Comments 111
Статья несколько сумбурная, так как изначально в ней я хотел добавить обзор языка, а не только то, что мне в нём понравилось. Но в итоге обзор убрал, так как сам не всё ещё хорошо знаю о Zig.
Так же я готовлю отдельную статью про использования кода написанного на языке C в проекте на языке Zig, но я уже вижу, что при написании статьи будут проблемы, так как не все возможности языка C полноценны в языке Zig. Но всё же raylib мне удалось завести, так что придумаю что-нибудь
Суть в том, что файл, который управляет сборкой проектов для Zig - это файл с кодом на языке Zig
В Cargo то же самое, только он не обязателен для простых случаев.
По умолчанию при создании проекта из cargo создается файл Cargo.toml, который отвечает за настройку сборки. В Zig сразу создаётся файл build.zig, и настройка выполняется через него. Может быть в будущем произойдёт переход на упрощение сборки, но пока именно так
Лучшая идея, что встречалась мне. Даже Rust (при наличии Cargo) и Go уступают. Суть в том, что файл, который управляет сборкой проектов для Zig — это файл с кодом на языке Zig
В Zig сразу создаётся файл build.zig, и настройка выполняется через него. Может быть в будущем произойдёт переход на упрощение сборкиТ.е. идея лучшая, но получилось сложно. В чём же тогда плюсы этой идеи?
По умолчанию при создании проекта из cargo создается файл
Cargo.toml, который отвечает за настройку сборки.
Да, потому что чаще всего декларативного описания хватает. Но если не хватает, то можно и к императивному подходу обратиться. А в Zig сразу императивный, причём вы сначала говорите, что это лучший подход, а потом пишете, что, возможно, Zig перейдет на более простой метод. То есть подход лучший, но не простой? Чем же он тогда лучший?
То есть подход лучший, но не простой?
И у вас такой же вывод. Может быть я не правильно выразился. Или вас слово «лучший» задевает, что Rust в этом контексте не лучший? Тогда попробую уточнить.
Простота несомненно это хорошо. Но иметь гибкость в работе тоже нужно. Rust имеет возможность использовать скрипт для сборки, но часть функционала всё же вне самого компилятора, и для более простой работы с C надо подгружать внешнюю библиотеку. Или как это по-растовски - crate. В то время как в Zig это всё часть компилятора. То есть доступно сразу
Это все хорошо до тех пор, пока не выясняется, что тулинг теперь без компилятора не способен понять, а какие у вас там зависимости. Запускать непонятно кем написанный код, чтобы поизучать в IDE проект — ну такое себе
Запускать непонятно кем написанный код, чтобы поизучать в IDE проект — ну такое себе
То ли дело:
https://github.com/eleijonmarck/do-not-compile-this-code
Могут быть проблемы не только с макросами, но и билд-"скриптами", если мы говорим о сборке (разворачивание процедурных макросов в IDE ведь можно отключить). Скорее речь о том, что наличие процедурных макросов, билд-файлов и левых зависимостей проще отслеживать в Rust-проектах. Грубо говоря, если вы скачали hello-world и в воркспейсе проекта есть build.rs или определён крейт с процедурным макросом, или имеются какие-то левые зависимости не из crates.io, то это повод провести тщательный аудит проекта до запуска.
...пока не выясняется, что тулинг теперь без компилятора не способен понять, а какие у вас там зависимости.
Так ведь это проблема всех языков программирования. При том, что без компилятора всё равно не получится собрать нужное. Странная претензия.
Ну, нет. Условный crates.io в одном случае должен распарсить файл известного формата своим доверенным парсером, чтобы понять зависимости вашего проекта, а в другом — выполнить недоверенный код.
...а в другом — выполнить недоверенный код.
Очень странно. Это как программист добавляя в код библиотеку может ей не доверять?
Я понял вашу изначальную претензию, но тут проблема уже восприятия. Я не вижу проблем использовать скрипт, это примерно тоже самое, что и скрипты для cmake, meson, gradle и другие системы сборки. Как тюллинг работает с ними? Вопрос риторический. Потому и мне кажется, что претензия странная
Очень странно. Это как программист добавляя в код библиотеку может ей не доверять?
Как бы владельцы (кода) crates.io и программист, загружающий в реестр свою библиотеку со скриптом сборки — это разные люди...
Все же было бы лучше, если скрипт был дополняющей системой, когда нужно сделать что-то уж совсем нестандартное, а не единственной.
И у вас такой же вывод. Может быть я не правильно выразился.
Просто вы пишете, что это -- лучшая идея. А потом сразу же пишете, что это сложно и настройка билда в одном файле [как в Rust] было бы упрощением. На мой взгляд это немного противоречит друг другу.
Rust имеет возможность использовать скрипт для сборки, но часть функционала всё же вне самого компилятора, и для более простой работы с C надо подгружать внешнюю библиотеку.
Как-то вы неожиданным образом перешли от использования скрипта для сборки к подгрузке внешней библиотеки (это какой? crate это не библиотека, он будет вкомпилен в ваш бинарник как составная часть, после компиляции внешним он не будет) через функциональность компилятора. Или чтобы использовать скрипт для сборки надо какую-то внешнюю библиотеку использовать? Нет, не нужно, компилятор это из коробки умеет.
А потом сразу же пишете, что это сложно
Я этого не писал. Не придумывайте. Я не считаю срипты сборки сложным элементом. То что я имею в виду про упрощение, это, как я это вижу, улучшение инлюзивности. То есть такое в будущем возможно. Нужно ли?
crate это не библиотека, он будет вкомпилен в ваш бинарник как составная часть, после компиляции внешним он не будет
%шутка_про_милиниалы_изобрели%
Тут я сделаю уточнение. Я язык Zig рассматриваю как замену языка C. И с точки зрения этой концепции Zig имеет всё необходимое в комплекте. Без необходимости подгружать что-то. Именно поэтому я не стал глубоко изучать Rust. Так как для меня он не замена C. В Rust необходим unsafe контекст для работы с C, что накладывает свои требования к написанию кода. Это те ограничения, которые мне не нравятся в Rust. И если так хотите, то именно по этому я считаю Zig лучше
pub fn main() !void
Нет ничего, что вызывало бы вопросы.
Ну ладно pub скорей всего публичная, fn видать функция, main её имя, в скобках могли быть ваши параметры, но !void это что значит возвращает НЕ void? Вот честно мне не очень понятно.
Ну вот честно догадаться об этом очень сложно, и вопросы оно таки вызывает. Особенно учитывая что ниже по коду ! используется просто как отрицание.
PS. Почему если уже впихнули слова pub и fn нельзя было добавить слово обозначающее что может быть ошибка, почему это ушло в часть возвращаемых значений. Это вопросы не к вам конечно, просто мысли в слух....
Целочисленный тип в Zig обозначается i32 (знаковый) или u32 (беззнаковый), но при этом цифра после может быть любая (вплоть до 65535). То есть этот тип может содержать необходимое программисту количество бит.
Вопрос так и остался без ответа - вертать i32 или !i32?
Тема обработки ошибок/исключений не раскрыта. Многопоток и синхронизации тоже. Тема с аллокаторами вроде интересная, но опять же без особых деталей.
А jai/odin не пробовали?
Вопрос так и остался без ответа - вертать i32 или !i32?
Просите. Волнуюсь. Первая статья.
Если в коде нужно вернуть(пробросить дальше) ошибку из функции, то восклицательный знак нужен, а без ошибок не нужно. То есть восклицательный знак указывает, что функция может вернуть ошибку, которую либо отдаём дальше, либо обрабатываем.
Если не обрабатывать ошибки, и что-то внутри функции «крякрет» (то есть бросит ошибку), приложение упадёт. Это официальное закрепленное поведение.
Обработка ошибок происходит двумя способами. Через ключевое слово try и через ключевое слово catch. try используется тогда, когда вызываемая функция может вернуть ошибку, но в данный вызов этой функции обрабатывать ошибку мы не можем или не хотим, и try при получении ошибки завершает выполнение текущей функции и возвращает полученную ошибку. catch же не завершает текущую функцию, а выполняет код, который программист укажет в блоке. Примерно тоже самое, что и исключения в некоторых языках, но это не исключения, так как нет разматывания стека в типичном понимания термина.
Пример синтаксиса:
fn foo() Error!void {
const x = try bar();
buz(x);
}
fn foo2() void {
const x = bar() catch 13;
buz(x);
}А jai/odin не пробовали?
Я про них забыл. Пробовал. Мне не понравился синтаксис у них, оба очень схожи, хотя позиционируются создателями несколько иначе. Заменой C они явно не станут. Работа с библиотеками на C у них иная. Сложнее чем в Zig
На днях вышла статья (на английском). Как раз про обработку ошибок в Zig
Вот честно мне не очень понятно.
Это потому что вы ещё не знаете синтаксис языка Zig. Восклицательный знак перед возвратным типом означает, что функция может вернуть ошибку. Это часть механизма обработки ошибок.
Про читаемость я имел в виду отсутствие многоуровневых блоков, которые просто визуально сложно воспринимать. Те же макросы в C. Особенно когда их много вложенных друг в друга. Сами по себе макросы не проблема. Проблема то как их используют. Или указатели на функции в C. Что-то типа такого:
void (*operations[3])(int, int)И это не самый проблемный пример
Восклицательный знак перед возвратным типом означает, что функция может вернуть ошибку.
Я выше писал, почему не сделать нормально читаемое слово перед в объявлении функции чтобы было типа:
pub canerror fn main() void {
или типа того, зачем мучать бедный ! двумя операциями, а тех кто на этом пишет, заставлять помнить в каком месте заклинания ! какое значение имеет?
В Zig можно определять конкретный тип ошибки для возврата. Очередной пример из моего эксперимента с raylib:
pub fn init(a: Allocator) Allocator.Error!ResourceManager {
return .{
.allocator = a,
.resources = ResourceList.init(a),
};
}Тип ошибки располагается перед восклицательным знаком. И длинные возратные типы выглядят как «хлам». А как «хлам» лучше читается? В начале функции, или в конце?
После того как в C++ появились конструкции типа этой:
auto main() -> int {
return 0;
}Читаемость чуть улучшилась, так как выравнялись строки. И поиск глазами стал проще
В Zig можно почти словами читать: публичная функция init с параметром a типа Allocator возвращает Allocator.Error или ResourceManager
Тогда было бы логичней использовать |. Он везде читается как "или".
Это относится к первичному значению восклицательного знака. Типа «Внимание!». Или «Будьте внимательны!». Это странно только пока об этом не знаешь. Первый раз, когда я только узнал о Zig, был примерно аналогичный момент. Но в голове как-то сразу отложилось, что это бред какой-то. Как-то не вяжется системный язык программирования и возможность возвратить любое значение кроме `void`. А когда прочитал о возвратах ошибок понял что к чему
Читаемость чуть улучшилась, так как выравнялись строки. И поиск глазами стал проще
Честно я в основном в Си работаю. Но я правильно понимаю что это тот же самый
int main() {
return 0;
}Только мы добавили слово auto и -> и теперь начиная читать строку я вижу что main вернет хрен пойми что, потом понимаю что int. С++никам конечно видней, но по мне читаемость вот именно в этом примере стала только хуже.
...в этом примере стала только хуже.
Почему? Представьте, что у вас не одни main, а пачка функций. Сотни. И у всех свои возвратные значения разной длинны написания. Читать не очень удобно. За года, конечно, привыкаешь к этому. Я тоже привык. Но до сих пор бывают моменты, когда меня задевало то, что возвратный тип иногда был слишком длинным и мешал читать код. Есть варианты написания типа возвратного значения и названия функции на разных строчках. Типа:
int
main() {
return 0;
}Но он не улучшает читаемость. Только после того, как в C++ появился вариант с auto стало чуть лучше.
Когда я в Pascal в первый раз увидел вариант с ключевым словом перед название функции, мне это очень понравилось. Сразу было понятно где что. Кончено, лаконичность C меня тоже манила, потому я C++ начал учить, но эта лаконичность в итоге оказалось мнимой
Сотни. И у всех свои возвратные значения разной длинны написания. Читать не очень удобно.
Видимо я слишком молод/стар чтобы понять эти заморочки. Хотя писать доводилось на разных языках
Кончено, лаконичность C меня тоже манила
Вот она и сейчас манит. Поэтому все эти fn, вроде оно короче конечно чем function, а вроде и вообще не нужно.
В общем вкусовщина, но если кому-то нравится то почему бы и нет.
Видимо я слишком молод/стар чтобы понять эти заморочки.
Когда приходится многократно дописывать, переписывать, свой же код, то начинает лезть желание код привести в читаемый вид. А с точки зрения C-подобных языков это сложно, так как синтаксис исторически так сложился. Поэтому я лично за то, чтобы и в них что-то похожее завезли. Но этому уж точно не бывать в C. В C++ есть еще надежда, если Херб Саттер продавит свой C++2 в комитете по стандартизации
С++никам конечно видней
Return trailing type здесь излишне и абуз языка.
С 17+ стандарта завезли автоматический вывод типов и возможность фиксировать возвращаемый тип что полезно для лямбд.
Примеры с комментариями
g++ prog.cpp -Wall -Wextra -std=c++17
#include <iostream>
#include <functional>
#include <algorithm>
#include <array>
enum class Order {
Left,
Right,
South,
North,
};
struct MyStaff {
int x,y;
Order naughty_cmp(const MyStaff& other) const{
return y < other.y
? Order::North
: Order::South;
}
};
int main() {
std::array arr {
MyStaff{1,2},
MyStaff{2,1},
MyStaff{2,2},
MyStaff{-1,2},
};
// будет иметь тип вроде const lambda_7677876be8
// который можно явно объявить как std::function<bool()>
// но зачем?
auto const sorter1 = [](auto const& left, auto const& right) -> bool {
if (left.x == right.x) {
// ругнётся на эту ветку потому
// что сигнартура явно требует bool
// а возвращают Order
// error: cannot convert 'Order' to 'bool' in return
return left.naughty_cmp(right);// == Order::South;
} else {
// а тут всё ок
return left.x < right.x;
}
};
// тут возвращаемый тип будет выводиться, на основе вызывающего кода
// если код скастился к вызываемому типу, то даже ворнинг не появится
// если явно указать возвращаемый тип, то прям тут же появится
// warning: '?:' using integer constants in boolean context
auto const sorter2 = [](auto const& left, auto const& right) // -> bool
{
return left.x == right.x
? 0
: 2 ;
};
std::sort(arr.begin(), arr.end(), sorter1);
std::sort(arr.begin(), arr.end(), sorter2);
return 0;
}Но по коду выше действительно пример с main просто несколько неудачный оказался.
Ну вообще, есть много других способов описания функций с достаточно неплохой читаемостью. Например:
dcl-proc cvtDte2CYMD export;
dcl-pi *n zoned(7: 0);
dte char(10) value;
end-pi;dcl-s rslt zoned(7: 0) inz;
...
return rslt;
end-proc;
dcl-proc - declare procedure
Дальше - имя процедуры (смещение от начала строки всегда одинаковое)
После имени - различные модификаторы (в данном случае - процедура экспортируемая)
Дальше - блок dcl-pi - declare procedure interface - описание интерфейса:
*n zoned(7: 0) - *n - неименованный параметр, zoned(7: 0) - типа параметра. Это тип возвращаемого значения.
Внутри блока перечисление аргументов процедуры. В данном случае он один.
dte char(10) value; - аргумент - имя, тип, модификатор (в данном случае - передается по значению).
Далее объявления локальных переменных (dcl-s - declare standalone variable, может быть еще dcl-c - declare constant или dcl-ds - declare data structure или dcl-f - declare file).
Далее понятно - тело процедуры, возврат значения. И конец - end-proc.
Все достаточно читаемо.
Прототип в заголовках определяется похоже:
dcl-pr cvtDte2CYMD zoned(7: 0) extproc('cvtDte2CYMD');
dte char(10) value;
end-pr;Тут все проще - dcl-pr - declare prototype, далее имя процедуры, тип возвращаемого значения, модификаторы (в данном случае ссылка на экспортируемое имя).
Внутри блока - список аргументов как в dcl-pi в самой процедуре.
и опять - отступ всех имен фиксирован от начала строки. Все подробности потом.
Вот что за мания ключевые слова сокращать? Что авторы экономят? Читаемость кода так улучшают.
Не знают же об autocomplete, а ручками писать лень)))
Не все ж джависты с полутораметровыми мониторами, чтобы головой вертеть все эти `public static abstract ClassNameAbstractProduction extends private static ClassName2 ....`. Ну и процессорного времени меньше жрать будет на сравнение длинющих строк в компиляторе, LSP и прочих местах.
Я пробовал на нём GTK. И оно работало. IUP есть. Удобство, что можно привязать любой проект на C
превосходно можно юзать любой гуй, который можно юзать из C. я, например, на winapi пробовал
Я попробовал ряд библиотек, и возможно на это будет отдельная статья, типа обзор gui фреймворков
Я как-то тоже решил поискать современный аналог Си, но без лишних наворотов. Zig, наверное, единственный адекватный кандидат.
Проникся уважением к автору Zig, когда посмотрел это видео - https://www.youtube.com/watch?v=Z4oYSByyRak . ИМХО, грамотно рассуждает и зрит в корень.
const std = @import("std");
const raylib = @import("raylib");
const ResourceManager = @import("resourcemanager.zig").ResourceManager;
const ScreenManager = @import("screenmanager.zig").ScreenManager;
const allocator = std.heap.c_allocator;
pub fn main() !void {
const screen_width = 800;
const screen_height = 450;
raylib.Window.init(screen_width, screen_height, "Test Window");
defer raylib.Window.close();
raylib.AudioDevice.init();
defer raylib.AudioDevice.close();
var resouce_manager = try ResourceManager.init(allocator);
defer resouce_manager.deinit();Да можно другую подсветку включить )
Не знаю, как по мне Zig недалеко ушёл от C. Он не предлагает ничего лучшего чем сам C.
Все также необходимо быть внимательным и следить за висячими ссылками, нулевыми указателями.
Ну нужно явно передавать аллокатор. И что? Никаких гарантий что где-то, кто-то не сохранит указатель на этот аллокатор и не будет его использовать как ему захочется.
А какая головная боль с асинхронным кодом в C. Zig это решает? Да нет, все тоже самое.
Зачем такой язык нужен, если не предлагает ничего координально нового и самое главное легкого? Легкий синтаксис не облегчает знаете ли написание асинхронного кода.
В этом плане уж лучше Rust. Да немного громоздкий синтаксис. Зато как спокойно ?. Прям закачаешься ?
Весь ваш комментарий далёк от реальности. И я не буду спорить о том, что чего-то нет в самом языке, и это факт, что чего-то нет. Глупо ставить на этом претензию к языку, так как он ещё на пути разработки. Сделаю только ремарку, что более удобная асинхронность в планах на версию 0.12.0
Я только не понимаю, почему все считают синтаксис Rust сложным? Единственное, чем у меня была проблема - турбофиш
А что там с IDE?
Официальной IDE нет. Вроде как и не рассматривается. Можно использовать VSCode. И для ряда текстовых редакторов есть плагины. Более подробнее по ссылке: https://ziglang.org/learn/tools/
У IntelliJ IDEA есть плагин ещё https://plugins.jetbrains.com/plugin/10560-zig
Претензии автора статьи к C++ и желание откатиться к Си - смехотворны. У C++ в сравнении с Си только один недостаток - больше времени нужно на изучение. В остальном одни только достоинства. Си использовать стоит только там, где это ну никак нельзя - или компиляторов под нужную платформу нету, или это ядро Linux и за C++ код тов. Торвальдс там матом кроет.
Что касается ZIG: выглядит как проект неосиляторов более серьёзных языков вроде C++ и Rust. Отсутствие деструкторов ставит крест на надёжности зарабатываемых программ, т. к. даёт широчайшие возможности забыть что-то освободить (отдать память, закрыть файл и т. д.). Причина выбjра такого подхода рациональному разуму не поддаётся - тут только приходит на ум некий иррациональный страх над (мнимой) сложностью C++.
это ядро Linux и за C++ код тов. Торвальдс там матом кроет
А вот Rust как раз можно :)
Причина выбjра такого подхода рациональному разуму не поддаётся - тут только приходит на ум некий иррациональный страх над (мнимой) сложностью C++.
Причины вполне понятны. Дело в том, что на С пишут "достаточно специфические люди". Которые примерно знают во что превратится их код на ассемблере (не до строчки, но примерено представляют). И для них это критично (ресурсы, быстродействие и т.п.).
Когда ты пишешь на С++, ты никогда не знаешь во что выльется твой код. Что стоит за вызовом той или иной функции - сколько там будет динамических выделений/освобождений памяти, сколько создастся/схлопнется уровней стека и т.п. А в ряде ситуаций это достаточно критично (и сам не раз с этим сталкивался когда ++-й код не проходит по быстродействию, а написанное на чистом С проходит, или по ресурсам когда с нагрузочном тестировании тебе вываливают PEX статистику с претензией что динамическая работа с памятью в плюсовых либах отжирает 2-3% ресурсов процессора).
В этом плане С и С++ радикально разные языки. И для некоторых вещей, где традиционно используется С, С++ не подходит (ну или надо писать на нем в очень специфическом стиле).
Дело в том, что на С пишут "достаточно специфические люди". Которые примерно знают во что превратится их код на ассемблере (не до строчки, но примерено представляют).
Ага, а потом очень обижаются, когда их столетний говнокод перестаёт работать из-за того, что новая версия компилятора начинает абузить UB в их коде.
И да, они почти наверняка не знают.
Когда ты пишешь на С++, ты никогда не знаешь во что выльется твой код. Что стоит за вызовом той или иной функции — сколько там будет динамических выделений/освобождений памяти, сколько создастся/схлопнется уровней стека и т.п
Надо же, совсем как в C!
(и сам не раз с этим сталкивался когда ++-й код не проходит по быстродействию, а написанное на чистом С проходит ...)
Это очень странная ситуация, потому что (почти) всё, что можно написать на C, можно написать и на C++. И, к слову, C++ не заставляет использовать динамическую аллокацию памяти.
Конструкция с блоком и break похожа на продолжения.
Вы правы, но всё несколько сложнее, так как эту конструкцию можно использовать в циклах для перехода между вложенными циклами. И там, да, есть и continue. Пример из документации:
test "nested continue" {
var i: usize = 0;
outer: while (i < 10) : (i += 1) {
while (true) {
continue :outer;
}
}
}
Я имет в виду continuation, механизм сохранения/восстановления контекста из мира ФП.
Суть в том, что файл, который управляет сборкой проектов для Zig - это файл с кодом на языке Zig
пожалуй на любом языке можно вызвать компилятор как внешнюю программу и сделать тем самым свою систему собрки с нескучными обоями, выглядит только это обычно довольно страшненько по сравнению даже с просто шелл скриптами.
...выглядит только это обычно довольно страшненько по сравнению даже с просто шелл скриптами.
Всегда есть место для улучшений. Я с недавних пор вместо cmake стал чаще применять meson. Что то, что это - «Аксиома Эскобара», но Meson, как-то адекватнее выглядит в этом плане.
За ссылку спасибо. Унёс себе в закрома
Осталось за кадром вот что: что же всё таки лучше в этом новоязе чем в Си ? Ну допустим вам значок "@" понравился - ладно (мне например нравиться "$" вкорячивать, а других тошнит, ну и по фигу) - а где описание мук и проблемы выбора от автора, что заставили (таки заставили) уйти с накопившего многодесятилетние знания языка на новояз, да ещё с неясным будущим.
Вы сделает пару проектов, и свалите (пардон) - вновь прибывшим останется такое вот наследство. По-моему это совсем не инженерный подход и, скорее, будет подлянкой использовать такое средство - или этот фактор с умыслом, намеренно оставлен за скобками ?
что же всё таки лучше в этом новоязе чем в Си ?
Вы это спрашиваете как C программист? Потому что проблемы языка C известны. Статья, которую я написал лишь описывает, что мне понравилось, а не весь язык в целом. Я в первом комментарии написал причину, которой не стал делать полный обзор языка.
А вторую часть комментария я вообще не понял. Вы за меня приняли решение, меня же в этом решении обвинили, задали какой-то странный вопрос
Вопросом на вопрос ? Нет проблем у языка Си большем чем у других. Есть уровень владения средством.
Повидал много диалектов Си, всё было "клёво" и занятно - и настолько же бестолково и сиюминутно. Вот природа вопроса.
Чем вам поможет если я отвечу что спрашиваю как допустим BLISS-пограмиила или MACRO и FORTRAN или Си?
Из того что вам понравилось я таки не понял как на этом новоязе шлёпать драйверы - коли уж статья в категории "Системное программирование".
Из того что вам понравилось я таки не понял как на этом новоязе шлёпать драйверы
Точно также как на C. Логика языка Zig невилировать недостатки языка C. Сделать взаимодействие с ним проще. Мне лично этого было достаточно, чтобы попробовать с Zig поработать. И на данный момент меня он устраивает. Он мне нравится больше
Логика языка Zig невилировать недостатки языка C. Сделать взаимодействие с ним проще.
Ну вот как пример. Я сейчас много пишу на языке RPG (до это около 25 лет на С/С++, причем, больше в сторону С).
Ни в коей мере не конкурирует с С т.к. это язык с уклоном в реализацию бизнес-логики. Но. Там есть вещи, которых мне (когда нужно что-то делать на С) хотелось бы видеть в С.
Логика работы со структурами.
В RPG структура рассматривается как некий блок данных, внутри которого определены поля. Простейший случай ровно как в С:
dcl-ds dsMyStruct;
intField int(10);
charField char(50);
end-ds;Тут все просто. Но на самом деле все намного гибче. Можно задавать размер структуры явно и явно указывать положение поля внутри структуры:
dcl-ds dsMyStruct len(512);
intField int(10) pos(50);
charField char(50) pos(150);
end-ds;Тут мы имеем блок 512 байт в котором нас интересует только целое в 50-й позиции и строка в 150-й, остальное не наше дело.
Поля могут накладываться друг на друга. Как union в С, но без union, просто накладываем и все
dcl-ds dsMyStruct;
Field1 char(50);
Field2 uns(3) dim(50) samepos(Field1);
end-ds;Наложили на строку 50 символов массив из 50-ти баззнаковых байт.
Причем, наложение может быть с пересечением - не проблема
dcl-ds dsMyStruct;
Field1 char(20);
Field2 char(20);
Field3 char(20) pos(11);
end-ds;Третье поле перекрывает вторую половину первого и первую половину второго.
Для массивов внутри структур еще хитрее
dcl-ds dsMyStruct;
arrA char(10) dim(10);
arrB char(5) overlay(arrA);
arrC char(5) overlay(arrA: *next);
end-ds;Тут описан массив А - 10 элементов по 10 символов. Но каждый символ состоит из двух частей по 5 символов. Массивы В и С позволяют непосредственно обращаться к каждой из частей. Например:
arrA(1) = 'abcdefghij';
arrA(2) = 'klmnopqrts';и тогда
arrB(1) = 'abcde';
arrC(1) = 'fghij';
arrB(2) = 'klmno';
arrC(2) = 'pqrts';И все это без лишних сущностей, просто в рамках описания структуры.
При описании структуры можно сразу задавать начальные значения полей (инициализация). В том числе и в том случае, когда структура описывается как шаблон (аналог typedef в С)
dcl-ds t_dsMyStruct template;
intField int(10) inz(350);
charField char(50) inz('Initial string');
end-ds;Тут описан шаблон (без создания переменной) структуры с инициализированными полями. Чтобы создать переменную соответствующей структуры
dcl-ds dsMyStruct likeds(t_dsMyStruct) inz(*likeds);Создается структура "такая же как" и инициализируется "так же как".
В структурах можно использовать неименованные поля. Вместо всяких reserved, tmp, dummy и т.п.
dcl-ds t_dsISODate qualified template;
YYYY char(4) inz('2000');
*n char(1) inz('-'); // разделитель
MM char(2) inz('01');
*n char(1) inz('-'); // разделитель
DD char(2) inz('01');
strDate char(10) pos(1); // дата в виде строки
end-ds;
// После такого объявления dsISODate.strDate = '2000-01-01'
dcl-ds dsISODate likeds(t_dsISODate) inz(*likeds);
// А после этого dsISODate.strDate = '2023-08-09'
dsISODate.YYYY = '2023';
dsISODate.MM = '08';
dsISODate.DD = '09';Все это позволяет достаточно просто описывать достаточно сложные структуры данных.
Далее. Переменные. Здесь не может быть неинициализированных переменных. Любая объявленная переменная при компиляции инициализируется дефолтным для ее типа значением, если не указано иного.
Есть два оператора:
clear <varName>;Сброс значения переменной к дефолтному для ее типа.
И
reset <varName>;Сброс значения переменной к значению указанному при инициализации.
// тут intVar1 = 0, intVar2 = 15
dcl-s intVar1 int(10);
dcl-s intVar2 int(10) inz(15);
// тут intVar1 = 100, intVar2 = 150
intVar1 = 100;
intVar2 = 150;
// тут intVar1 = 0, intVar2 = 0
clear intVar1;
clear intVar2;
// тут intVar1 = 150, intVar2 = 50
intVar1 = 150;
intVar2 = 50;
// тут intVar1 = 0, intVar2 = 15
reset intVar1;
reset intVar2;Для переменных, которые были инициализированы по умолчанию, reset тождественен clear
"Спецзначения". Их много всяких, начинаются с '*' - *next, *var, *auto и т.п. В целом просто синтаксис языка, но особо хотелось бы отметь два: *loval и *hival - минимально и максимально возможные значения для данного типа переменной. Не надо думать где и как описано максимально/минимальное значение для данного типа - просто ставим *hival/*loval - компилятор сам разберется
// packed - формат данных с фиксированной точкой
// в данном случае - 15 знаков, без десятичных для результата
// и 63 без десятичных для промежуточных вычислений
dcl-s calcValue packed(63: 0);
dcl-s resValue packed(15: 0);
// максимальные и минимальные значения для resValue
// тут еще один сахарок - объявляем переменную "такую же как"
dcl-s maxValue like(resValue) inz(*hival);
dcl-s minValue like(resValue) inz(*loval);
// делаем какие-то промежуточные вычисления
calcValue = ...
// размерность calcValue больше чем resValue
// поэтому напрямую присваивать нельзя - может быть переполнение
// безопасно - с контролем выхода за границы допустимых значений
select;
when calcValue < minValue;
resValue = minValue;
when calcValue > maxValue;
resValue = maxValue;
other;
resValue = calcValue;
endsl;Тут суть в том, что для calcValue диапазон значений от -9999...999 (63 девятки) до 9999...999 (63 девятки), а для resValue - от -9999...999 (15 девяток) до 9999...999 (15 девяток). Поэтому объявляем переменные с граничными значениями "такие же как" resValue и инициализируем их минимальным и максимальным значениями именно для packed(15: 0). И с ними сравниваем промежуточный результат.
Будь подобное (структуры, инициализация, спецзначения...) реализовано в С (или ему подобном языке), читаемость кода (да и удобство) было бы выше.
Такое бы хорошо отдельной статьей. Интересные вещи
Тут мы имеем блок 512 байт в котором нас интересует только целое в 50-й позиции и строка в 150-й, остальное не наше дело.
Такое, кстати, есть в Zig. packed struct. Можно указать тип данных под которые он выравнивается. Очередной пример из моего эксперимента с raylib:
pub const Config = struct {
/// System/Window config flags
/// NOTE: Every bit registers one state (use it with bit masks)
/// By default all flags are set to 0
pub const Flags = packed struct(u16) {
_: bool = false, //0
fullscreen_mode: bool = false, //2,
window_resizable: bool = false, //4,
window_undecorated: bool = false, //8,
window_transparent: bool = false, //16,
msaa_4x_hint: bool = false, //32,
vsync_hint: bool = false, //64,
window_hidden: bool = false, //128,
window_always_run: bool = false, //256,
window_minimized: bool = false, //512,
window_maximized: bool = false, //1024,
window_unfocused: bool = false, //2048,
window_topmost: bool = false, //4096,
window_highdpi: bool = false, //8192,
window_mouse_passthrough: bool = false, //16384,
interlaced_hint: bool = false, //65536,
pub fn to_u16(self: Flags) u16 {
return @bitCast(self);
}
};
/// Setup init configuration flags (view FLAGS)
pub fn setFlags(flags: Flags) void {
SetConfigFlags(@as(c_uint, flags.to_u16()));
}
};
И потом можно переназначить отдельные биты:
raylib.Config.setFlags(.{
.vsync_hint = true,
.window_resizable = true,
});
Такое бы хорошо отдельной статьей. Интересные вещи
На отдельную статью терпения не хватит :-) Там очень много всякого "сахара". Я тут просто обозначил то, что было бы уместно в том же С и не противоречит его идеологии.
Такое, кстати, есть в Zig.
packed struct. Можно указать тип данных под которые он выравнивается
Это не совсем то. Выравнивание это выравнивание. Битовые поля - это бытовые поля.
В RPG все структуры по умолчанию packed - без выравнивания (точнее, с выравниванием на байт). Если нужно выравнивание - нужно добавлять align в описание структуры.
Но позиционирование полей - это не выравнивание. Это именно указание на то, в каком месте структуры расположено данное поле. В С такого нет. Это можно реализовать через указатели на какое-то место внутри структуры с заданным смещением от ее начала, но только в рантайме. А в RPG это делается в compile time просто на уровне описания. И такой подход делает избыточным такую сущность как union - все это реализуется и без этого.
// C
typedef union uINTasBYTES {
unsigned int i;
unsigned char ch[4];
};
// RPG
dcl-ds t_dsINTasBYTES qualified template
i uns(10);
ch uns(3) dim(4) samepos(i);
end-ds;ровно тоже самое, но в RPG в эту же структуру можем еще много чего напихать, а в С придется отдельно описывать union, отдельно структуру куда он входит. А если надо частичное перекрытие двух полей третьим, то жаде сходу не придумаю как это в С реализовать на уровне описаний, только в рантайме через указатели.
Аналогично для массивов с overlay - сходу не придумаю как это просто и лаконично в С описать. Только через вложенные структуры.
dcl-ds dsMyStruct; Field1 char(50); Field2 uns(3) dim(50) samepos(Field1); end-ds;
Отслеживание блоков визуально по вайтспейсам - что ещё может быть корявей , когда оступы в каждой деревне свои ? :-)
Ну, "устраивает" - так устраивает. По мне так эта фанская мишура, конкуренции с Си-ми не выдержит как не выдержали специализированные же языки для системного программирования, к сожалению .
Я не фан Сей, пишу на нём 30+ лет, но есть ряд сугубо инженерных и технологических факторов, не разрешив которе в новоязе - заменить кирзовую Си-шку не удасться. Размножение же сущего (тот же ЯВУ 3Ж, но с кравлениями чего-то стороннего) претит технологическим канонам.
По мне так эта фанская мишура
В этом нет ничего плохого. Из этой фанской мишуры вырастают интересные идеи. Вот хороший пример такой идеи. И она может выстрелить, потому что автор презентации наглядно показал, что такое возможно
Ничего не пишу про плохое или хорошее. Это вообще не имеет смысла без списка критериев. Вы вольны делать что хотите для себя.
Есть принципы технологические, которые определяют выживет то или иное средство или нет. Между опытным образцом и серийным производством - пропасть.
A, B, Си вырос как раз из "фанской мишуры" и победил кокурентов по итогам почти 10+ летнего противостояния, развив технологию применения и сформировав инженерные кадры.
Но, прикиньте если "выстрелит" и мегатонные Си-легаси потащють на нечто новое. Будьте аккуратны в своих мечтаниях. :-)
Когда-то я, наблюдая развитие C++, питал похожие надежды на перспективы D. Ему сегодня уже третий десяток лет идёт. Где он?
Официально Zig младше Rust менее, чем на год. То есть, практически ровесники.
Последний сегодня принят сообществом Linux, принят в Microsoft, принят в Google, можно продолжать.
У первого сегодня нет практически ничего, включая даже собственно языка — он до сих пор не формализован и не стабилизирован. Есть только не такое уж и многочисленное сообщество вокруг.
Положа руку на сердце, не слишком много оснований для веры в большое будущее.
Когда-то я, наблюдая развитие C++, питал похожие надежды на перспективы D. Ему сегодня уже третий десяток лет идёт. Где он?
Этот вопрос вы не у того спрашиваете. Если нужно моё мнение, то идея была странной языком со сборщиком мусора пытаться заменить язык без сборщика мусора. В каких-то нишах это несомненно сможет произойти, но полную замену сделать не возможно.
Официально Zig младше Rust менее, чем на год. То есть, практически ровесники.
2005 и 2015? Один год? Если уж брать ваше допущение у rust на старте была команда и инвестиции, а у zig это произошло совсем недавно. Очень странно сравнивать уже устаявщийся язык и только развивающийся. И при этом тут же писать, что новый язык не стабилизирован. По объектимным причинам он ещё не стабилизирован
Проблему со сборщиком мусора, т.е возможность писать без GC в D решили. Но очень уж поздно и до сих пор режим BetterC на роли падчерицы с минимумом внимания.
Также как и с IDE и еще с многими вещами, которые хотело сообщество.
В итоге сообщество прошло мимо, да и корпорации тоже (но те просто тянут на себя - NIH).
Я сам пробовал D. И понимаю причины, по которым он прошёл мимо. То есть там вообще нет никаких параллелей с Zig. Авторы D сами позиционировали язык D в первую очередь для бизнеса. То есть не для написания бизнес логики, а для внутреннего использования крупных корпоративных структур. И это погубило язык с самого начала. Они пытались решить не проблемы языка, а проблемы бизнеса в первую очередь. А когда уже они стали двигаться в сторону общего назначения, то уже потеряли аудиторию. так как к тому времени C++ разродился новым стандартом
Я такого не помню, да и как то противоречит моей памяти (а был еще и D 1.0). Вроде как позиционировался всегда как более удобный, чем С++, системный язык общего назначения. В принципе, авторы где то книгу истории языка писали, можно поискать. Вот
Как замена С (тут параллели с Zig), режим BetterC появился относительно недавно, в 2017. Когда уже никто его в таком виде не рассматривал.
В любом случае, Zig проще и легче для изучения новичками без C++ бекграунда, как автор этой статьи например.
Я про D 1.0 и имел ввиду. Digital Mars занималась dog-fooding'ом (разрабатывали то, что сами использовали) и разрабатывали они это не для опенсорса, а для бизнеса, потому что сама Digital Mars занималась поддержкой бизнеса, отсюда и логика языка. Сейчас то можно всё что угодно приписывать языку, времени прошло много.
На каждую букву алфавита уже по несколько новых, и конечно же революционных языков понапридумано. Зачем? Подозреваю, что кому-то просто интереснее на своём собственном языке программировать, чем на чужом. Если за языком не стоит большая корпорация — шансов пробиться в массы у него ноль. Не то время сейчас.
Если за языком не стоит большая корпорация — шансов пробиться в массы у него ноль
А даже если и стоит. Достаточно велика вероятность того, что он останется внутри этой корпорации.
Вот RPG, который я постоянно упоминаю. За ним стоит IBM. Достаточно большая корпорация. Существует он с конца 50-х, фактически ровесник COBOL. Но при этом до сих пор развивается. Тот RPG? на котором пишем сейчас и тот, что был в начале - фактически два разных языка.
То, что было когда-то:
D DS1 DS QUALIFIED DIM(2)
D subfld1 10
D subfld2 5
D subfld3 5
C EVAL DS1(1).subfld1 = 'DS1_1'
C EVAL DS1(1).subfld2 = 'DS1_2'
C EVAL DS1(1).subfld3 = 'DS1_3'
C ds1(1) DSPLY
C EVAL DS1(2).subfld1 = 'DS1_4'
C EVAL DS1(2).subfld2 = 'DS1_5'
C EVAL DS1(2).subfld3 = 'DS1_6'
C ds1(2) DSPLY
C SETON LR И то же самое сейчас:
dcl-ds ds1 qualified dim(2);
subfld1 char(10);
subfld2 char(5);
subfld3 char(5);
end-ds;
DS1(1).subfld1 = 'DS1_1';
DS1(1).subfld2 = 'DS1_2';
DS1(1).subfld3 = 'DS1_3';
dsply ds1(1);
DS1(2).subfld1 = 'DS1_4';
DS1(2).subfld2 = 'DS1_5';
DS1(2).subfld3 = 'DS1_6';
dsply ds1(2);
*INLR = *ON; RPG был реализован на платформах Digital VAX, Sperry Univac BC/7, Univac system 80, Siemens BS2000, Burroughs B1700, Hewlett Packard HP3000, ICL 2900 series, Honeywell 6220, WANG VS, IBM PC (DOS).
Компилятор Visual RPG, разработанный сторонним производителем, обеспечивает работу под Windows и поддержку GUI. Существуют также реализации для OpenVMS и других, более экзотических платформ.
Это не считая того, что он поддерживался в VisualAge.
Но на данный момент этот язык значим только в рамках IBM'овских платформ IBM i (middleware, потомок AS/400, которая в свою очередь выросла из System/38) и IBM z (mainframe, потомок System/370).
Там он живее всех живых - более 80% кода на IBM i написано и пишется на RPG. И в каждой новой версии ОС (и новых TR - technical refresh) появляются какие-то новые языковые фички.
Но за пределами этих платформ он практически не известен и широкого распространения не получил.
Второй момент, как мне кажется, ошибочный - все стараются сделать "универсальный язык на все случаи жизни". Этакую серебряную пулю для всех. Что концептуально неверно и ведет к излишнему усложнению языка и, как следствие, росту количества внутренних противоречий в нем.
На мой взгляд более продуктивно было бы для каждого языка поддерживать свою направленность, а универсальности добиваться за счет возможности "стыковки" языков между собой. Та ж IBM реализует это в рамках концепции ILE (Integrated Language Environment), на других платформах нечто подобное реализуется в LLVM. Суть подхода в том, что разработчик может решать разные части одной задачи на разных языках - каждую часть на том языке, который наиболее эффективен для ее решения. А затем объединять несколько модулей в один программный объект.
Примерно так мы и работаем - сложная бизнес-логика пишется на RPG, но если видишь что на С/С++ что-то написать проще и эффективнее (например, какое-то низкоуровневое взаимодействие с системой) - пишем на С/С++. И тот и другой язык имеют свои плюсы и минусы, каждый в своей нише, и прекрасно стыкуются между собой на уровне модулей (некий аналог объектного файла) которые можно биндить (линковать) в один программный объект (программу). Как пример:
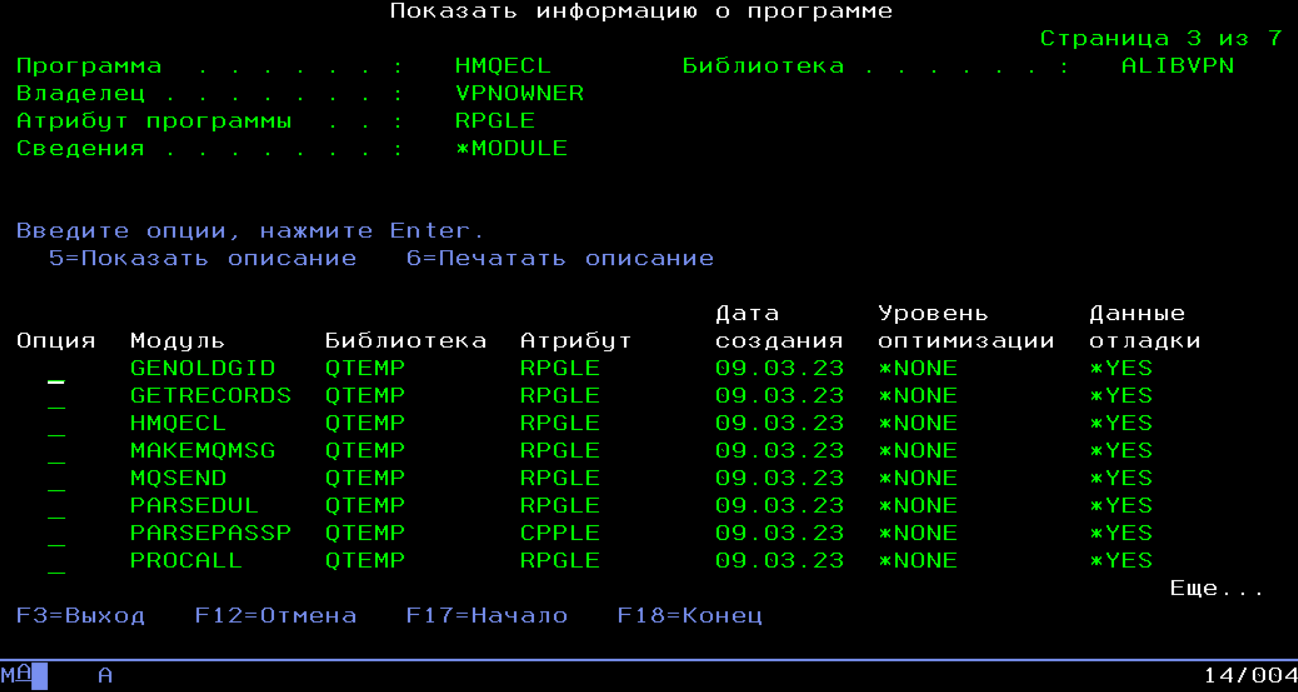
Программа из несколкьких модулей, в основном на RPG. Но вот оказалось что функцию
typedef struct tagPASSPORT {
char Parsed;
char Passport[INPUT_LEN];
char Type[TYPE_LEN];
char Series[SER_LEN];
char Number[NUM_LEN];
char Emitent[OFFICE_LEN];
char EmissionDate[DATE_LEN];
};
typedef tagPASSPORT* PPASSPORT;
extern "C" char ParsePassport(PPASSPORT pPassport)Проще написать на С, объявить ее прототип на RPG
dcl-ds t_Passport qualified template;
Parsed char(1) inz('N');
Passport char(350) inz(*blanks);
*n char(1) inz(x'00');
Type char(15) inz(*blanks);
Series char(10) inz(*blanks);
Number char(50) inz(*blanks);
SerialNumber char(50) inz(*blanks);
Emitent char(300) inz(*blanks);
EmissionDate char(10) inz(*blanks);
end-ds;
dcl-pr ParsePassport ind extproc(*CWIDEN : 'ParsePassport');
Passport likeds(t_Passport);
end-pr;И вызывать из RPG кода, включив в программу модуль PARSEPASSP.CPP
А даже если и стоит. Достаточно велика вероятность того, что он останется внутри этой корпорации… RPGНу тут-то всё логично: «Синтаксис RPG был изначально сходен с командным языком механических табуляторов компании IBM. Был разработан для облегчения перехода инженеров, обслуживавших эти табуляторы, на новую технику и переноса данных». Давно уже нет ни табуляторов этих, ни инженеров, некому больше облегчать процесс перехода. А куча написанного кода — есть, только за счёт этого и держится.
Второй момент, как мне кажется, ошибочный — все стараются сделать «универсальный язык на все случаи жизни». Этакую серебряную пулю для всех.А ошибочный он потому что — есть уже такие языки. Никому не нужен ещё один С++.
А ошибочный он потому что — есть уже такие языки.
Например?
В каком языке есть нативная (на за счет внешних библиотек) поддержка типов с фиксированной точкой, поддержка комплексных чисел, поддержка специальных функций и т.д. и т.п.?
Каждый язык так или иначе имеет свою специфику. Да, есть языки, на которых можно написать все. Но когда берешь другой язык, то вдруг обнаруживаешь что ровно то же самое на нем делается проще, быстрее и эффективнее.
И подобные суждения возникают исключительно в случаях, когда человек запирает себя в рамках одного языка и не хочет расширить свой кругозор.
Каюсь, сам этим грешил достаточно долго. Просто так случилось, что жизнь заставила посмотреть на вещи шире и понять что для каждой задачи всегда есть несколько инструментов и какой-то из них обязательно окажется более эффективным в рамках данной задачи.
Например?C/C++, более универсальных языков я не знаю.
В каком языке есть нативная (на за счет внешних библиотек) поддержка типов с фиксированной точкой, поддержка комплексных чисел, поддержка специальных функций и т.д. и т.п.?Так а почему она должна быть именно нативная? Типов данных сколько угодно может быть, нельзя заранее все их учесть. Про комплексные числа знают многие, а вот про дуальные — уже нет, хотя в вычислениях они ничуть не менее полезны. В С++ можно сделать абстрактную обёртку над ними и оперировать так, как будто они поддерживаются нативно (ну или близко к тому) точно так же, как и с комплексными, на равных. А в вот в Mathematica, в чисто математическом языке казалось бы, такой фокус уже не пройдёт — там всё уже заточено под комплексные числа и все прочие реализуются через костыли.
Или например в С++ я смог построить такую систему типов чтобы можно писать
if(1<x<5) {...}C/C++, более универсальных языков я не знаю.
Он универсален, но в конкретной задаче зачастую будет проигрывать специализированному языку.
Типов данных сколько угодно может быть, нельзя заранее все их учесть.
Все учесть нельзя. Именно поэтому "универсальный язык" обречен на провал.
Вот коммерческая бизнес-логика. Все расчеты ведутся с использованием типов данных с фиксированной точкой. В С/С++ их нет. Значит вам придется потратить время и дописать самому поддержку этих типов + арифметику для работы с ними (всякие там операции без округления, операции с округлением и т.п.).
Дальше вам придется дописывать все, что связано с работой с датами и временем - поддержка различных форматов, арифметику и все вот это вот.
Потом в RPG есть возможность напрямую работать с таблицами БД (и есть случаи когда это реально эффективнее). В С/С++ вам и это придется дописывать.
В RPG есть возможность инкапсуляции SQL в код с использованием хост-переменных. В С/С++ это тоже придется делать руками.
В результате прежде чем написать что-то такое, что на RPG пишется за день-два, в С/С++ вы потратите кучу времени на создание нужного инструментария.
Иными словами - натягивать сову на глобус.
Это как с авто - у любителя в гараже 3-5 ключей. У профессионала в сервисе их в разы больше. Разные типы головок, разные конфигурации ключей. В результате в гараже человек проявляет чудеса ловкости просто ради того чтобы имеющимся ключом подлезть в неудобное место. В сервисе человек просто берет специальный ключ и делает тоже самое в разы быстрее.
Тут ровно тоже самое. Есть типовые задачи бизнес-логики и есть инструмент (RPG), который заточен под их решение. Там где этого инструмента не хватит, я просто возьму другой (С/С++) и решу часть задачи на нем. В результате каждый кусок я реализую теми средствами, которыми это делается максимально быстро и удобно.
При этом я не ищу один универсальный инструмент, я подбираю себе набор инструментов для решения того круга задач, с которыми мне приходится работать.
В С/С++, например, не нравится концепция структур. Она слишком узкая и для описания каких-то сложных структур требует дополнительных сущностей типа юниона или вообще ухода в классы где многое нужно делать в рантайме с тратой процессорных ресурсов.
В RPG концепция структуры иная, там изначально заложена большая гибкость и практически все там делается на уровне описания структуры. В том числе и инициализацию ее полей на уроне шаблона.
И плюсом, если мне не хватает чего-то в RPG я могу из RPG кода вызвать любую функцию из С-шных библиотек просто описав ее прототип на RPG.
Я давно уже вырос из того, чтобы рассуждать о том, какой язык плохой, а какой хороший. Я с 91-го года в разработке и писал много на чем (и фортран и С/С++, всякие фоксы-парадоксы, кларион и даже на прологе немного, сейчас вот еще RPG...) И меня совершенно не ставит в тупик необходимость освоить что-то еще, если того требует задача.
Но вот пришел к тому, что под каждую задачу есть свой наиболее подходящий инструмент. И надо его возможности использовать, а не упираться только в то, что ты знаешь и не заниматься велосипедостроением и хреносозидательством только потому что у тебя какие-то принципиальные тараканы в голове на тему "любимых" и "нелюбимых" языков.
Если, конечно, ты хочешь решать задачи максимально быстро и максимально эффективно.
В С/С++ их нет. Значит вам придется потратить время и дописать самому поддержку этих типов + арифметику для работы с ними (всякие там операции без округления, операции с округлением и т.п.)Почему писать самому? Скачать и даже выбрать ту реализацию, которая вам ближе по стилю. А в C# есть тип decimal их коробки, который как раз для этого — для денежных расчётов.
В том-то и преимущество популярных языков — решения типовых задач давно сделаны.
В С/С++, например, не нравится концепция структурНу а мне не нравится сама концепция программирования через структуры в принципе, неважно на каком языке. Смешивание высокоуровневой и низкоуровневой логики громоздко, плохо читаемо и приводит к трудноулавливаемым ошибкам.
В RPG есть возможность напрямую работать с таблицами БД, возможность инкапсуляции SQL в код с использованием хост-переменных. В С/С++ это тоже придется делать руками.Смешивание кода на уровне СУБД и клиента/сервера тоже не все считают хорошим подходом из-за возможных проблем с безопасностью и целостностью данных. Но в C#, опять же, есть все инструменты для этого — LINQ и иже с ними.
Но вот пришел к тому, что под каждую задачу есть свой наиболее подходящий инструмент. И надо его возможности использовать, а не упираться только в то, что ты знаешь и не заниматься велосипедостроением и хреносозидательством только потому что у тебя какие-то принципиальные тараканы в голове на тему «любимых» и «нелюбимых» языков.Речь же немного о другом шла. Как человек со стороны, я не возьму RPG для бизнес логики. Скорее я возьму 1С (но только если не будет другого выбора). А при возможности лучше напишу свой макро-язык на инструменте, который знаю давно и хорошо.
В том-то и преимущество популярных языков — решения типовых задач давно сделаны.
для нас типовые задачи - работа с БД, как через SQL, так и прямым обращением к таблицам.
И кроме decimal у нас есть еще numeric - это тоже формат с фикс. точкой, но в памяти хранится несколько иначе.
Ну а мне не нравится сама концепция программирования через структуры в принципе, неважно на каком языке.
Что значит "программирование через структуры"?
Вот есть у вас запись в БД - куда вы ее читаете? В буфер? А потом по байтикам разбираете в рантайме, тратя на это процессорное время?
Смешивание кода на уровне СУБД и клиента/сервера тоже не все считают хорошим подходом из-за возможных проблем с безопасностью и целостностью данных.
Ух ты... Эвона оно как оказывается...
А ничего что я работаю на уровне центральных банковских серверов? И пишу ту логику, которая крутится на сервере? И которая должна крутиться очень быстро и при этом потреблять минимум ресурсов...
Речь же немного о другом шла. Как человек со стороны, я не возьму RPG для бизнес логики. Скорее я возьму 1С (но только если не будет другого выбора). А при возможности лучше напишу свой макро-язык на инструменте, который знаю давно и хорошо.
1С оставим за скобками - в наших масштабах это просто несерьезно.
Насчет "не возьму"... 80% кода на этой платформе пишется именно на RPG. Потому что для бизнес-логики он хорош. Быстр и эффективен и в нем есть все, чтобы эту бизнес-логику реализовать. Именно коммерческие расчеты. И вряд ли вы сможете сделать что-то лучше или быстрее.
А речь шла именно о том, что для каждой задачи можно подобрать наиболее эффективный инструмент. А не пытаться забивать все гвозди одним микроскопом, хоть это и возможно.
И не надо бояться использовать одновременно несколько инструментов для решения одной задачи. Когда-то я тоже от этого напрягался. Сейчас - нет. Освоить еще 1-2 новых языка, если есть достаточный опыт разработки не проблема вообще. Более того, новые концепции бывают иногда интересны.
Сложности обычно не в синтаксисе возникают а в общем подходе (помнится, Пролог очень тяжело заходил, но там вообще все не так как привык).
У нас вами бизнес-логика разная.
Про производство я в курсе - значительной часть жизни посвятил разработке системы мониторинга инженерного оборудования зданий, в частности, ЛДСС (лифтовая диспетчерская связь и сигнализация). И там "площадь покрытия" была в масштабах мегаполиса + города-спутники. Т.е. по площади раскиданы контроллеры с которых сигналы стекаются на центральный комп и там обрабатываются (логирование, визуализация все прочее).
Количество устройств... Ну так скажем на не очень большой диспетчерской одних лифтов может быть штук 500. А еще всякая охрана, дымоудаление, видеонаблюдение и бог знает что там клиент пожелает.
Я занимался разработкой "микроядра" - та часть, к которой подключаются и контроллеры и интерфейсные клиенты. И которая занимается первичной обработкой всех сигналов, их маршрутизацией, мониторит состояние контроллеров и все такое.
А потом банк... Тут свои заморочки. Во-первых, совершенно другие подходы. Моя задача - всего лишь одна из десятков тысяч одновременно работающих. И если она начнет потреблять слишком много ресурсов, что-то остальное может начать тормозить. А большинство процессов mission critical - последствия, например, непрохождение платежей. У миллионов клиентов по всей стране. Или невозможность расплатиться картой в магазине (нет ответа от банка) у миллионов клиентов по всей стране. Или еще какая фигня в этом роде.
100млн бизнес операций в день. Полтора терабайта изменений данных в БД (из них 500млн изменений только в рамках закрытия банковского дня). Полтора десятка тысяч таблиц и индексов.
А задачки... Ну разные бывают. Например, построение стоплистов для контроля платежей. Это надо сравнить всю БД клиентов (порядка 50млн сейчас, не считая всяких доверенных лиц, держателей карт и т.п.) со списками Росфина (террористы, экстремисты, торговцы оружием, решения суда, списки ООН...) - там несколько десятков тысяч "субъектов". Ищутся совпадения (адреса, документы, имена, ИНН...) всех со всеми. И это надо делать регулярно - каждый день по тем клиентам у которых были изменения и раз в неделю (в среднем) всех клиентов после загрузки новой версии какого-либо из списков. И делать это надо достаточно быстро (ну хотя бы в 3-4 часа уложиться по полной сверке).
Короче, тут полный hiload и очень жесткие требования как по скорости, так и по использованию ресурсов процессора. Поэтому и выбираются те инструменты, которые позволяют получить максимальный результат при минимальных затратах.
И да. У нас есть отдельные задачи по различным "низкоуровневым сервисам" (этакие "микрофреймворки" под наши нужды). И там действительно много и С и С++ т.к. много системных вещей.
А вот с бизнес-логикой... У нас есть команда, которая пытается сделать большой фреймворк на С++. Но они пилят его уже больше 5-ти лет и широкого распостранения в банке он до сих пор не получил. Т.е. вроде бы как и пользоваться можно, но ни по скорости разработки, ни по простоте поддержки, ни по эффективности никаких преимуществ по сравнению с RPG там нет. В лучшем случае не хуже (хотя местами и проигрывает по ресурсам).
Ну и нас обязательно поставки проходят нагрузочное тестирование на копии промсреды. С использованием очень мощного инструмента Performace EXplorer (PEX). И там в статистике сразу видно кто сколько ресурсов процессора использует, сколько времени выполняется та или иная функция и все вот это вот.
Вот есть у вас запись в БД — куда вы ее читаете? В буфер? А потом по байтикам разбираете в рантайме, тратя на это процессорное время?Всё, что можно спихнуть на клиента, я спихиваю на клиента. У нас далеко не хайлоад и машина клиента может быть даже мощнее сервера. Конечно, не в ущерб безопасности, такие вещи как сортировка или объединение таблиц.
Но вся логика работы с СУБД сделана через хранимые процедуры, клиент не может напрямую выполнять select-ы, insert-ы, update-ы и delete-ы.
Всё, что можно спихнуть на клиента, я спихиваю на клиента.
Увы, не наш случай. У нас процентов 90 логики крутится на самом сервере.
Как пример. Есть платежи. За день их огромное количество проходит. И каждый проходит через контроль финмониторинга. Естественно, что руками контролировать все нереально в таких объемах. Поэтому есть комплекс автоматических проверок. Их там порядка десятка, каждая со своими настройками в зависимости от типа платежа (входящий, исходящий, внутренний) и типа клиента (физик, юрик, ИПшник).
Этот комплекс проверок запускается автоматом по факту формирования платежного документа. В зависимости от типа платежа и клиента выстраивается очередность вызова проверок (фактически она кешируется при первом запуске в виде набора цепочек функций проверок, дальше уже просто выбирается нужная цепочка - все это регулируется настройками - какие проверки, в каком порядке). Проверки вызываются по цепочке, каждая проверка возвращает код результата. Как только какая-то проверка вернула отрицательный код, цепочка прерывается. По выходе из цепочки имеем код завершения по которому принимается решение - пропустить, отправить на авторизацию, отправить на ручной контроль. Если решение отличное от пропустиь, платежный документ отправляется в очередь во внешнюю систему с указанием статуса (авторизация/ручной контроль) и кода (что именно не понравилось, на что обратить внимание).
Логика там достаточно замороченная, на скуле ее не реализовать - очень долго получится. Поэтому RPG.
Второй пример. Рассылка уведомлений. Запускается каждый день в начале операционного дня (в фазе, следующе непосредственно после закрытия предыдущего и открытия нового дня). Там тоже десяток разных процедур которые анализируют различные параметры клиентов (например, истек или скоро истекает срок действия паспорта). Там тоже - скулевая выборка, затем обработка и по результатам опять отправка в очередь во внешнюю систему уведомлений (рассылать клиентам уже будет внешняя система, мы только готовим рассылку).
Ежегодная актуализация клиентов. Раз в год. Тоже выборка по ряду критериев тех, кто в этом году подлежит актуализации (по прошлому году порядка 22млн). Дальше - проверка клиентских данных (документы, адреса) + проверка данных "держателей карт" (если клиент на кого-то допкарту к счету оформляет). Если все ок - обновляется дата актуализации. По результату - отчет со списком кто не прошел и почему (что не так). Тут данных много - это делается в параллель в 10 потоков (точнее, 10 заданий - job). Головное задание запускает 10 заданий-обработчиков делает отбор кого проверять, формирует пакеты по 100 ПИНов и выкладжывает их на конвейер. Обработчика подхватывают пакеты с конвейера и обрабатывают. На головном же задании еще контроль за состоянием заданий-обработчиков (что все стартовали, никто не упал в процессе работы, по окончании работы все корректно завершились и т.п.). Тут тоже одним скулем не разрулить все...
Вообще, скуль недостаточно быстр для наших задач. Мы даже стараемся поменьше использовать агрегатные функции и группировки - быстрее сделать более линейный скуль с избыточной выборкой и дальше все агрегирование делать уже в режиме потоковой обработки с формированием итоговой выборки в памяти.
И таких задач у нас десятки тысяч.
Ещё пара комментариев в том же объёме — и можно тоже идти устраиваться в банк)
А у нас с этим просто - "готовых" разработчиков под IBM i на всю РФ сотни три наберется если не меньше. Так что берем всех, кто умеет разрабатывать (кто не умеет тоже берем, но стажерами - полгода на полдня).
Первые три месяца - обучение (формально называется "испытательный срок", но полная оплата, разве что ДМС/НС не оформляется, но в отпуск и квартальные бонусы зачет идет сразу). За эти три месяца (обычно полтора-два, дальше уже несложные реальные задачки начинаются) человек осваивает азы и становится способен что-то делать сам.
Другое дело, что не всем подходит. Во-первых, "нерелевантный опыт" - специфический язык, специфическая платформа. Во-вторых, легаси и кровавый энтерпрайз. Все очень консервативно, высокие требования к коду, куча "нефункциональных требований". Никаких тебе модных фреймворков, все руками. Еще и на ревью придираться начнут - тут неэффективно, здесь не по нашим стандартам....
Хотя, как ни странно, текучки почти нет. Кто приходит, залипает надолго. Может потому что сам платформа интересная - чем глубже в нее погружаешься, тем больше открываешь для себя нового.
И вот еще, кстати, часть приходится читать одну или несколько записией из одной таблицы по известному значению ключа. Наши статистики показывают что в таких случаях эффективнее использовать не скуль (он хорош для объемных выборок по нескольким таблицам), но прямое чтение из БД. Это можно делать и в С - есть библиотека recio, но в RPG это делается проще (короче) по коду.
Кроме того, в RPG есть вот такой способ описания структур
dcl-ds t_dsGZSURecord extname('GZECSU1': *all) template qualified end-ds;Который сразу создает структуру соответствующую формату записи нужной таблицы.
Или так
dcl-ds t_dsYAR likerec(YAR12LF.YARPFR: *all) template;Два способа, там есть тонкости для того и другого - в одном случае один удобнее, в другом - другой.
В С/С++ такого нет в принципе. Максимум что есть - внешняя утилита, которой можно сгенерировать хидер с описанием структур, соответствующих форматам записей. Но это не так удобно...
Вот из таких мелочей и складывается удобство специализированных инструментов.
К примеру - пила. Чего проще... Но есть цепная - ей дрова удобно пилить, дерево валить. Есть сабельная - всякие сучья небольшие. Есть циркулярка - длинный прямой рез, особенно для листовых материалов типа фанеры. Есть лобзик - это для фигурных всяких вещей. Лобзиком можно попробовать и длинный прямой рез, но все равно будет криво и медленно по сравнению с циркуляркой. Сабельной можно дрова, если не толстые, но медленнее чем цепной. Можно сучья циркуляркой, но дико неудобно...
И так везде и во всем...
Не увидел ответа на главную главную проблему C: UB.
Без решения этой проблемы он не нужен и не менее вреден, чем C, с ним вполне кандидат на роль "убийцы"
Очень странно, что ни слова нет про NIM (язык "счастья") в контексте такой статьи. Можно сделать вывод, что автор его упустил из виду. :)
Автор, всё хорошо , но какая энумерация? Если уж вы пишите русские наименования сиречь, переводы, то есть же прекрасное и понятное "перечисление". Режет глаз, честно говоря. Тут надо или по русски, или по английски. Это не только к вам конечно, но вообще, очень напрягает последнее время всякое типа: активности, энумерации, корутины и прочее. Причем, и единого то стандарта нет, а каждый автор своё придумывает, и в итоге чтение статьи превращается в головную боль иногда.
Zig для меня — это новый C