'Attention' is not a neural network, but a method of building one. It is used to show neural networks an important part of an input image or text.
Important: this approach to neural networking is relatively recent, so it does not yet have an established name in Russian language. For example, the term self-attention is often translated as self-attention, although the meaning is more about auto-attention. Therefore, the terms are given in the text without translation.
Problem with long sequences
A recurrent encoder-decoder neural network is an architecture with two sets. The first set of LSTMs is trained to encode input sequences into a fixed-length internal representation. The second set of LSTM reads the internal representation and decodes it into an output sequence.
This architecture has shown excellent results in complex seq2seq tasks, such as text translation, and has quickly become the dominant approach. A potential problem with using the encoder-decoder architecture is that the neural network must compress all the necessary information of the original sentence into a fixed length vector. This is thought to limit the effectiveness of these networks in text translation tasks where very long sentences are encountered.
Translated with DeepL.com (free version)
Problem with large images
Converged neural networks used to solve computer vision problems also suffer from similar limitations, where it can be difficult to train models to work on very large images. To avoid this, it is possible to emphasize (highlight) some parts of a large image.
To explain: one important property of human perception is that humans do not tend to process the whole scene at once. Instead, people selectively focus on parts of the visual space to get information about its important parts, and combine information from different parts to create a complete picture and make a decision about the scene as a whole.
In the same way, it is easier for a neural network to focus (pay attention) to the primary parts of an image.
5 examples of using networks with "attention"
1. Attention for text translation
A neural network takes as input a phrase in a language, such as French, and outputs an English phrase. Attention associates certain words in the input sequence with words in the output sequence, which improves the quality of the translation.
2. Attention to describe images
The mechanism of sequence-based attention can be applied to computer vision tasks. It helps to understand how best to use a convolutional neural network, where to pay attention in an image for better formation of the output sequence - a verbal description of the image.
An image is fed to the input of the neural network, and the output is a verbal description in English or any other language. Attention is needed to correlate fragments of the image and words in the output phrase. Below are examples of correct correlation of a part of an image and a word:

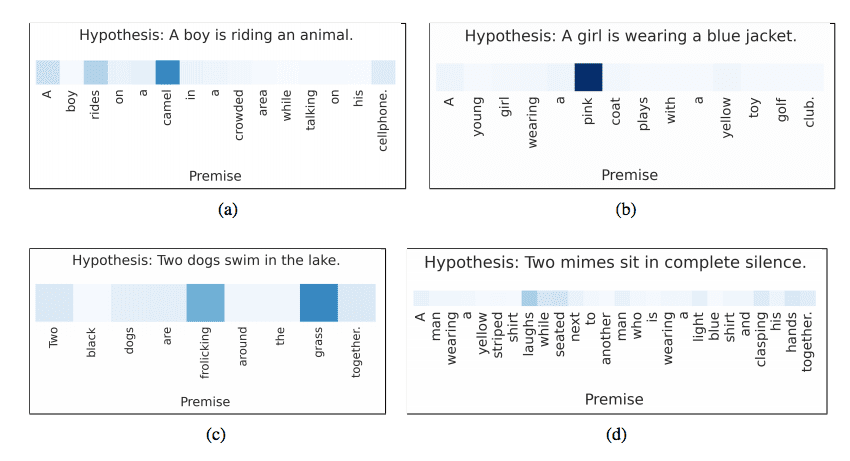
3. Attention to get conclusions
Two statements are made: a premise and a hypothesis. Attention links each word in the hypothesis to the words in the premise and vice versa. For example:
The premise is "photographing a wedding party"
Hypothesis: "someone got married".
Next, a conclusion is drawn on the correspondence between premise and hypothesis.
In figure (a) the premise is "a boy rides a camel a crowded place while talking on the phone". The hypothesis is "the boy rides the animal". The network indicated good matches in the words "riding" and "camel".
4. Attention for speech recognition
Given an input sequence of English speech fragments, the network outputs a sequence of phonemes. Attention correlates each phoneme in the output sequence with specific sound frames in the input sequence.

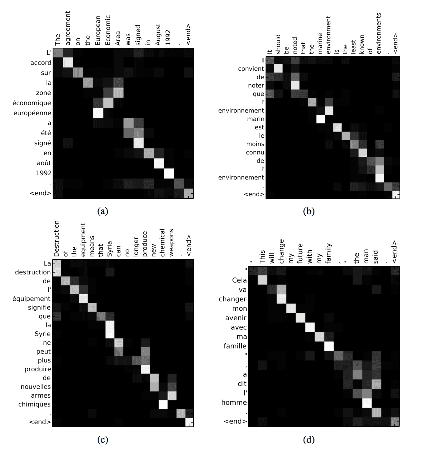
5. Attention to summarize the text
Given an input sequence of an article in English or any other language, the neural network outputs a sequence of English words that summarize the input data. Attention relates each word in the summary to specific words in the input document.
The figure shows the attention matrix. It shows how the neural network summarized the phrase, highlighted the important words (called, for, joint, combating, terrorism) and composed the summary from them:

Until now, the main approach to sequence processing was to use an encoder-decoder type structure (sequence2sequence architecture). The encoder received and processed the input sequence and output its vector representation - h and c parameters. The decoder, having received the encoder's data, produced a response.

The bottleneck of this structure is the need to compress the input information into vectors (h and c) of fixed length. The decoder receives only the final states of the encoder. As the length of the input message increases, the quality of work is lost: the encoder starts to forget the beginning of the sequence.
A rather obvious solution of this problem is to give all intermediate states of the encoder to the decoder. Let's add an attention block to our scheme:
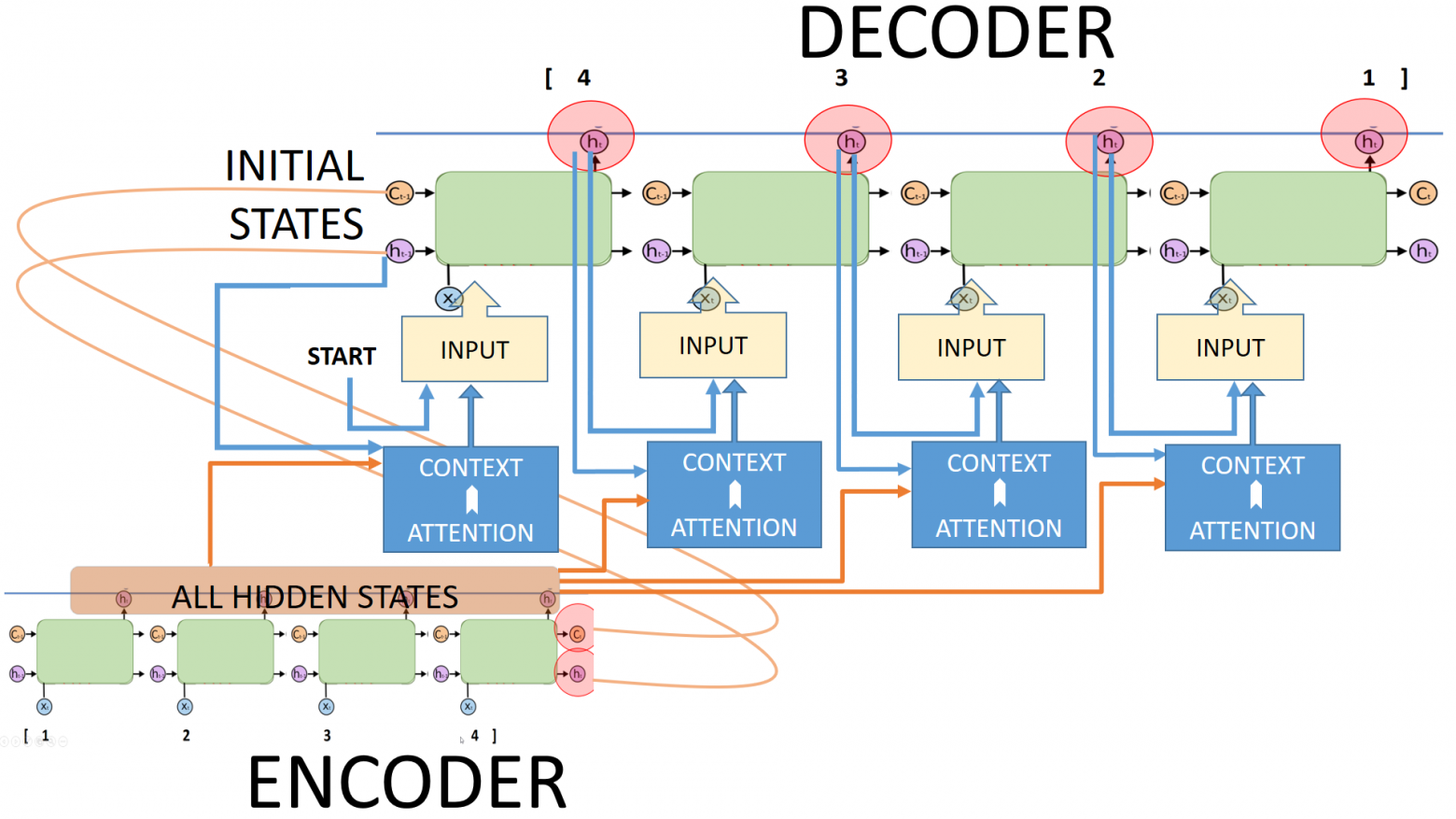
The sequence2sequence network with attention is shown in the figure above. How this scheme works:
First, we initialize the decoder states using the latest encoder states as usual.
Then at each decoding time step:
we use all the hidden encoder states and the output of the previous decoder to compute the context vector by applying the attention mechanism.
Concatenate the context vector with the output of the previous decoder to feed this to the input of the decoder.
Program implementation of the attention block:
The hidden state vector and the encoder output are fed to the dense layers.
The sum of their outputs passes through the
tanh()layer.Next is softmax. Here we get the attention vector - vector of weights
We weight the encoder output with the vector of weights - we get the context vector context vector.
Send it to the decoder input.

Let's consider the work of the attention block on an example
Let the phrase "I like this sunset" come to the neuron's input. We need to translate it into English: i like this sunset. Step by step it looks as follows:
The phrase arrives at the encoder, it produces the hidden states
h1,h2,h3,h4(values = encoder_all_states).We feed the final encoder state vector to the decoder.
feed the word
< start >to the decoder.The decoder (LSTM) receives the hidden state corresponding to the first word (
query) on the outputs.The attention block produces softmax numbers from 0 to 1 (1 in total) at the output of the softmax layer - these are attention weights. They indicate how much and which element from the coder's hidden state vector should be given attention. In our case it is
h2. The vector of weights for the example is (0.05, 0.85, 0.05, 0.05). The weights are shown near the corresponding hidden state outputs of the encoder.Multiply the vector of weights by the hidden state vector (
h1,h2,h3,h4), withh2highlighted.We give the result of the multiplication to the decoder to form the first word.
Then we repeat until the end of the phrase.

It is appropriate to tell about two great neural engineers Minh-Thang Luong and Dzmitry Bahdanau. They created two types of attention in seq2seq networks.

The basic idea is the same - to weigh and give all encoder states to the decoder. Differences are clear in the figure above. In Luonga the encoder vector is also involved in forming the decoder output. Both variants are used in practice.
Do not think that there are only two variants of the attention module created in the world. Almost every author of neuronkey has contributed his own touches to the implementation. And you should be familiar with all of them.
