взлома VMAF и (о не-е-е-ет!) взлома VMAF NEG… Да, она оказалась более устойчива, но все равно накручивается:

Источник: Наша статья о взломе VMAF NEG
С нетерпением ожидаем от Netflix новой версии, для которой уже даже придумали название — VMAF NEGA, что, очевидно, означает "No Enhancement Gain Again" (перефразирование очень популярного в США слогана).
Вот любопытная табличка, из которой видно, что не мы одни потоптались на взломе VMAF, но мы были первые, и пока наши результаты шире и с большим гейном:
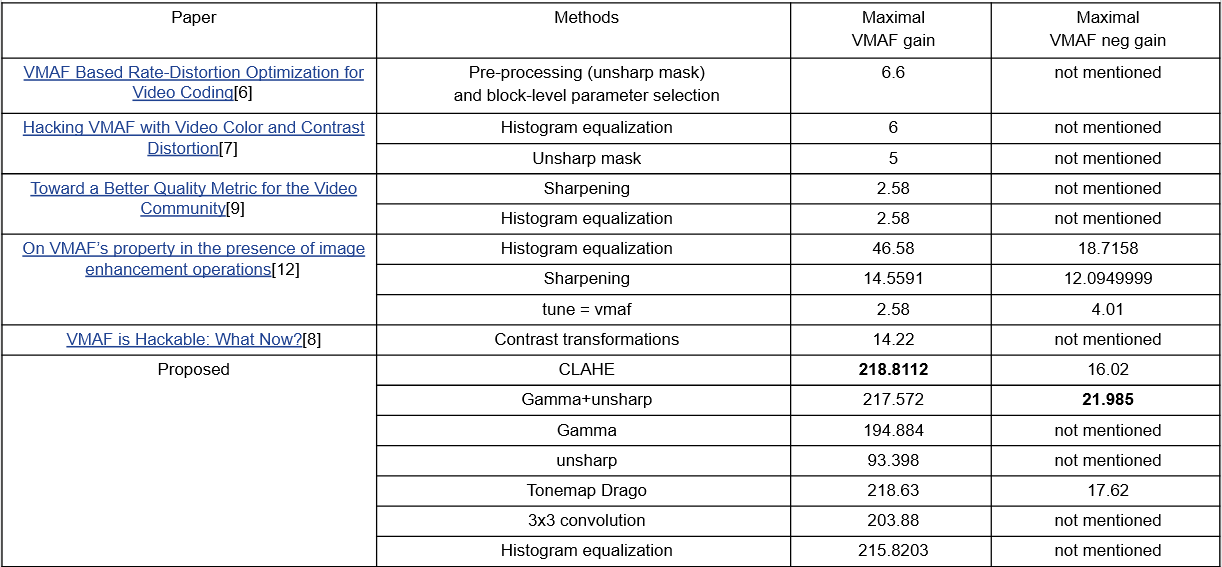
Источник: материалы из лаборатории автора (proposed — наш)
Замечу, что в таблице только преобразования, которые улучшают изображение. На практике очень частая ситуация, когда накрутка заметно просаживает визуальное качество. При этом если метод накрутки изначально является методом улучшения изображений, то при грамотном, относительно бережном применении и визуальное качество растет, и метрика. Заметим, что применение в этом случае зависит от контента (т. е. алгоритм применения накрутки варьируется от сцены к сцене не только по параметрам, но и по примененному алгоритму, из-за чего его становится заметно сложнее детектировать). Это, кстати, крайне радует менеджеров от бизнеса, поскольку позволяет замаскировать накрутку под чудесный «препроцессор-улучшатель» и на голубом глазу говорить красивые слова об улучшении визуального качества и неустанной денной и нощной заботе о благе пользователей. Справедливости ради, подобная риторика — не новое изобретение. Та же Apple в своих кодеках делает подобное уже больше 10 лет, из-за чего их крайне сложно объективно измерить, только теперь этот подход «наконец-то» не портит, а улучшает метрики и, как следствие, на глазах становится массовым трендом.
Также в таблице выше рассматривается только взлом методом черного ящика. Бывает также взлом методом белого ящика и через построение дифференцируемой версии метрики, над чем мы тоже работаем. Например, мы попробовали дообучить сеть ProxIQA на атаку VMAF:
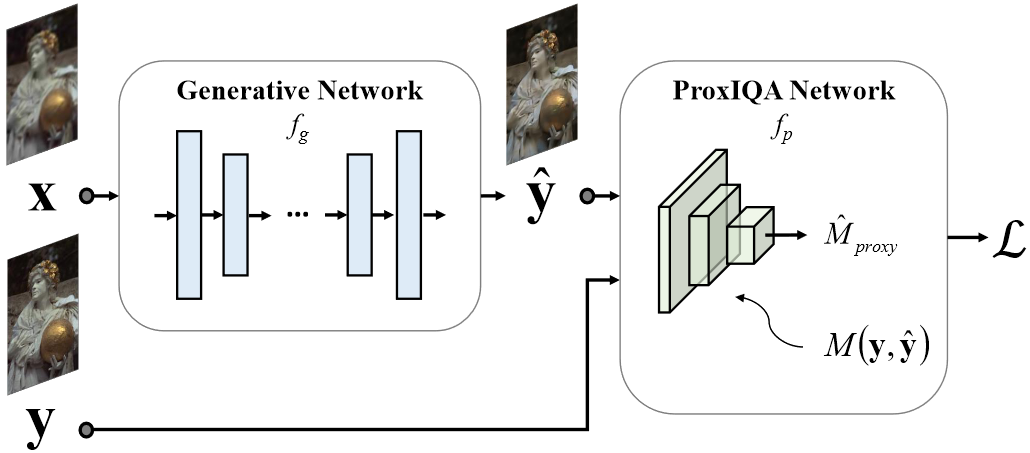
Источник: ProxIQA: A Proxy Approach to Perceptual Optimization of Learned Image Compression
В среднем удалось таким образом увеличить VMAF на 21%. Это меньше, чем дает black-box атака, но подход работает очень быстро (больше 60 fps), то есть его можно использовать в реальном времени. Также в целом уже понятно, что это только начало работы и с этим видом атак возможно много интересных результатов. Визуально качество здесь также может быть выше, как на этом примере:

Источник: Не опубликованные результаты повышения VMAF с 97.4 до 160.4 через дистилляцию VMAF ProxIQA
Специально для тех, кто сейчас громко подумал, ну их, эти новые метрики, давайте останемся в пещерах со старыми добрыми PSNR и SSIM: Господа! Я специально подчеркивал выше — твердую поступь прогресса невозможно остановить! Новые кодеки, выжимая максимум из сжатия потока, начинают использовать подходы, которые условно «математическую» точность сжатия (в терминах среднеквадратичного отклонения и PSNR) приносят в жертву пользе визуального качества. Т. е. картинка выглядит (на самом деле!) лучше, а старые добрые метрики с этим не согласны.
Например, на активно растущем по популярности новом открытом стандарте AV1 MS-SSIM еще как-то держится (хотя тоже заметно проседает), а вот PSNR кардинально упала. Очевидно, это повод отказаться не от AV1, а от PSNR:
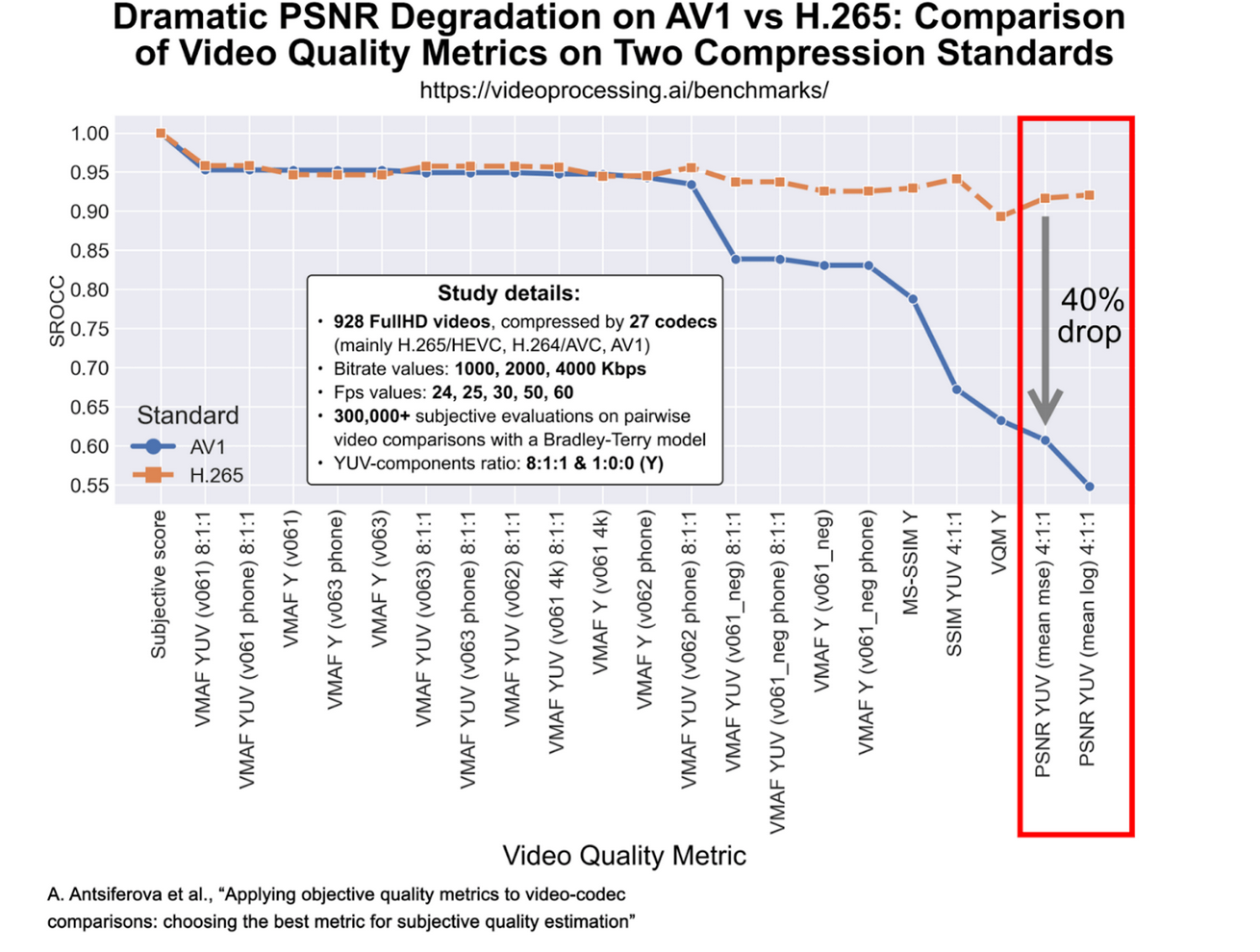
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Аналогичная ситуация (чуть помягче) у VVC (он же H.266), поэтому можно смело прогнозировать закат старых метрик для всех, кто выйдет за рамки старых стандартов. А это значит в скором будущем для всех.
К слову, внимательно изучающие график выше заметят, что VMAF NEG на AV1 также заметно просела, так что ее «полоса невезения» еще не закончилась.
Визуально такое расхождение мнения людей и метрик для другого нового стандарта LCEVC (2021) по сравнению со сжатием предыдущего поколения HEVC/H.265 (2013), выглядит так (для людей справа лучше, для старых метрик справа хуже):

Источник: Наши исследования нового стандарта, на которых хорошо видна неадекватность старых метрик
Интересно, что в обработке видео, например, в модном Super-Resolution (массово используется, чтобы поднять разрешение для растущих по разрешению экранов телефонов, мониторов и телевизоров) падение PSNR вообще феерично:
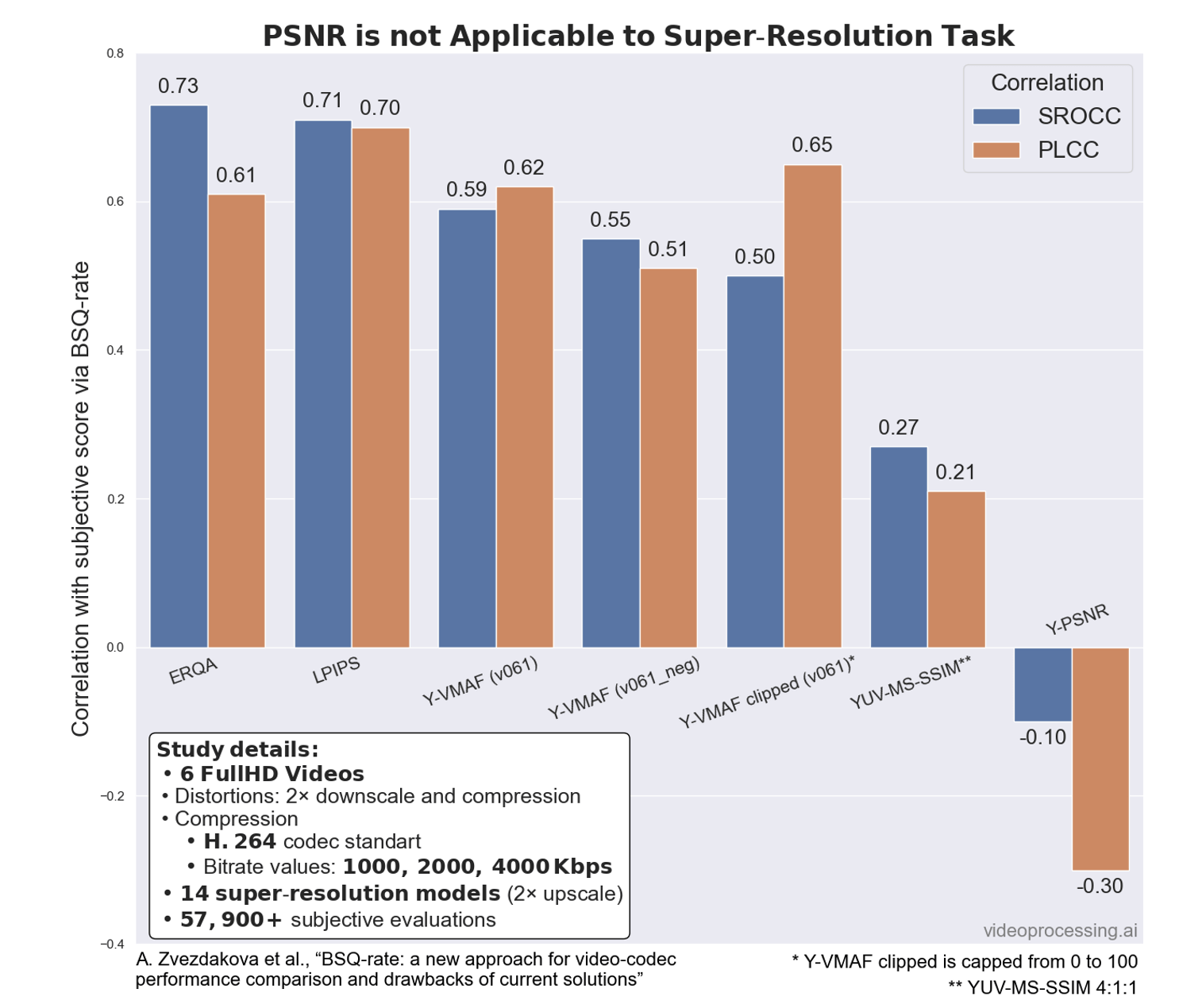
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Корреляция становится не просто низкой, она становится ОТРИЦАТЕЛЬНОЙ, причем это график в среднем для 14 разных алгоритмов Super-Resolution! Это означает, что когда метрика говорит, что «стало лучше», люди дружно говорят, что «стало хуже», а когда метрика говорит, что «стало хуже», люди… Ну вы поняли. На этом фоне с большим умилением наблюдаю, как в свежих научных статьях по Super-Resolution самой популярной метрикой до сих пор является PSNR. С другими методами обработки видео мы наблюдаем аналогичную картину падения корреляции PSNR.
Визуально для SR это выглядит, например, как в примере ниже — 99% людей считает, что слева картинка лучше, а старая метрика считает, что лучше справа, причем существенно:

Источник: материалы MSU Video Upscalers Benchmark 2022: Quality Enhancement
И еще из интересного. В прошлом году мы проанализировали почти 400 статей по Super-Resolution, посчитали какие метрики наиболее популярны. На графике хорошо видна «восходящая звезда» — метрика LPIPS:

Источник: ERQA: Edge-Restoration Quality Assessment for Video Super-Resolution
Мы проверили LPIPS, она показала себя очень хорошо с точки зрения корреляции с человеческим восприятием. Здорово, сказали мы, и решили проверить ее на предмет взлома. К сожалению с устойчивостью все оказалось печально и метрика довольно легко накручивается. Можно минимальными (совершенно незаметными и незначительными с точки зрения PSNR & SSIM) «поправками» в картинке кардинально (в 10 раз!) изменить значение LPIPS:

Источник: наши неопубликованные результаты
Учитывая, что в этом сезоне модно измерять только PSNR, SSIM & LPIPS, столь скромный набор метрик открывает большие перспективы для накруток. Это к вопросу, кто там сейчас SOTA. Мы, кстати, для Super-Resolution свою open source метрику предложили (просто наберите "pip install erqa"), но уже очевидно, что там еще очень много работы.
Подведем предварительные итоги:
Дни «старых» метрик сочтены. Они реально неадекватны новым алгоритмам (кстати, особенно — нейросетевым, надеюсь, как-нибудь про это напишу, ибо там очень прикольно местами).
«Новые» метрики более адекватны человеческому восприятию, но подвержены разного рода взломам.
Если метрика дифференцируема (что верно для всех нейросетевых, примеры будут чуть ниже) — ей можно крутить вообще свободно, подгоняя и алгоритм под данные, и данные под алгоритм. Для некоторых метрик можно манипулировать всего одним пикселем, наслаждаясь изменением значение метрики по всему кадру (минус подхода — какой пиксель и как менять зависит от содержания изображения). Есть и еще методы взлома, о которых будет ниже.
Если метрика не дифференцируема, можно:
Взламывать методом черного ящика. Особенно интересны подходы на основе алгоритмов улучшения качества, но и ухудшающие картинку в некоторых случаях годятся (особенно для стартапов, продающих инвестору по сути графики).
Взламывать методом дистилляции: когда строится сеть, повторяющая нашу метрику, и, получив дифференцируемую модель метрики, мы применяем к ней весь богатый арсенал атак (от состязательных и далее по списку).
Как следствие:

Глобально эту ситуацию сложно назвать новой, ибо, как любил говаривать известный циник и большой знаток человеческой природы доктор Хаус: «Все лгут!»

Источник: Сериал Др. Хауc «Все лгут»
Сегодня на наших глазах в узкой области меняются всего лишь масштабы бедствия. Причем происходит это в основном потому, что образование людей инертно, и потребуется некоторое время, чтобы основная масса профессионалов осознали, как изменился мир и на что (и как) в этом новом мире можно опираться. Решения, конечно же, существуют, просто они дороже, сложнее и дольше, и людям нужно сначала несколько раз научиться на своих ошибках, чтобы это прочувствовать.
Интересно, что по нашему опыту сейчас в компаниях заметно вырос спрос в первую очередь на методы взлома. Т. е. как можно накрутить метрику. Вангую, что в ближайшие пару лет компании-лидеры (особенно китайские) будут демонстрировать совершенно очешуительные показатели (и графики) и их независимая проверка техническими отделами их клиентов будет показывать, что все верно и, действительно, технологии волшебные, ибо цифры совпадают (конечно-конечно, не обижайте нас!). Так будет происходить увеличение продаж и смена технологических лидеров.
Вообще, в общении с компаниями я часто вспоминаю старого доброго папашу Мюллера:

Источник: Цитата из фильма «17 мгновений весны»
Вспоминать приходится потому, что подобные накрутки появились не только для внешнего заказчика, но и внутри компаний, когда подразделение активно отчитывается о технической победе, а в компании просто не хватает специалистов, чтобы адекватно оценить результат. Интересно, что не только американцы, но даже китайцы в этом случае вполне себе привлекают внешних экспертов (в том числе и нас, я упоминал об этом на Хабре тут), а русские компании в этом практически не замечены. Они верят и другим, и себе. В наше время. Дивное, заметим! Очень интересное и поучительное зрелище, которое для вас, дорогие читатели, означает, что у меня будет еще много чудных историй! Какую-то часть из них можно будет даже рассказать, не нарушая NDA.
Что же дальше?
Для тех, кто подумал, что дело труба, у меня хорошие новости. Сегодняшняя ситуация на самом деле очень неплохая, поскольку это только самое-самое начало процесса. Уже через пару лет все точно станет намного хуже! Знаете, как пессимист говорит: «Это какой-то полный трындец, хуже быть не может!» — а оптимист ему с улыбкой отвечает: «Может-может!» В этом плане я чувствую себя в последнее время глубочайшим оптимистом.
Вообще для того, чтобы что-то интересное делать в этой области, категорически нужны данные (много данных!). А конкретно, нужна разметка, «что такое хорошо и что такое плохо» для человека, поскольку именно качество с точки зрения человека волнует, и именно тут возникают накладки, когда метрика считает, что качество растет, а с точки зрения человека оно падает (и наоборот). Сложность заключается в том, что опрашивать людей — относительно долго и дорого, а для хороших результатов, особенно с использованием DL, данных надо очень много. Иначе получается не результат, а пшик (все красиво и графики божественны, но на других данных оно не воспроизводится).
Мы с коллегами этой темой плотно заняты 5 лет и накопили довольно большой датасет, один из наиболее крупных в мире в данной области:

Источник: Наша статья на NeurIPS-2022
Суммарно на его разметку было потрачено порядка одного миллиона рублей. По нынешним временам это немного, но повторить эту работу в Европе или США будет дороже [рассказ, почему у нас дешевле, находится за гранью политкорректности, поэтому жестоко вырезан внутренней цензурой]. Также планируем за этот год существенно датасет расширить, особенно в направлениях, где сейчас данных не хватает и доверительные интервалы великоваты. Учитывая размер датасета, мы можем себе позволить раздавать только его небольшую часть, что позволяет строить на его основе бенчмарки на данных, которые алгоритмы гарантированно не видели при тренировке. Такой подход снижает цитирования (ибо почему-то падает количество желающих поучаствовать), зато дарит много чудных открытий. И очень важно, что такой объем данных позволяет ярче подсвечивать особенности разных метрик и анализировать новые подходы.
На публикацию бенчмарка на основе этого датасета уже отозвался профессор Алан Бовик — самый цитируемый в мире ученый в области метрик качества видео (суть: круто, поскольку на наших данных никто не тренировал):
Hi Folks,
I saw this with great interest. I notice that (of course) the database is all compression distortions, and the trainable models (which have been trained on other distortions, like UGC), have not been retrained on the MSU data.
Al
А вот отзыв китайского профессора Shiqi Wang, который льет нам бальзам на душу, что мы с моими замечательными коллегами меняем сообщество такими работами:
We really would like to contribute our quality measures to MSU. Actually, I am closely following what MSU is doing. You have done many things that have changed the society.
Но, конечно, многих интересуют данные, хотя бы частично. Например, вот:
This benchmark is great, can you share me the public samples? I will use them to adapt my method launch script.
Или вот просят:
We want to estimate the performance of our method on public samples of your dataset, so that we request for samples of your dataset.
И еще:
Do you think it will be possible to get sample bitstreams for each of the codecs just to make sure the model can run on them? Note that I am asking about the bitstreams, not YUV versions of the videos.
И даже протестировав, просят не публиковать результат, планируя попробовать другую версию:
Thank you for the comprehensive evaluation report. It seems that the submitted ***** version, which is mostly developed on our self-build datasets, has not achieved the expected performance on MSU benchmark dataset. At this moment, we want to hold the evaluation results, and could we submit another version of ***** developed with public available VQA datasets?
Кстати, после полугода просьб мы, одновременно с публикацией статьи на NeurIPS, таки выложили часть датасета. Посмотрим, как это скажется на сабмитах новых метрик. Вообще, с разными метриками получилось много интересного:
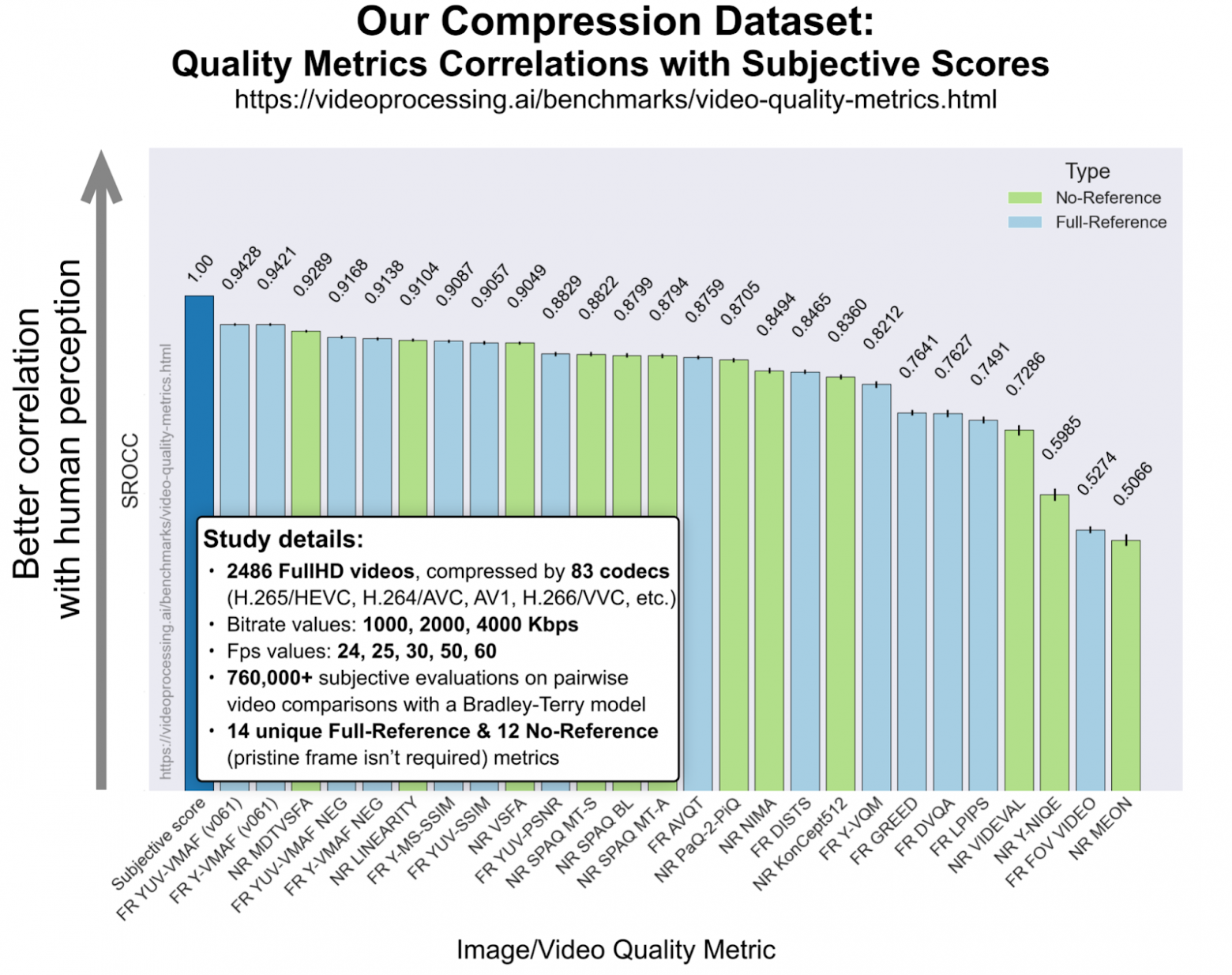
Источник: Moscow State's Dr. Dmitriy Vatolin Talks Codecs and Quality
Например, в конце весны 2021 Apple с помпой представила свою метрику AVQT (в конце первой трети графика выше), пообещав в дальнейшем все видео на платформе измерять с ее помощью. Выглядело многообещающе, но на большой выборке их метрика проиграла не только VMAF, но и относительно старой (а главное, при оптимизации очень быстрой) MS-SSIM. Интересно, что ее создатели сейчас продолжают работать над метрикой и связались с нами на предмет сабмита новых версий.
Также мы протестировали новую метрику от Tencent (середина графика), и Tencent начал взаимодействовать с нами.
Весьма доброжелательное письмо было из Google, которые также, естественно, работают над метриками и даже планируют выложить лучшие результаты в открытый доступ:
Very nice benchmark. Appreciate your team's contribution in video quality assessment. Our team (YouTube Media Algorithms) has built multiple VQA metrics, and we also plan to open source our models.
Интересно, что релиз бенчмарка был в марте-апреле этого года и санкции не помешали многим компаниями (включая западные) связаться с нами. Это радует.
В целом можно сказать, что с большой вероятностью в дальнейшем наиболее практические результаты в области метрик будут от исследовательских отделов компаний. Так происходит потому, что компаниям легче потратить заметные финансы как на большой датасет (что сегодня часто становится определяющим), так и на дорогих исследователей (которых не хватает).
Также из интересного стоит отметить, как неожиданно хорошо выступили на графике выше No-Reference метрики (зеленого цвета). Эти метрики анализируют только сжатый поток, не используя оригинал, поэтому для них предсказывать деградацию качества намного сложнее. Тем не менее довольно часто при реальном использовании надо оценить поток при отсутствии исходника, поэтому подобные метрики весьма востребованы и сейчас активно развиваются. Выше видны великолепные места MDTVSFA и Linearity, которые обогнали Full-reference (т. е. использующие исходник) метрики от Apple & Tencent! Более того, на стандарте AV1 No-Reference MDTVSFA лучше VMAF. А на стандарте VVC новая Linearity лучше VMAF!
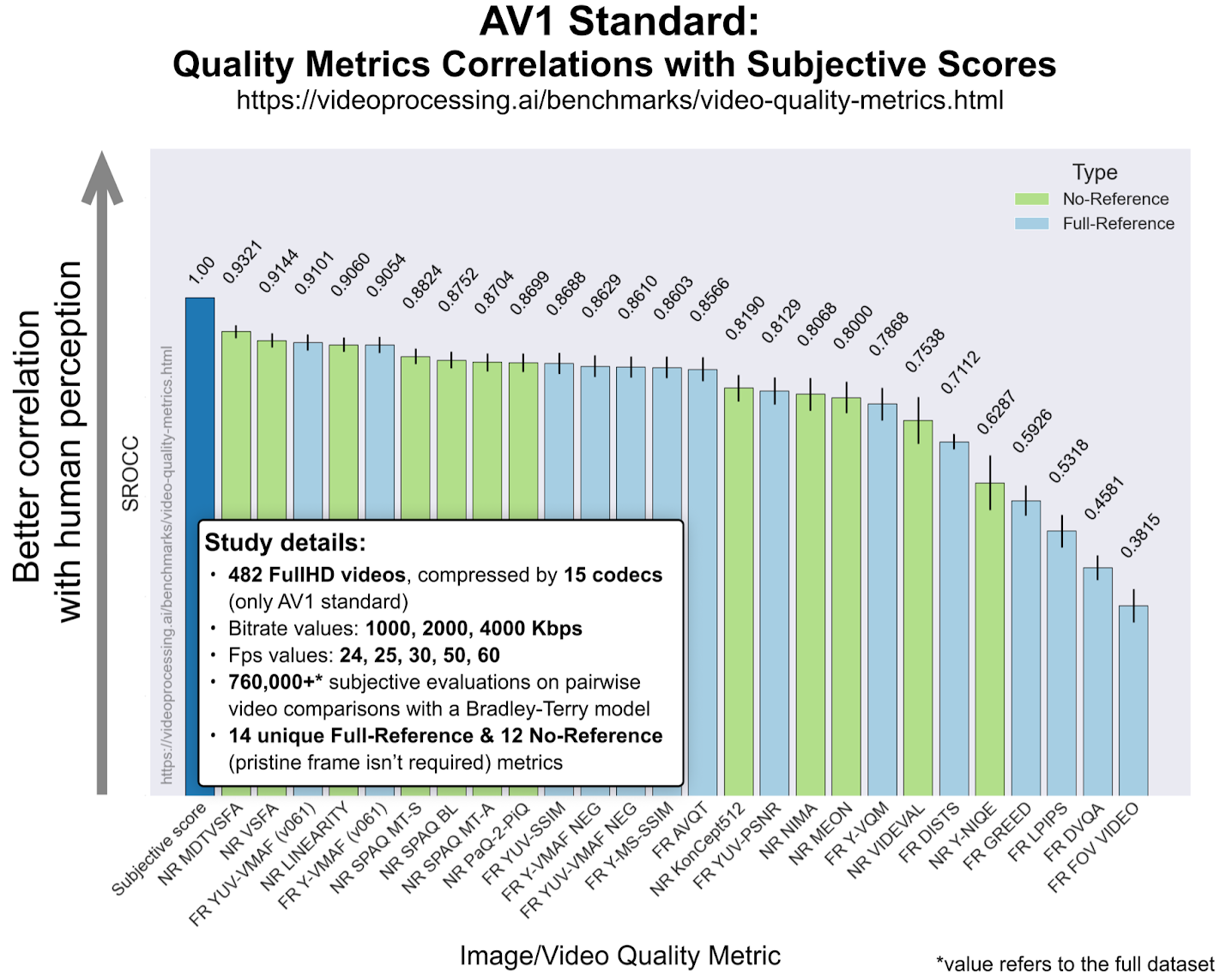
Источник: MSU No-Reference Video Quality Metrics Benchmark
Очень интересно и многообещающе, сказали мы с коллегами, и решили получше присмотреться к этим метрикам на предмет их устойчивости к взлому. Ибо если уж менять VMAF, то на что-то устойчивое. Эти No-Reference метрики являются дифференцируемыми и, как следствие, к ним применимы все виды нейросетевых атак, коих сегодня огромное количество (только по adversarial attack выходит более 10000 статей в год).
Мы решили присоединиться к этому празднику жизни и для семи новых перспективных No-Reference метрик предложили универсальную атаку, когда не для каждого кадра подбирается изменение (что на практике неудобно для видео), а для всего видео находим такую добавку, которая при применении к любому кадру давала бы повышение метрики. Статья об этом в ноябре выложена на arXiv (будучи принятой на BMVC 2022):

Источник: Universal Perturbation Attack on Differentiable NR Metrics
Если кратко основную суть, то ниже примеры «нейросетевого шума», подмешивание которого к картинке улучшает значение соответствующей метрики (согласитесь, выглядит модно молодежно очень по-нейросетевому):
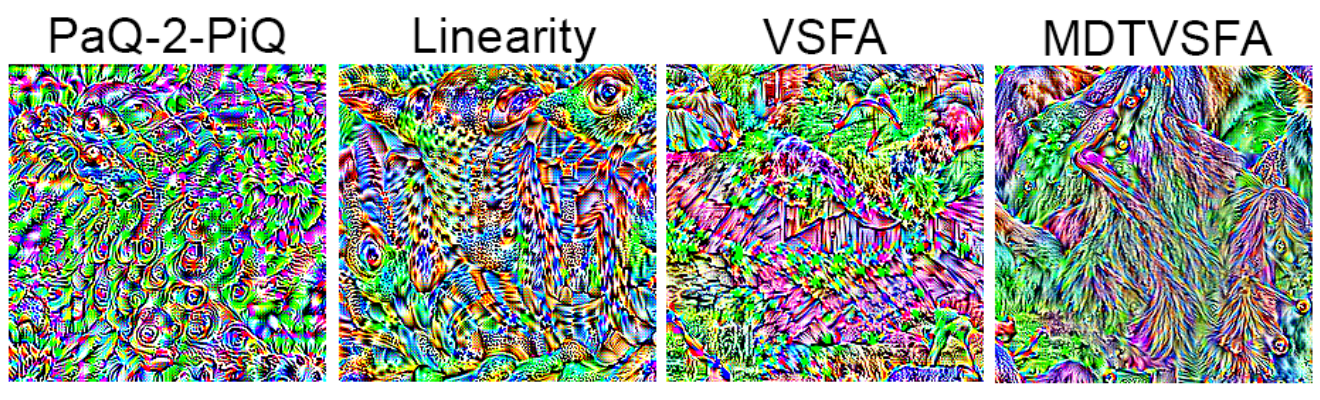

Источник: Universal Perturbation Attack on Differentiable NR Metrics
Причем можно подмешивать плавно, и значение метрики будет плавно расти, сигнализируя о том, что качество становится все прекраснее и прекраснее (или нет?):

Источник: Universal Perturbation Attack on Differentiable NR Metrics
Там еще много интересного, например, можно подмешивать этот шум так, чтобы снижать его заметность. Также можно и нужно анализировать метрики на устойчивость к такого вида атакам (а она разная!), впрочем, это уже довольно узкопрофессиональные темы.
Кстати, практики спрашивают, а можно ли накручивать две метрики одновременно? Ответ — да, но это сложнее:
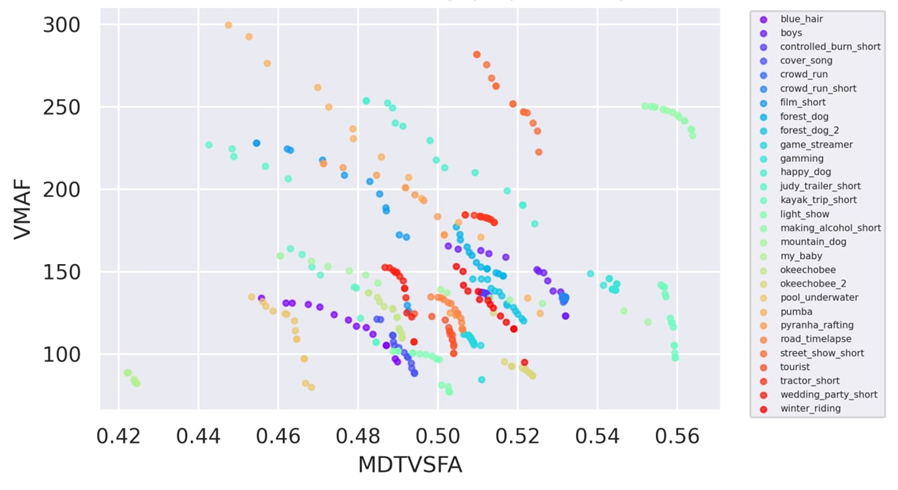
Источник: неопубликованные материалы автора
По сути разные методы дают разные эффекты при анализе накрутки на двух метриках одновременно, также эффект отличается для видеопоследовательностей. Поэтому если выбирать оптимальный метод относительно конкретной сцены в конкретной последовательности, можно существенно улучшить результат.
Получается, что новые метрики действительно очень хороши и обгоняют VMAF. Вот только что это означает на практике и можно ли их использовать именно для сравнения — вопрос открытый. В любом случае тема только начинается и там точно будет много интересного. Даже очень много! Как и в смежных темах.
Например, прямо сейчас идет разработка нового стандарта сжатия JPEG AI:

Источник: Documentation on JPEG AI
В последнее время появилось несколько стандартов, обогнавших не только JPEG, но и более сильный JPEG 2000, например, AVCI, HEIC и AVIF, поддерживаемые в HEIF. Пользователи Apple и профессиональные фотографы их уже оценили. Но это традиционные алгоритмы, а как же наши замечательные всепроникающие нейросети? Конечно, они также появились и уже несколько лет демонстрируют очень неплохие результаты:

Источник: лекции автора с коллегами
Впрочем, пока это все удел профессионалов и широкая публика об этом узнает, только когда Google Chrome поддержит JPEG AI, при том, что разработка стандарта пока только в начале пути. Так вот! Оказалось, что если мы используем нейросетевую метрику, то для нового дивного нейросетевого сжатия заточиться под нее оказывается не просто, а безобразно просто, и тема устойчивых метрик снова становится крайне актуальной.
Аналогичная ситуация с многочисленными нейросетевыми алгоритмами обработки видео, например, подавления шума, увеличения разрешения, увеличения битовой глубины и т. д. Добавить там метрику в том или ином виде в функцию потерь очень просто. И как теперь прикажете оценивать их качество? Древней PSNR, у которой отрицательная корреляция? Многие так и делают, но это почти «чистая наука» (в смысле неиспорченности практическим применением).
Естественно, с этими проблемами можно справляться, разберем кратко основные подходы:
Анализ относительного поведения тестируемых методов с использованием нескольких метрик. Суть подхода внешне очень проста: мы начинаем анализировать разницу в поведении нескольких тестируемых продуктов в нескольких метриках. И если поведение какого-то продукта заметно отличается — это повод для выводов.
Плюсы подхода:Как минимум «простая накрутка» с использованием одной метрики (например, тюнинг под VMAF) становится видна очень хорошо. Надеюсь, доберусь опубликовать анализ сравнения кодеков прошлого года, где хорошо видно, что кодек нового китайского стандарта сжатия видео AVS3 был очевидно заточен под VMAF.
Минусы подхода:
Существенно возрастает сложность сравнения, поскольку необходимо анализировать не только интересующий нас метод, но и несколько (чем больше, тем лучше) аналогичных ему, а также считать несколько метрик.
Нужно взять по возможности большее число последовательностей, причем разнородных с точки зрения анализируемого алгоритма. Не секрет, что разные продукты оптимизируются под разные практические кейсы, для адекватных выводов желательно покрыть большее количество кейсов, в т.ч. в терминах характеристик потока. Например, кодеки сильнее всего реагируют на временную и пространственную сложность, алгоритмы увеличения разрешения — на характер шума и т. д. Это также поднимает и вычислительную, и организационную (что выбирать) сложность сравнения.
Очевидно, что с ростом процента продуктов, имеющих заточку под метрики, сложность этого метода анализа в будущем также будет расти.
Визуальный анализ с использованием краудсорсинга и специализированных сервисов. Суть простая: в последнее время активно развивается краудсорс сравнения видео, когда мы используем условных толокеров, которым показывается результат работы продукта А и продукта Б и спрашивается, что лучше. Они дружно голосуют, далее, фильтруются читеры (которые могут быть довольно изощренными, к сожалению) и получается финальный результат.
Плюсы:Мы получаем довольно точную оценку именно того, как оценивает результат работы человек. Часто эта оценка намного точнее метрик. Но есть и существенные минусы.
Минусы:
Во-первых, нам достаточно дорого проверять таким образом много разных последовательностей, и обычно проверка является выборочной, а результат может серьезно зависеть от того, какие последовательности выбраны (т. е. при случайном выборе, например, результат разных проверок может сильно отличаться).
Во-вторых, прогон занимает время. На крупных сравнениях мы сталкивались с тем, что выбирали всех доступных пользователей Толоки и приходилось условно полсуток ждать, пока зайдет достаточное количество новых людей. Можно, конечно, использовать Amazon Mechanical Turk, где такой проблемы нет, но по нашему опыту там довольно много пользователей из условной Бангладеш и других замечательных стран, где очень плохая «последняя миля» интернета, что тоже можно (и нужно) скомпенсировать, но не бесплатно с точки зрения цены сравнения.
В-третьих, у тех, кто зарабатывает свои 5 центов на таких сервисах редко бывают хорошие экраны. Т. е. пробовать сравнивать, например, видео больше 2К — крайне проблематично. У нас сейчас задача — сравнить 8К видео заказчику. Она тоже решаема (4К мы сравниваем), но… сложность и цена процесса опять растут. Чтобы был понятен масштаб бедствия — толокеры пытаются проводить разметку с каких-то древних телефонов, планшетов и даже с электронных книг с 16 цветами…
Как обычно, наилучшие результаты дает комбинация этих двух методов. Но это опять увеличение сложности процесса. Теперь вы понимаете, почему я могу говорить сакраментальное: «Верить в наше время никому нельзя. Мне можно». Ибо окончание фразы говорится только в случаях, когда результат довольно плотно проверяется. Чаще, впрочем, приходится повторять только первую часть фразы.
Резюмируя вышесказанное:
К сожалению, скоро графики метрик качества видео в рекламных материалах компаний будут иметь значение близкое к нулю. А актуальность их глубокой проверки кратно возрастет.
Проанализировать, что происходит на самом деле за завесой повальной «тюнинговки», можно, но потребуется в несколько раз больше времени и сил, чем, например, 5 лет назад.
Китайцы захватят мир. Мало того, что сейчас большинство запросов на взлом и анализ взлома идут от китайских компаний, так и большинство публикаций по методам взлома сейчас смещается в Китай (у них рост идет быстрее остального мира). На нашем последнем семинаре с обзором лучших свежих работ по взлому метрик абсолютно все статьи были из Китая. У них много очень интересных и практичных работ, которые по нашим замерам немедленно (первыми в мире) внедряются в реальные промышленные продукты. Причем в некоторых случаях понять, что это было и как это сделано, крайне сложно даже для нас, начавших заниматься взломом метрик одними из первых. Думаю, что скоро они будут дурить профессионалов из компаний, как детей малых. Так меняется мир!
Вдогонку и в качестве анонса, если уж мы про метрики. Помимо super challenge с созданием относительно устойчивой ко взлому метрики, сейчас появился новый не менее трудный super challenge. Упоминавшееся выше нейросетевое сжатие и свежие нейросетевые алгоритмы обработки видео генерируют такие артефакты, которые ни новые, ни старые метрики не в состоянии ловить… Я показал много чудных картинок на недавнем VideoTech 2022, и меня полчаса после доклада не отпускали с вопросами о том, как мы теперь со всем этим будем жить. Если будет много лайков смогу найти время — обязательно об этом расскажу. Там большой вопрос, как в принципе строить метрику подобных артефактов.
Закончу пламенным обращением:
Граждане! Покупайте попкорн оптом! В области нейросетей в ближайшие годы вас ждет интереснейший цирк с конями! Это я как один из коней плотно занятый в теме говорю.
Сам смотрю на это с широко (как в аниме) открытыми глазами и не перестаю удивляться происходящему.
Stay tuned! )
Также можно почитать:
Уличная магия сравнения кодеков. Раскрываем секреты — большая статья с описанием способов «донейросетевого» читинга при сравнении кодеков.
Deep Fake Science, кризис воспроизводимости и откуда берутся пустые репозитории — статья, которая частично объясняет, почему у тысяч научных статей, посвященных метрикам качества видео такой низкий КПД и почему он будет падать (была лучшей в номинации «Искусственный интеллект» конкурса Технотекст за 2020 год).
О русской науке замолвите слово или за что я люблю Тинькофф, часть 1 — статья, которая объясняет, почему китайцы будут лидерами по многим научным направлениям (была лучшей в номинации «Образование в IT» конкурса Технотекст за 2021 год).
Благодарности
Хотелось бы сердечно поблагодарить:
в первую очередь своих коллег Михаила Ерофеева, Анастасию Анциферову, Сергея Лаврушкина, Романа Казанцева, Александра Гущина, Максима Смирнова, Максима Синюкова, Евгения Богатырева, Екатерину Шумицкую, Максима Хребтова, Абуда Халеда за проведение работ в данной области, чьи результаты нашли отражение в статье,
родной ВМК МГУ, Центр доверенного ИИ ИСП РАН и Институт ИИ МГУ за материальную и моральную поддержку развития данной темы,
и, наконец, огромное спасибо Кириллу Малышеву, Егору Кашкарову, Константину Кожемякову, Максиму Железову, Анастасии Анциферовой, Николаю Каретину, Дарье Романовой, Екатерине Шумицкой, Алексею Брынцеву, Георгию Осипову, Александру Яковенко, Николаю Сафонову, Максиму Смирнову, Федору Притуле, Халеду Абуду, Егору Чистову, Евгению Богатыреву и Михаилу Дремину за большое количество дельных замечаний и правок, сделавших этот текст намного лучше!
