Comments 125
LXC — это уже имя собственное. На сколько мне известно Google использует свою реализацию контейнеров.
«видоизмененный аналог chroot» — это mount namespace для LXC и по историческим причинам своя реализация для OpenVZ. Для изоляции сети, IPC, UTS так же используются соответствующие пространства имен.
Из свободных реализаций так же можно упомянуть unshare, nsenter из util-linux, systemd-nspawn.
Ну, и не плохо было бы описать недостатки контейнеров.
«видоизмененный аналог chroot» — это mount namespace для LXC и по историческим причинам своя реализация для OpenVZ. Для изоляции сети, IPC, UTS так же используются соответствующие пространства имен.
Из свободных реализаций так же можно упомянуть unshare, nsenter из util-linux, systemd-nspawn.
Ну, и не плохо было бы описать недостатки контейнеров.
Будущее облаков — это когда пофигу на чём работают инстансы. И на сами инстансы пофигу, важно только чтобы вовремя спанились.
Во многом благодаря таким проектам как CoreOS, OSv мы движемся к этому. Но еще очень-очень многое стоит сделать, пока это станет явью. Самые большие проблемы со стороны дистрибутивов и дистрибуции (имеются в виду образы для установки) в целом.
Мы уже буквально 4 года мигрируем виртуальные окружения между Xen, KVM, OpenVZ и bare metal во всех мыслимых направлениях, но делается это все вручную, часто через даунтайм (малый, но все же) и не сказать, что особо надежно, каждый раз что-то приходится модицифироваться из-за той или иной фичи системы изоляции.
Мы уже буквально 4 года мигрируем виртуальные окружения между Xen, KVM, OpenVZ и bare metal во всех мыслимых направлениях, но делается это все вручную, часто через даунтайм (малый, но все же) и не сказать, что особо надежно, каждый раз что-то приходится модицифироваться из-за той или иной фичи системы изоляции.
У NetApp есть своя разработка:
communities.netapp.com/community/netapp-blogs/msenviro/blog/2013/08/02/mat-powered-by-project-shift
communities.netapp.com/community/netapp-blogs/msenviro/blog/2013/08/02/mat-powered-by-project-shift
Xen в ядре Linux 3.* поддерживается в качестве Dom0: wiki.xen.org/wiki/Dom0_Kernels_for_Xen для подтверждения. Или имелось что-то другое?
Спасибо за вопрос, постараюсь расшифровать, что имелось в виду.
Dom0 — это тоже клиентская VM по своей сути, только для управления виртуализацией.
Что Dom0, что DomU все равно работают поверх гипервизора Xen, который к Linux отношение имеет весьма отдаленное и не поддерживается в контексте kernel.org. Отсюда и не совместимость с железом, на котором отлично работает чистый Linux.
Про это очень хорошо написано вот в этой публикации: chucknology.com/2012/02/02/kvm-is-linux-xen-is-not/
Dom0 — это тоже клиентская VM по своей сути, только для управления виртуализацией.
Что Dom0, что DomU все равно работают поверх гипервизора Xen, который к Linux отношение имеет весьма отдаленное и не поддерживается в контексте kernel.org. Отсюда и не совместимость с железом, на котором отлично работает чистый Linux.
Про это очень хорошо написано вот в этой публикации: chucknology.com/2012/02/02/kvm-is-linux-xen-is-not/
Спасибо, почитаю.
Прочёл. Это описание очень старое и связно лишь с 3.0. Если я правильно понял, там написано, в картинке xen после 3.0 и три части: DomU, Dom0 и гипервизор? Я всегда думал, что гипервизор в Dom0. Ещё там было сообщение о pv-ops. Кажется, это вновь переписанная часть Xen, чтобы иметь возможность добавить в майнстрим. Если мне не изменяет память, OpenSuse до сих пор форвардпортирует xenlinux из 2.6.18, в обход pv-ops.
Не, в том и дело, что гипервизор сам по себе. Вот посмотрите актуальные слайды от разработчиков Xen: www.xenproject.org/developers/teams/hypervisor.html на 12 странице:

Я честно говоря не особый спец по Xen, но все было примерно так:
1) Изначально DomU (клиентские виртуалки) требовали модицифированного Linux ядра. Это было исправлено путем патчей в ядро, они вошли в основное ядро и модификация более не потребовалась
2) Изначально Dom0 также требовал модифицированного/патченного Linux ядра. Это требовалось даже когда DomU уже не требовали модификации
3) Теперь ни для Dom0, ни для DomU никаких телодвижений не требуется (в слуае новых ядер), но все равно это дело крутится поверх гипервизора, имеющего совершенно отличню от Linux архитектуру.
А вот по поводу паравиртулизации вряд ли что скажу, не работал.

Я честно говоря не особый спец по Xen, но все было примерно так:
1) Изначально DomU (клиентские виртуалки) требовали модицифированного Linux ядра. Это было исправлено путем патчей в ядро, они вошли в основное ядро и модификация более не потребовалась
2) Изначально Dom0 также требовал модифицированного/патченного Linux ядра. Это требовалось даже когда DomU уже не требовали модификации
3) Теперь ни для Dom0, ни для DomU никаких телодвижений не требуется (в слуае новых ядер), но все равно это дело крутится поверх гипервизора, имеющего совершенно отличню от Linux архитектуру.
А вот по поводу паравиртулизации вряд ли что скажу, не работал.
Немного добавлю:
Все верно, XEN работает уровнем ниже чем ядро операционной системы (т.е. является гипервизором первого типа), причем XEN появился раньше чем в x86 появилcя VT-x (кстати по этому поводу в таблице не совсем правильно написано). Данный режим работы был назван паравиртуализацией. Если коротко, ядро переносится в RING1(если x86) или RING3(если x86-64, как раз тот редкий случай когда еще один уровень привилегий был полезным), все привилегированные инструкции в ядре заменяются на гипервызовы, меняется код начальной загрузки, устанавливается механизм обмена сообщений между гипервизором и ядром. Вместо эмуляции устройств, XEN использовал собственный backend — frontend механизм. Такую модификацию необходимо произвести как в Dom0 так и в DomU. Грубо говоря, xen с точки зрения ядра является еще одной архитектурой. Такой подход позволил получить неплохую производительность виртуальных машин даже без VT-x, но естественно данный подход применим только для операционных систем с открытым исходным кодом.
С появлением VT-x и аналогов у AMD в XEN появился режим аппаратной виртуализации HVM, который уже не требовал модификации гостевых ОС для работы. Однако поскольку эмуляция устройств является достаточно дорогой, то пришла необходимость в использовании паравиртуальных драйверов, для минимизации расходов на эмуляцию оборудования.
Однако, на сегодняшний день, Dom0 должен быть паравиртуализован полностью (отсюда вылезают неприяные моменты на x86-64, вроде невозможности эффективно выполнять системные вызовы через syscall). Однако в сообществе XEN есть идеи как сделать dom0 аппаратно виртуализованным )))
Все верно, XEN работает уровнем ниже чем ядро операционной системы (т.е. является гипервизором первого типа), причем XEN появился раньше чем в x86 появилcя VT-x (кстати по этому поводу в таблице не совсем правильно написано). Данный режим работы был назван паравиртуализацией. Если коротко, ядро переносится в RING1(если x86) или RING3(если x86-64, как раз тот редкий случай когда еще один уровень привилегий был полезным), все привилегированные инструкции в ядре заменяются на гипервызовы, меняется код начальной загрузки, устанавливается механизм обмена сообщений между гипервизором и ядром. Вместо эмуляции устройств, XEN использовал собственный backend — frontend механизм. Такую модификацию необходимо произвести как в Dom0 так и в DomU. Грубо говоря, xen с точки зрения ядра является еще одной архитектурой. Такой подход позволил получить неплохую производительность виртуальных машин даже без VT-x, но естественно данный подход применим только для операционных систем с открытым исходным кодом.
С появлением VT-x и аналогов у AMD в XEN появился режим аппаратной виртуализации HVM, который уже не требовал модификации гостевых ОС для работы. Однако поскольку эмуляция устройств является достаточно дорогой, то пришла необходимость в использовании паравиртуальных драйверов, для минимизации расходов на эмуляцию оборудования.
Однако, на сегодняшний день, Dom0 должен быть паравиртуализован полностью (отсюда вылезают неприяные моменты на x86-64, вроде невозможности эффективно выполнять системные вызовы через syscall). Однако в сообществе XEN есть идеи как сделать dom0 аппаратно виртуализованным )))
Алоха, коллега.
Первая же схема, которую вы привели, напомнила о том, как мы саппорту на пальцах объясняли как работает контейнер относительно ВМки. Не поленился, вытащил из откопанного дока картинку:
Что же касается вопроса «за чем будущее» — не соглашусь что сугубо за контейнерами. Не смотря на на плюсы в виде производительности, сквозного управления с хост-машины и возможности ставить пакеты глобально с хоста же — контейнеры в силу технологии плохо дружат с другими типами осей. Если всю инсталляцию надо иметь под чем-нибудь одним (к примеру, кластер debian-серверов) — тогда, конечно, да. Если же задачи потребуют иметь группу машин на FreeBSD, да еще и, скажем, рабочие станции сотрудникам на виртуалках организовать — не избежать винегрета из гипервизоров (что вместе с винегретом из ОСей вызывает желание пойти и напиться). Либо, как в нашем с вами случае — можно ограничиться продажей только vps под linux, но тогда те же форексоизвращенцы пройдут к конкурентам.
Потому я убежден — будущее за продуктами, сочетающими в себе разные типы виртуализации единовременно. Яркий пример — как раз PCS6, который на приведенных графиках отмечен. Тут вам и контейнеры и ВМки под любой ОСью и все в рамках однотипных хост-машин с одним и тем же продуктом. По-моему, прекрасно :)
Первая же схема, которую вы привели, напомнила о том, как мы саппорту на пальцах объясняли как работает контейнер относительно ВМки. Не поленился, вытащил из откопанного дока картинку:
Что же касается вопроса «за чем будущее» — не соглашусь что сугубо за контейнерами. Не смотря на на плюсы в виде производительности, сквозного управления с хост-машины и возможности ставить пакеты глобально с хоста же — контейнеры в силу технологии плохо дружат с другими типами осей. Если всю инсталляцию надо иметь под чем-нибудь одним (к примеру, кластер debian-серверов) — тогда, конечно, да. Если же задачи потребуют иметь группу машин на FreeBSD, да еще и, скажем, рабочие станции сотрудникам на виртуалках организовать — не избежать винегрета из гипервизоров (что вместе с винегретом из ОСей вызывает желание пойти и напиться). Либо, как в нашем с вами случае — можно ограничиться продажей только vps под linux, но тогда те же форексоизвращенцы пройдут к конкурентам.
Потому я убежден — будущее за продуктами, сочетающими в себе разные типы виртуализации единовременно. Яркий пример — как раз PCS6, который на приведенных графиках отмечен. Тут вам и контейнеры и ВМки под любой ОСью и все в рамках однотипных хост-машин с одним и тем же продуктом. По-моему, прекрасно :)
А картинка не прикрепилась :(
Да, PCS6 интересная в плане подхода штука, но мы от него используем только контейнеры, надобности в VM особенной не возникало, честно говоря, даже тесты провести руки не доходят. Аналогичный подход предоставляет Proxmox.
Но проблема подобных решений, что все сделано сильно «по-разному». Здесь я имею в виду унификацию управления VM и контейнерами в одном инструменте. В свое время даже RedHat пыталась (вроде бы уже перестали) в libvirt совместить управление KVM, Xen с управлением OpenVZ, LXC, получалось это весьма отвратно. Контейнеризация даже на объектную модель (виртуальные сетевые, жесткие диски, виртуальные процессоры) полной виртуализации ложится крайне плохо и поэтому очень сложно скрещивать ужа с ежом. В Proxmox как раз так получается :(
Если у кого и получится — это будет прорыв :)
Да, PCS6 интересная в плане подхода штука, но мы от него используем только контейнеры, надобности в VM особенной не возникало, честно говоря, даже тесты провести руки не доходят. Аналогичный подход предоставляет Proxmox.
Но проблема подобных решений, что все сделано сильно «по-разному». Здесь я имею в виду унификацию управления VM и контейнерами в одном инструменте. В свое время даже RedHat пыталась (вроде бы уже перестали) в libvirt совместить управление KVM, Xen с управлением OpenVZ, LXC, получалось это весьма отвратно. Контейнеризация даже на объектную модель (виртуальные сетевые, жесткие диски, виртуальные процессоры) полной виртуализации ложится крайне плохо и поэтому очень сложно скрещивать ужа с ежом. В Proxmox как раз так получается :(
Если у кого и получится — это будет прорыв :)
Это ж насколько нужно… быть чтоб откинуть бесплатный VMware ESXI, Hyper-V, Virtualbox только потому-что они видите ли не открыли исходники. У меня тупой вопрос. А вы часто в эти исходники лезли? Может закладку от АНБ нашли? Весь код просмотрели? Давайте так же начхаем на Solaris Containers. Чото тоже не айсс. Вам дают лучшие!!! продукты даром!!! а вы лезете копаться в том за что все равно однажды придется платить. Можете минусовать, но все это напоминает историю с геями. Те тоже первоначально хотели равных прав. Им дали(эти коммерческие продукты сделали бесплатными). Потом они посмотрели что блин всем на них начхать и им захотелось особых прав(исходники). Только им тонко объяснили что они не правы. Тут так же. нужно то барзометр притормаживать. Если начали писать про бесплатное… так будь любезен не вставлять заепшие примечания типо «Хотелось бы отметить, что Oracle VirtualBox был не включен в таблицу осознанно, так как не является полностью открытым». А делайте полностью взрослый обзор.
Не люблю геев.
Вы ишите заговор там, где его нету — мы изначально сузили круг исследуемых технологий open source решения и только ими. VirtualBox отчасти является открытым решением, но часть их наработок требует установки бинарной версии, поэтому он и был исключен. Рассмотрение ESXi, Hyper-V и Solaris Zones, а также IBM System z не входило в изначальные планы :)
Но, в ряде указанных мной источников, кто проводил тесты, есть много упоминаний ESXi, например и Hyper-V. Пройдитесь по ссылкам на PDF'ки, если интересно.
Но я не обладаю компетенцией для написания обобщенного поста «сравнение всех-всех-всех» систем виртуализации :)
Но, в ряде указанных мной источников, кто проводил тесты, есть много упоминаний ESXi, например и Hyper-V. Пройдитесь по ссылкам на PDF'ки, если интересно.
Но я не обладаю компетенцией для написания обобщенного поста «сравнение всех-всех-всех» систем виртуализации :)
Но вообще — например, бесплатный ESXi (к слову, бесплатен он лишь до 32 гб озу, что сейчас весьма мало) откровенно проигрывает во многих тестах технологиям Xen и KVM.
Так что если Вы обобщаете вопрос «Разве не за проприетарной виртуализации будущее?». Я могу ответить — нет, не за ней. Будущее — за открытыми, свободными и при этом качественными open source разработками.
Так что если Вы обобщаете вопрос «Разве не за проприетарной виртуализации будущее?». Я могу ответить — нет, не за ней. Будущее — за открытыми, свободными и при этом качественными open source разработками.
У вас старая информация — VmWare ESXi не имеет больше ограничений на 32GB оперативной памяти.
Ого, круто! Спасибо за информацию! Помню как сначала объявили vRam до 8Gb, потом увеличили до 32Gb, а вот полное снятие ограничений, видимо, я пропустил.
Но это кажется не решает проблемы «бесплатно и коммерческое» использование.
Hyper-V тоже есть в бесплатном варианте.
Hyper-V тоже есть в бесплатном варианте.
А есть какая-то проблема при коммерческом использовании ESXi?
Визуально пробежался по их условиям лицензирования и вроде никаких подводных камней нету.
Но есть проблемы в том плане, что многие фичи, без которых жить почти нереально (бэкапы там, управление шаблонами и прочее) там недоступны, вот тут забейте www.virtualizationmatrix.com/ сравнение между ESXi hypervisor free и standard. К сожалению, прямую ссылку дать не могу, не нашел есть ли там вообще такая возможность.
Но есть проблемы в том плане, что многие фичи, без которых жить почти нереально (бэкапы там, управление шаблонами и прочее) там недоступны, вот тут забейте www.virtualizationmatrix.com/ сравнение между ESXi hypervisor free и standard. К сожалению, прямую ссылку дать не могу, не нашел есть ли там вообще такая возможность.
Управление шаблонами из гипервизора и т.п. фишки гипервизора не нужны очень многим пользователям, т.к. у них обычно 1 или 2 сервера под виртуализацию. От гипервизора требуется только качественное выполнение его базовых функций. Все остальные вещи, типа бекапов, должны делать специализированные решения. Например бекапы прекрасно делаются средствами, типа veeam free edition (бекапит контейнеры машин) или bacula (бекапится содержимое машинок). А все фишки, которые есть в платных версиях, всё равно не доступны на бесплатных аналогах, которые представлены в данном обзоре.
Честно говоря затрудняюсь ответить на вопрос предметно, но веб-интерфейса для управления виртуализацией и правда, пожалуй, никто из рассматриваемых игроков не предоставляет.
Я уверен, на Хабре будет очень полезен пост-обзор всех средств виртуализации, а не только открытых, которыми ограничился я.
Кто возьмется?
Я уверен, на Хабре будет очень полезен пост-обзор всех средств виртуализации, а не только открытых, которыми ограничился я.
Кто возьмется?
web интерфейс можно к virtualbox прикрутить sourceforge.net/projects/phpvirtualbox/ но это всё игрушки )
Можно ссылки на тесты?
Просто я не могу поверить, что ставший почти стандартом инструмент для виртуализации ( исключая хостеров ) может «откровенно» проигрывать открытым технологиям.
Просто я не могу поверить, что ставший почти стандартом инструмент для виртуализации ( исключая хостеров ) может «откровенно» проигрывать открытым технологиям.
Вот, пожалуйста: rhsummit.files.wordpress.com/2013/06/sarathy_t_1040_kvm_hypervisor_roadmap_and_overview.pdf
Графики оттуда:
И еще вот очень наглядный с процентами график оттуда же: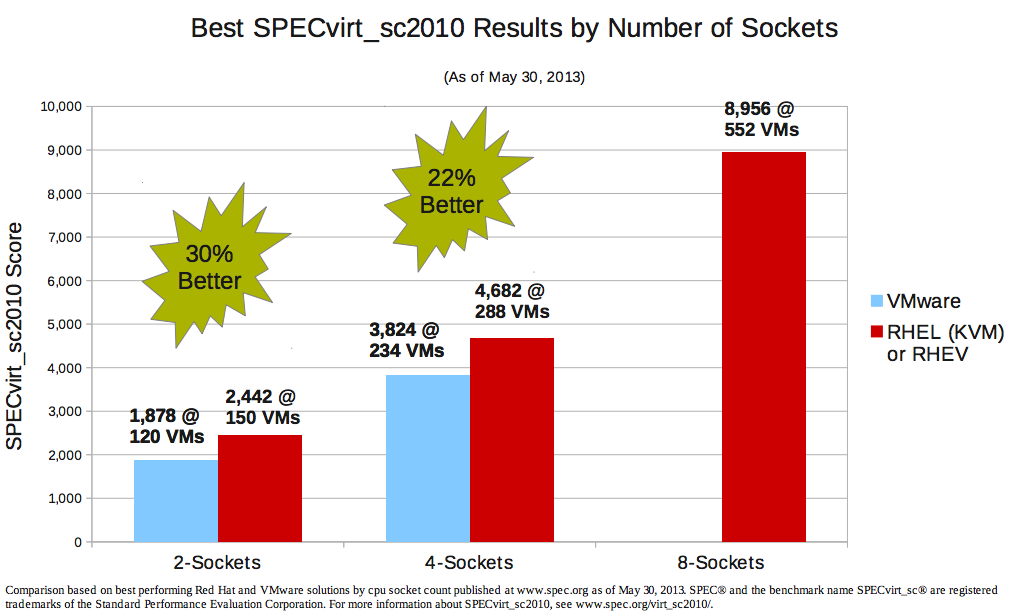
Вот исследование от Parallels, там про их платформу, но есть и графики про KVM vs ESXi:
www.parallels.com/fileadmin/parallels/documents/hosting-cloud-enablement/pvc/whitepapers/Performance_Comparison_White_Paper.pdf
Вот, пожалуйста:
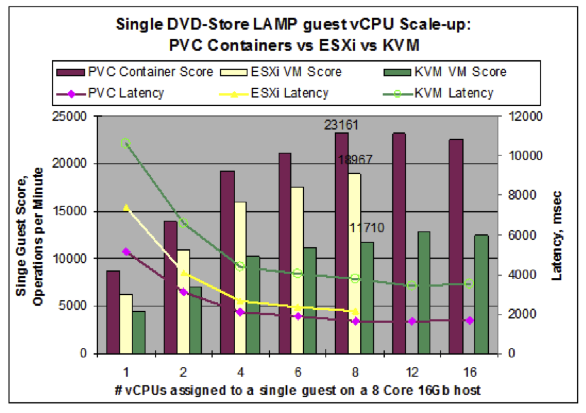
Вроде больше нету, но даже по графикам от RedHat можно четко сказать, что KVM сейчас сильнее ESXi. А контейнеры быстрее их обоих, но имеют ограничения.
Графики оттуда:

И еще вот очень наглядный с процентами график оттуда же:

Вот исследование от Parallels, там про их платформу, но есть и графики про KVM vs ESXi:
www.parallels.com/fileadmin/parallels/documents/hosting-cloud-enablement/pvc/whitepapers/Performance_Comparison_White_Paper.pdf
Вот, пожалуйста:

Вроде больше нету, но даже по графикам от RedHat можно четко сказать, что KVM сейчас сильнее ESXi. А контейнеры быстрее их обоих, но имеют ограничения.
Довольно странно видеть сравнение текущей версии KVM с древним ESXi 4.1, у которого уже наступил EOL.
Странные сравнения, мало того что сравнивают на разных серверах так еще сравнивают esx 4.1 с KVM.
А я спрашивал про ESXi с KVM (на одинаковом железе)
А я спрашивал про ESXi с KVM (на одинаковом железе)
Разные конфигурации лишь на первом графике, на втором сравнивается идентичное железо. Откройте pdf, там все описано подробно :)
есть нюанс — вмварь запрещает публикацию бенчмарков, если те не показывают их в позитивном свете. поэтому они не опубликовали тесты на 8 ядер вообще, а последний опубликованный спеквирт делали на 4.1, ДО того как стало понятно что через такой открытый тест можно будет делать сравнения в обход EULA. потом видать стыдно сталo, и они вообще перестали публиковать тесты, хотя проводятся они регулярно — спеквирт разрабатывался собственно вмварью с партнерами, чтоб показать систему в позитивном свете.
так что объективное сравнение с вмварью найти очень трудно — оно или чисто маркетинговое, подстроенное под особые ситуации где из вмвари можно выжать больше чем из других систем, или просто не будет опубликовано.
так что объективное сравнение с вмварью найти очень трудно — оно или чисто маркетинговое, подстроенное под особые ситуации где из вмвари можно выжать больше чем из других систем, или просто не будет опубликовано.
Ого, какие интересные подробности! Все упирается в качественное проведение тестирование третьими лицами, до которых не доберется VmWare в случае проигрыша :)
С этими ясно, но почему нет сравнения с Hyper-V? В последней версии допилили поддержку Linux, так что местами она превосходит VMware.
И как насчёт TPC-VMS?
И как насчёт TPC-VMS?
конечно трудно, если выкладываются только причесанные, выбранные заранее результаты, а не чистый эксперимент сделанный независимым тестировщиком
Так, давай определимся что такое spec — классическая пузомерка но
1. Она требует опубликования использованого железа.
2. Она одинакова для всех.
3. Доступны подробные отчеты, что как конфигурировалось и как делалось.
При желании каждый желающий может повторить тест дома на кофеварке :)
Это блин один из самых объективный тестов, насколько тесты сами по себе могут быть объективны мы умолчим.
1. Она требует опубликования использованого железа.
2. Она одинакова для всех.
3. Доступны подробные отчеты, что как конфигурировалось и как делалось.
При желании каждый желающий может повторить тест дома на кофеварке :)
Это блин один из самых объективный тестов, насколько тесты сами по себе могут быть объективны мы умолчим.
есть нюанс :) сколько таких спеков оказались не в пользу вмвари мы не узнаем никогда, они _разрешат_ опубликовать только те которые выгодны им. Все остальные ничем не ограничивают эти публикации, что приводит к изрядному дисбалансу в результатах, и заставляет сильно сомневаться в объективности данных результатов.
Если никто еще не догадался, вмварь сегодня это микрософт конца 90х — главный хищник в своей нише, доящий клиентов по максимуму, и не чурающийся любых методов. Это не хорошо и не плохо, это просто факт, и война за рынок идет нешуточная — сейчас не 90-е, и конкурентов хоть отбавляй. Пузомерки — это инструмент для маркетинга, и там где RHT и, кстати, даже майкрософт, не особо парятся насчет результатов — и у тех и у других достаточно аргументов в свою пользу, лояльных клиентов, и что самое важное — плюс полноценный стек от ОС до аппликаций, вмварь живет за счет виртуализации и ничего другого у них нет, так что для них каждая такая публикация критична.
Если никто еще не догадался, вмварь сегодня это микрософт конца 90х — главный хищник в своей нише, доящий клиентов по максимуму, и не чурающийся любых методов. Это не хорошо и не плохо, это просто факт, и война за рынок идет нешуточная — сейчас не 90-е, и конкурентов хоть отбавляй. Пузомерки — это инструмент для маркетинга, и там где RHT и, кстати, даже майкрософт, не особо парятся насчет результатов — и у тех и у других достаточно аргументов в свою пользу, лояльных клиентов, и что самое важное — плюс полноценный стек от ОС до аппликаций, вмварь живет за счет виртуализации и ничего другого у них нет, так что для них каждая такая публикация критична.
Если никто еще не догадался, вмварь сегодня это микрософт конца 90х — главный хищник в своей нише, доящий клиентов по максимуму, и не чурающийся любых методов.
После смены CEO стало получше, но процесс разработки они так и не смогли построить… Ядром пока занимаются нормальные спецы, а вот вся обвязка написана рукожопыми индусами и не проходит QA, если судить по качеству конечных продуктов.
Ну это так сказать дело вендора, публиковать и показывать или не публиковать и гнать булшит на презентахах.
Некоторые успешно совмещают оба подхода одновременно :)
Все остальные ничем не ограничивают эти публикации,
Остальные это кто? С опенсурсами все понятно, там нет возможности запрещать.
Оракл имеет такую же политику по апруву тестов их ВМ
Майкрософт тоже не одобряе честную конкуренцию.
В мире корпораций так принято. Так что не надо рассказывать какие остальные пушистые.
Если так хочется побороться за справедливость помаши пачкой денег, вендоры сами сбегуться и отдадутся на тесты, будешь потом что хочешь и где хочешь писать про результаты.
Некоторые успешно совмещают оба подхода одновременно :)
Все остальные ничем не ограничивают эти публикации,
Остальные это кто? С опенсурсами все понятно, там нет возможности запрещать.
Оракл имеет такую же политику по апруву тестов их ВМ
Майкрософт тоже не одобряе честную конкуренцию.
В мире корпораций так принято. Так что не надо рассказывать какие остальные пушистые.
Если так хочется побороться за справедливость помаши пачкой денег, вендоры сами сбегуться и отдадутся на тесты, будешь потом что хочешь и где хочешь писать про результаты.
> Остальные это кто? С опенсурсами все понятно, там нет возможности запрещать.
там есть возможность доказать свою «белость и пушистость» делом — сделав на самом деле хорошо, так что не подкопаешься.
> Майкрософт тоже не одобряе честную конкуренцию
там нет проблем публиковать бенчмарки. они просто в свое время не додумались такой запрет ввести. в любом случае, hyper-v набирает и будет набирать поклонников, я сам их вижу на каждом шагу — люди не хотят отходить от известных им технологий ни на шаг, а так как за все платит фирма, сокращать расходы им ни к чему. Более того, годовые бюджеты надо тратить, иначе на следующий год не дадут.
> В мире корпораций так принято. Так что не надо рассказывать какие остальные пушистые.
никто не пушистый, просто наивно считать тесты опубликованные при таких ограничениях объективными. Особенно когда разговор идет о вмвари, которые очень остро чувствуют нишевость своего продукта и уязвимость такой позиции. Они потому в свое время и зимбру купили, и потому все давно ждут когда они Новелл захапают — именно чтоб выйти на более широкий рынок где они смогут проталкивать цельные решения а не только один продукт.
> Если так хочется побороться за справедливость помаши пачкой денег, вендоры сами сбегуться и отдадутся на тесты, будешь потом что хочешь и где хочешь писать про результаты.
чушь. у вмвари и их папика ЕМС денег побольше будет.
там есть возможность доказать свою «белость и пушистость» делом — сделав на самом деле хорошо, так что не подкопаешься.
> Майкрософт тоже не одобряе честную конкуренцию
там нет проблем публиковать бенчмарки. они просто в свое время не додумались такой запрет ввести. в любом случае, hyper-v набирает и будет набирать поклонников, я сам их вижу на каждом шагу — люди не хотят отходить от известных им технологий ни на шаг, а так как за все платит фирма, сокращать расходы им ни к чему. Более того, годовые бюджеты надо тратить, иначе на следующий год не дадут.
> В мире корпораций так принято. Так что не надо рассказывать какие остальные пушистые.
никто не пушистый, просто наивно считать тесты опубликованные при таких ограничениях объективными. Особенно когда разговор идет о вмвари, которые очень остро чувствуют нишевость своего продукта и уязвимость такой позиции. Они потому в свое время и зимбру купили, и потому все давно ждут когда они Новелл захапают — именно чтоб выйти на более широкий рынок где они смогут проталкивать цельные решения а не только один продукт.
> Если так хочется побороться за справедливость помаши пачкой денег, вендоры сами сбегуться и отдадутся на тесты, будешь потом что хочешь и где хочешь писать про результаты.
чушь. у вмвари и их папика ЕМС денег побольше будет.
Они потому в свое время и зимбру купили, и потому все давно ждут когда они Новелл захапают
Не совсем, Зимбру и Шавлика они купили
чушь. у вмвари и их папика ЕМС денег побольше будет.
Не, я к тому что объявляешь тендер, набигают интергаторы вендораторами и начинается цирк :) Результаты показательных метаний какашек и тестов на твоих задачах можешь хоть в переходах раздавать.
Не, я к тому что объявляешь тендер, набигают интергаторы вендораторами и начинается цирк :) Результаты показательных метаний какашек и тестов на твоих задачах можешь хоть в переходах раздавать.
Боюсь для вас это будет шоком, а для меня очередным минусом к карме. Но я вам открою тайну. Open source это девушка легкого поведения. Она дает любому, лишь бы ей было бабло. И вот однажды… эта девушка находит богатенького папененьку и начхав на всех своих поклонников… продается ему с потрохами. Такова судьба любого сколь значимого проекта. Раздвинуть ноги чтоб заработать побольше.
Вот как могут развиваться события:
— код вливается в другой коммерческий продукт и продается!
— продукт меняет название и продается теми кто его изначально создал!
— продукт ваще нафиг убивают и кодеров переводят на другие работы
— код переписывается другими компаниями(в идеале. часто даже этого не делают), чучуть правится лицо и продается уже ими как новый продукт!!!
— разрабы начинают регулярно плакать что денег нет и выходят на всякие кикстары. шантажируя пользователя что иначе они его не потянут
— в корявом продукте делают некоторые ключевые возможности платными. и без них очень неудобно работать.
— продукт с новой версией делается платным. мотивируется желанием купить яхту разработчику.
— делается платной техническая поддержка. и продукт усложняется чтоб юзвери не могли сами решить проблему.
— параллельно делается платная версия продукта для коммерческой деятельности.
— на продукт все забивают бооооольшой болт.
— в продукт до тошнорвотности суют рекламы.
И я думаю что примеры вам не нужно называть. Если вы айтишник. то легко сами под каждый пункт наберете с десяток.
Есть и другие схемы чтоб сосать деньги с пользователей. К чему я веду? Да всё просто. За любой продукт нужно платить. Вы просто это не замечаете. Наиболее частая схема оплаты это обратная связь с пользователем. Который выступает тестером. Тратя время на борьбу с багами, их отловом, классификацией, решением… вы вносите свою плату за пользование продуктом. Продукт потом правят и продают уже коммерческую версию организациям. Но есть одна проблемка. При такой схеме всё меньше организаций готовы платить за эти продукты. Им нужна полная халява. А пользователь не готов тратить время на отлов багов. Жизнь не резиновая.
Теперь к вопросу того что будущее за халявой. Боюсь что нет. =) Как бы вам попроще… объяснить. На данном витке истории мы занимаемся тем что переливаем ПО из пустого в порожнее. Это может делать даже школьник. Но уже сейчас!!! возникает проблема с кадрами. Точнее с уровнем специалистов. Нужны высококлассные математики которые рождаются раз в сто лет. Нужны гениальные кодеры для оптимизации кода. Нужны ресурсы для инвентаризации уже написанного. А на подходе квантовые компы и другие процессорные логики. Будет новый виток. Во главу таких компьютеров станут математики, которые будут пытаться извлечь максимальный кпд из них. Системы будут архисложными!!! Для того чтоб всё это развивать потребуется консолидация ресурсов. А все эти люди хотят регулярно кушать, а не на кикстарах по тысченке-другой выбивать. Начнется укрупнение уже имеющихся продуктов. Поглощение мелочи.
Так что выводы делаем сами. Ах да… мы отвлеклись от нашей девушки легкого поведения. ЕЕ судьба проста.
— она умерла от болезней на лечение которых не нашла деньги (болезни то все профессиональные)
— ее спонсирует папик. который ее пялит в свободное время (АНБ к примеру =))
— она умерла с голоду(ей бы шпалы носить, а не на панелях стоять).
— она стала респектабельной дамой и чмырит всех тех с кем раньше работала вместе.
— она начала мыть полы. так как на панели появились уже более симпотишные девушки и помладше.
Но она не может стать нормальной семьянинкой!!! Ибо нормальные девушки зарабатывают по другому.
Вот судьба открытого ПО. Очень мало кто работает в этой области для души. Большинство начинает с рассказов что он такой убогий и ему нужна поддержка пользователей. Потом монетизация и новый формат. Не люблю двуличия. Поэтому не люблю и все эти гнилые разговоры о опен соусе. Но при этом я уважаю тех кто реально работает за идею! Пусть даже в программе из 2000 строк. Но много ли таких найдется?
p.s. Хотелось бы назвать еще одну причину почему все лучшие продукты платные. Юзабилити!!! Для того чтоб сделать хороший продукт… как все это известно… нужно не дать кодерам участвовать в разработке интерфейса. В коммерческом продукте нанимаются психологи, специалисты по юзабилити и прочие няшные профессии. Дабы они занимались тем с чем работает обычный юзверь. И в этих профессиях нет больных опенсоурс психологов, опенсоурс проектировщиков, опенсоурс дизайнеров. Такого нет в природе!!! Это противоестественно и не приносит денег. А значит свободное ПО не дотянет никогда до уровня коммерческого. ИМХО.
А знаете к чему я всё это вел? Если тебе нравится секс, то трахайся с кем хочешь. Это твое право. И это твой кайф. Но если ты работаешь девушкой легкого поведения и это твоя профа… не корчи из себя мать Терезу. Признайся что это твоя профессия и что ты хочешь от нее как можно больше бабла(или просто чонибудь покушать). Признайся, не потом когда у тебя уже армия поклонников, а сразу. Будь честен с людьми и собой.
В завершение у меня вот какой вопрос. Я хочу чтоб большинство из вас честно на него ответили для себя. Если бы лицензия опенсоурс была жоще. И запрещала любую из вышеописанных форм монетизации. Решились ли бы вы делать такой продукт? Я думаю я знаю ответ для 99% людей на хабре. Так кому после этого признания нужно сливать карму? =)
Вот как могут развиваться события:
— код вливается в другой коммерческий продукт и продается!
— продукт меняет название и продается теми кто его изначально создал!
— продукт ваще нафиг убивают и кодеров переводят на другие работы
— код переписывается другими компаниями(в идеале. часто даже этого не делают), чучуть правится лицо и продается уже ими как новый продукт!!!
— разрабы начинают регулярно плакать что денег нет и выходят на всякие кикстары. шантажируя пользователя что иначе они его не потянут
— в корявом продукте делают некоторые ключевые возможности платными. и без них очень неудобно работать.
— продукт с новой версией делается платным. мотивируется желанием купить яхту разработчику.
— делается платной техническая поддержка. и продукт усложняется чтоб юзвери не могли сами решить проблему.
— параллельно делается платная версия продукта для коммерческой деятельности.
— на продукт все забивают бооооольшой болт.
— в продукт до тошнорвотности суют рекламы.
И я думаю что примеры вам не нужно называть. Если вы айтишник. то легко сами под каждый пункт наберете с десяток.
Есть и другие схемы чтоб сосать деньги с пользователей. К чему я веду? Да всё просто. За любой продукт нужно платить. Вы просто это не замечаете. Наиболее частая схема оплаты это обратная связь с пользователем. Который выступает тестером. Тратя время на борьбу с багами, их отловом, классификацией, решением… вы вносите свою плату за пользование продуктом. Продукт потом правят и продают уже коммерческую версию организациям. Но есть одна проблемка. При такой схеме всё меньше организаций готовы платить за эти продукты. Им нужна полная халява. А пользователь не готов тратить время на отлов багов. Жизнь не резиновая.
Теперь к вопросу того что будущее за халявой. Боюсь что нет. =) Как бы вам попроще… объяснить. На данном витке истории мы занимаемся тем что переливаем ПО из пустого в порожнее. Это может делать даже школьник. Но уже сейчас!!! возникает проблема с кадрами. Точнее с уровнем специалистов. Нужны высококлассные математики которые рождаются раз в сто лет. Нужны гениальные кодеры для оптимизации кода. Нужны ресурсы для инвентаризации уже написанного. А на подходе квантовые компы и другие процессорные логики. Будет новый виток. Во главу таких компьютеров станут математики, которые будут пытаться извлечь максимальный кпд из них. Системы будут архисложными!!! Для того чтоб всё это развивать потребуется консолидация ресурсов. А все эти люди хотят регулярно кушать, а не на кикстарах по тысченке-другой выбивать. Начнется укрупнение уже имеющихся продуктов. Поглощение мелочи.
Так что выводы делаем сами. Ах да… мы отвлеклись от нашей девушки легкого поведения. ЕЕ судьба проста.
— она умерла от болезней на лечение которых не нашла деньги (болезни то все профессиональные)
— ее спонсирует папик. который ее пялит в свободное время (АНБ к примеру =))
— она умерла с голоду(ей бы шпалы носить, а не на панелях стоять).
— она стала респектабельной дамой и чмырит всех тех с кем раньше работала вместе.
— она начала мыть полы. так как на панели появились уже более симпотишные девушки и помладше.
Но она не может стать нормальной семьянинкой!!! Ибо нормальные девушки зарабатывают по другому.
Вот судьба открытого ПО. Очень мало кто работает в этой области для души. Большинство начинает с рассказов что он такой убогий и ему нужна поддержка пользователей. Потом монетизация и новый формат. Не люблю двуличия. Поэтому не люблю и все эти гнилые разговоры о опен соусе. Но при этом я уважаю тех кто реально работает за идею! Пусть даже в программе из 2000 строк. Но много ли таких найдется?
p.s. Хотелось бы назвать еще одну причину почему все лучшие продукты платные. Юзабилити!!! Для того чтоб сделать хороший продукт… как все это известно… нужно не дать кодерам участвовать в разработке интерфейса. В коммерческом продукте нанимаются психологи, специалисты по юзабилити и прочие няшные профессии. Дабы они занимались тем с чем работает обычный юзверь. И в этих профессиях нет больных опенсоурс психологов, опенсоурс проектировщиков, опенсоурс дизайнеров. Такого нет в природе!!! Это противоестественно и не приносит денег. А значит свободное ПО не дотянет никогда до уровня коммерческого. ИМХО.
А знаете к чему я всё это вел? Если тебе нравится секс, то трахайся с кем хочешь. Это твое право. И это твой кайф. Но если ты работаешь девушкой легкого поведения и это твоя профа… не корчи из себя мать Терезу. Признайся что это твоя профессия и что ты хочешь от нее как можно больше бабла(или просто чонибудь покушать). Признайся, не потом когда у тебя уже армия поклонников, а сразу. Будь честен с людьми и собой.
В завершение у меня вот какой вопрос. Я хочу чтоб большинство из вас честно на него ответили для себя. Если бы лицензия опенсоурс была жоще. И запрещала любую из вышеописанных форм монетизации. Решились ли бы вы делать такой продукт? Я думаю я знаю ответ для 99% людей на хабре. Так кому после этого признания нужно сливать карму? =)
Ограничусь тем, что скажу, что в корне с Вами не согласен и искренее уверен, что будущее именно в open source виртуализации.
Все возможные ситуации «кинут» / «закроют проект» / «продадутся» в случае KVM, Xen решились в итоге тем, что были созданы консорциумы из десятков компаний для поддержки и коллективного управления данными проектами.
Для KVM это Open Virtualization Alliance, в который в свою очередь входят: Intel, HP, IBM, RedHat, NetApp, Intel, Acronis, AMD и прочие. (полный список тут)
А для Xen это Xen Project, в который входят Amazon, AMD, Google, Intel, Samsung и прочи. (полный список участников тут)
Про ядро Linux (то есть lxc в своей сути) я говорить даже не буду, честно говоря, там примерно такой же список в несколько тысяч компаний.
Кроме того, я явно в теблице сделал упор на лицензию всех продуктов — она GPLv2, что в свою очередь запрещает возможность использования другими компаниями без открытия изменений в коде.
Все возможные ситуации «кинут» / «закроют проект» / «продадутся» в случае KVM, Xen решились в итоге тем, что были созданы консорциумы из десятков компаний для поддержки и коллективного управления данными проектами.
Для KVM это Open Virtualization Alliance, в который в свою очередь входят: Intel, HP, IBM, RedHat, NetApp, Intel, Acronis, AMD и прочие. (полный список тут)
А для Xen это Xen Project, в который входят Amazon, AMD, Google, Intel, Samsung и прочи. (полный список участников тут)
Про ядро Linux (то есть lxc в своей сути) я говорить даже не буду, честно говоря, там примерно такой же список в несколько тысяч компаний.
Кроме того, я явно в теблице сделал упор на лицензию всех продуктов — она GPLv2, что в свою очередь запрещает возможность использования другими компаниями без открытия изменений в коде.
столько воплей ни о чем. опенсорс это открытый код, доступный бесплатно. это не означает что писать его нужно не за зарплату. это не означает что на этом нельзя делать деньги, продавая поддержку, интеграцию, даже доступ к грамотной сборке в конце концов.
это означает что _код_ находится в свободном доступе, не больше не меньше, вот и весь идеализм.
это означает что _код_ находится в свободном доступе, не больше не меньше, вот и весь идеализм.
Спасибо за статью. А особое спасибо за указание ссылок на полезные исследования.
Жду статью о недостатках контейнеров.
Жду статью о недостатках контейнеров.
При использовании KVM накладные расходы на сеть становятся заметно ниже при использовании vhost для сети. Я бы сказал, что это только расходы на поддержку сетевого моста и tap-устройства, то есть то же самое, что и в openvz при использовании veth.
Для диска OpenVZ сейчас предлагает использовать ploop, у которого накладные расходы сравнимы с дисковыми накладными расходами от xen/kvm+virtio, так как принцип работы тот же.
Пользовательский код выполняется что на kvm, что на openvz абсолютно одинаково без оверхеда (если не считать лишнего уровня косвенности при обращении к таблице страниц (но его почти убирает TLB) и возможных тонкостей с вытеснением нужной информации из кеша). Проблема остается только с системными вызовами, но тут у каждой из виртуализаций свои проблемы.
Но KVM проще и обеспечивает больший уровень изоляции.
Для диска OpenVZ сейчас предлагает использовать ploop, у которого накладные расходы сравнимы с дисковыми накладными расходами от xen/kvm+virtio, так как принцип работы тот же.
Пользовательский код выполняется что на kvm, что на openvz абсолютно одинаково без оверхеда (если не считать лишнего уровня косвенности при обращении к таблице страниц (но его почти убирает TLB) и возможных тонкостей с вытеснением нужной информации из кеша). Проблема остается только с системными вызовами, но тут у каждой из виртуализаций свои проблемы.
Но KVM проще и обеспечивает больший уровень изоляции.
Честно говоря, я бы не сравнивал ploop и проброс блочного устройства/файла как диска виртуальной машины. У ploop есть ряд неоспоримых преимуществ — не нужно заботится о целостности файловой системы и беспокоится о fsck, также есть ploop compact, который может сжать излишне распухший образ диска до размеров файловой системы. Аналогов такой фичи, по моей инфорации, в KVM пока нет и есть лишь попытки частичной реализации этого подхода. Но и да — ploop не лишен проблем, но их я уточню в следующей публикации, потому что в двух словах сложно сформулировать да и без контекста будет не понятно.
По поводу vhost — тут сказать ничего не могу, на скорость сети при использовании virtio даже без vhost на KVM мы вовсе не жаловались :)
А вот про простоту KVM не согласен, на фоне virsh vzctl из OpenVZ просто мана небесная по части юзабилити и удобства — никакого XML и никаких странных огромных конфигов :)
По поводу vhost — тут сказать ничего не могу, на скорость сети при использовании virtio даже без vhost на KVM мы вовсе не жаловались :)
А вот про простоту KVM не согласен, на фоне virsh vzctl из OpenVZ просто мана небесная по части юзабилити и удобства — никакого XML и никаких странных огромных конфигов :)
По поводу фич Вы правы, подход, который разделяет управление дисковыми устройствами и виртуализацией, затрудняет реализацию таких вещей. Но если говорить о производительности, sparse-файл со своей ФС внутри явно проиграет проброшенному LV или блочному устройству.
Под простотой я имел в виду внутреннее устройство. OpenVZ лезет почти во все подсистемы ядра, и переносить в осн. ветку эти воздействия начали относительно недавно. А чем больше объем системы, тем больше в ней ошибок. На ядре 2.6.18, которое совсем не использовало LXC, иногда возникали очень печальные баги (вроде проседания сети в 1.5 раза) даже без запущенных контейнеров, просто после перезагрузки в OpenVZ-ядро. Сейчас, как я понимаю, должно стать лучше.
А XML это не минус, а плюс. Все равно при продаже VPS или облаков клиентам нужно писать им панель/биллинг, и тут перекидываться xml-ками с libvirt будет удобнее, чем текстом с vzctl.
Под простотой я имел в виду внутреннее устройство. OpenVZ лезет почти во все подсистемы ядра, и переносить в осн. ветку эти воздействия начали относительно недавно. А чем больше объем системы, тем больше в ней ошибок. На ядре 2.6.18, которое совсем не использовало LXC, иногда возникали очень печальные баги (вроде проседания сети в 1.5 раза) даже без запущенных контейнеров, просто после перезагрузки в OpenVZ-ядро. Сейчас, как я понимаю, должно стать лучше.
А XML это не минус, а плюс. Все равно при продаже VPS или облаков клиентам нужно писать им панель/биллинг, и тут перекидываться xml-ками с libvirt будет удобнее, чем текстом с vzctl.
Да, тут со всем соглашусь кроме медленности ploop. Но вот подкрепить свое несогласие мне, к сожалению, нечем :( Если кто-то из Parallels нас читает — может подкинете тесты ploop?
Да, 2.6.18 вела себя странно во многих случаях. А с numa там вообще ад творился. Но в 2.6.32 все уже намного стабильнее, а в RHEL7 (ядро 3.2) будет вообще-вообще чудесно.
Ничего личного, не люблю XML :) У KVM скорее преимущество в самом протоколе libvirt, мы в свое время отправляли свои патчи в libvirt-php, чтобы саспенд добавить, было очень удобно.
Но мучения «как сгенерировать xml блок для активации вот такой фичи» иногда длились неделями и вынуждали делать это черещ virt-manager и потом разгребать что же за код он сконструктировал :)
Да, 2.6.18 вела себя странно во многих случаях. А с numa там вообще ад творился. Но в 2.6.32 все уже намного стабильнее, а в RHEL7 (ядро 3.2) будет вообще-вообще чудесно.
Ничего личного, не люблю XML :) У KVM скорее преимущество в самом протоколе libvirt, мы в свое время отправляли свои патчи в libvirt-php, чтобы саспенд добавить, было очень удобно.
Но мучения «как сгенерировать xml блок для активации вот такой фичи» иногда длились неделями и вынуждали делать это черещ virt-manager и потом разгребать что же за код он сконструктировал :)
Зачем текстом, можно в json формате. Ну и к libvirt есть модуль для OpenVZ.
В json формате можно только читать выдачу vzlist -j, а вот vzctl ни принимать, ни отдавать данные в json не умеет. Впрочем, мы тут сделали кое-что для решения этой проблемы, возможно, в скором будущем будут новости.
Модуль libvirt для openvz на тот момент когда я его изучал (около 2х лет назад) не умел почти ничего кроме создания впски с заданным объемом диска/памяти, о рулеже vswap, вторичными UBC там и речи не было. Так что, к сожалению, тут libvirt пока не подходит для реализации задачи рулежа openvz.
Модуль libvirt для openvz на тот момент когда я его изучал (около 2х лет назад) не умел почти ничего кроме создания впски с заданным объемом диска/памяти, о рулеже vswap, вторичными UBC там и речи не было. Так что, к сожалению, тут libvirt пока не подходит для реализации задачи рулежа openvz.
У ploop есть ряд неоспоримых преимуществ… Аналогов такой фичи, по моей инфорации, в KVM
QEMU не занимается хранением данных, за поддержку конкретного формата хранения или конкретной СХД отвечает драйвер (драйверов у QEMU штук 10, в том числе всякие под vmdk, ceph и прочие). Ну а sparse режим хранения поддерживают если не все, то большинство из них. Можно было бы написать драйвер, который поддерживает формат хранения ploop, другое дело непонятно кому и зачем это может понадобиться, т.к. ploop решает чисто контейнерные проблемы, которых в мире полной виртуализации нет (вернее проблемы есть, но и решений полно).
А ploop — это вовсе не sparse файл, вот тут даже откровенно говорится, что нельзя делать ploop файл spars'ным: openvz.org/Ploop/sparse
Как раз в KVM очень остро (могу сказать лишь от лица провайдеров) стоит проблема с тем, что место выделяется не по мере заполнения, а сразу. То есть если нам нужен контейнер на 100 Гб, а в нем реально используется от силы 1-2 Gb в случае KVM он будет занимать сразу же 100Gb, а в случае ploop будет заниматься объем файловой системы + 10-20%, то есть около 2х гб.
Для решения этого в KVM есть LVM thin provisioning, но для vzctl compact/ploop compact ему, на мой взгдяд, еще несколько лет в развитии да и вообще подход используемый в thin provision мне не нравится чисто архитектурно.
Как раз в KVM очень остро (могу сказать лишь от лица провайдеров) стоит проблема с тем, что место выделяется не по мере заполнения, а сразу. То есть если нам нужен контейнер на 100 Гб, а в нем реально используется от силы 1-2 Gb в случае KVM он будет занимать сразу же 100Gb, а в случае ploop будет заниматься объем файловой системы + 10-20%, то есть около 2х гб.
Для решения этого в KVM есть LVM thin provisioning, но для vzctl compact/ploop compact ему, на мой взгдяд, еще несколько лет в развитии да и вообще подход используемый в thin provision мне не нравится чисто архитектурно.
А ploop — это вовсе не sparse файл
Я не говорил, что ploop это sparse файл. Я писал, что для решения вашей проблемы достаточно выбрать любой формат/СХД, которая поддерживает sparse хранение данных, то есть не аллоцирует нули при создании волюма.
Как раз в KVM очень остро стоит проблема с тем, что место выделяется не по мере заполнения, а сразу.
Еще раз: QEMU/KVM не занимается хранением данных в каком-то одном формате а имеет множество драйверов для различных форматов и систем хранения данных и оставляет вам возможность выбора. Поэтому проблема в данном случае исключительно ваша, причем такая, которую надо целенаправленно создавать, потому что в режиме по умолчанию (raw образ, хранимый в sparse режиме) этой проблемы нет. Возможно какие то ваши действия привели к аллокации нулей в образах, ну тогда сделайте над образами cp --sparse=always file1 file1_sparsed и все у вас будет ок.
То есть если нам нужен контейнер на 100 Гб, а в нем реально используется от силы 1-2 Gb в случае KVM он будет занимать сразу же 100Gb, а в случае ploop будет заниматься объем файловой системы + 10-20%, то есть около 2х гб.
Вот я создал 10Тб образ в дефолтном raw формате на разделе размером 8Гб. Что я делаю не так?
root@node04:~# qemu-img create disk-image 10000000000000
Formatting 'disk-image', fmt=raw size=10000000000000
root@node04:~# ls -la disk-image
-rw-r--r-- 1 root root 10000000000000 Jan 11 18:32 disk-image
root@node04:~# df -H
Filesystem Size Used Avail Use% Mounted on
rootfs 12G 8.0G 3.1G 73% /
Ок, давайте для определенности спора (и более убедительного принятия преимуществ ploop) сформулируем методолгию.
1. Аллоцируйте виртаульной машине 100 Гб
2. Установите Linux ОС, допустим, она займет 1 Гб
3. Залейте в виртуальную машину 99 Гб данных, чтобы диск на 100 Гб был забит полностью
4. Удалите все 99 Гб данных, чтобы осталась только чистая ОС, то есть 1 Гб
5. Сообщите, сколько места будет занимать образ диска данной виртуальной машины
6. Любыми средствами без ребута машины и опасности для данных добейтесь сжатия образа хотя бы до 2-5 Гб вместо 100.
В случае ploop пункты 5 и 6 будут такие:
5. Образ будет занимать 100 Гб
6. Запускаем vzctl compact или ploop compact и без даунтайма, повреждений фс сжимаем объем образа до объема файловой системы, то есть до где-то 1 Гб (+ 10-15% за счет накладных расходов)
В случае же KVM вы будете хранить 99 Гб до скончания веков даже если клиент/разработчик/сотрудник никогда не будет ими пользоваться.
1. Аллоцируйте виртаульной машине 100 Гб
2. Установите Linux ОС, допустим, она займет 1 Гб
3. Залейте в виртуальную машину 99 Гб данных, чтобы диск на 100 Гб был забит полностью
4. Удалите все 99 Гб данных, чтобы осталась только чистая ОС, то есть 1 Гб
5. Сообщите, сколько места будет занимать образ диска данной виртуальной машины
6. Любыми средствами без ребута машины и опасности для данных добейтесь сжатия образа хотя бы до 2-5 Гб вместо 100.
В случае ploop пункты 5 и 6 будут такие:
5. Образ будет занимать 100 Гб
6. Запускаем vzctl compact или ploop compact и без даунтайма, повреждений фс сжимаем объем образа до объема файловой системы, то есть до где-то 1 Гб (+ 10-15% за счет накладных расходов)
В случае же KVM вы будете хранить 99 Гб до скончания веков даже если клиент/разработчик/сотрудник никогда не будет ими пользоваться.
С qcow можно сделать через заранее приготовленный костыль:
— имеем 1 qcow образ, над ним vg, там допустим полностью зааллоцированный /,
— дискардим байтики в /, подключаем новый образ того же размера, перевозим vg на него,
— отключаем-подключаем первый, предварительно пересоздав,
— перевозим vg обратно и отключаем и удаляем своп-диск.
Все это применимо к virtio-pci/virtio-scsi/scsi в случае qemu.
Немного непонятны причины того, что а) я заранее не предусмотрел отдельное отключаемое блочное устройство на этот случай, б) не могу выключить машину, на мой взгляд, это честная плата за возможность дискарднуть в онлайне без подготовки, в) cow образ вряд ли будет показывать хорошие результаты по производительности, вне зависимости от вендора.
— имеем 1 qcow образ, над ним vg, там допустим полностью зааллоцированный /,
— дискардим байтики в /, подключаем новый образ того же размера, перевозим vg на него,
— отключаем-подключаем первый, предварительно пересоздав,
— перевозим vg обратно и отключаем и удаляем своп-диск.
Все это применимо к virtio-pci/virtio-scsi/scsi в случае qemu.
Немного непонятны причины того, что а) я заранее не предусмотрел отдельное отключаемое блочное устройство на этот случай, б) не могу выключить машину, на мой взгляд, это честная плата за возможность дискарднуть в онлайне без подготовки, в) cow образ вряд ли будет показывать хорошие результаты по производительности, вне зависимости от вендора.
Тут позвольте дополнить — чем именно дискардить байтики. Есть чудесная тулза от GuestFS: http://libguestfs.org/virt-sparsify.1.html
Конечно, хотелось бы получить такую фичу нэтивно где-нибудь в Qcow 3, чтобы избежать подобных комплексных операций.
Конечно, хотелось бы получить такую фичу нэтивно где-нибудь в Qcow 3, чтобы избежать подобных комплексных операций.
Ну можно использовать zerofree или ддшнуть+удалить файл с нулями в фс гостя. В целом кейс очень редкий, поскольку либо можно использовать энтерпрайз хранилище и thin provisioning(о маргинальных вариантах типа lvm для тех же целей лучше не упоминать), либо просто смириться — такие случаи будут редки, оверселлить хранилище в случае qcow образов вы всяко сможете многократно, плюс этот компакт даст со стапроцентной вероятностью усаживание характеристик блочного устройства гостя как минимум на порядок.
Я правильно понимаю, что это все через даунтайм? В ploop сжатие онлайн.
А давай вспомним еще simfs (фича OpenVZ, чем-то похожа на sub-volume в btrfs). Там ваша задача места просто отсутствует, т е там нет накладных расходов по месту бай дизаин.
Кстати, получается, что vzfs в mainline — это mnt namespace + доп фичи?
vzfs отдельно, изоляция файловых систем отдельно. vzfs — это кеширование файлов между контейнерами + квота. simfs — только квота.
Так кэширования в openvz не было никогда, это просто платформа для его реализации?
Ты хотел сказать vzfs в OpenVZ не было никогда;)
Ну, в документации simfs вы зовете vzfs kb.parallels.com/en/119015 =)
вот это уже очень странно, на фоне грамотного обзора. KVM во первых вообще к форматам дисков никак не относится, а QEMU поддерживает множество форматов, многие из которых «тонкие»
Почему странно? Ведь, когда речь идет о KVM/Xen/OpenVZ обычно всех интересуют не чистые абстрактные характеристики конкретно слоя виртуализации, но и весь стек, то есть и система хранения в первую очереь.
Если уж совсем рассматриваться формально, К OpenVZ ploop тоже не сильно относится — это тоже только один формат хранения, так как можно использовать и ploop и simfs и даже обычные блочные (и, конечно же, LVM) разделы.
Если уж совсем рассматриваться формально, К OpenVZ ploop тоже не сильно относится — это тоже только один формат хранения, так как можно использовать и ploop и simfs и даже обычные блочные (и, конечно же, LVM) разделы.
вот в том-то и дело, KVM — часть линукса, и работает на любом хранилище которое поддерживает линукс, вплоть до совсем экзотичных (morgan-stanley например, емнип на AFS гоняют несколько тысяч хостов)
Так и lxc и OpenVZ работают точно также! Диск контейнера на OpenVZ — это всего-лишь папка в файловой иерархии Linux, не более того.
А папка может быть и примонтированной флешкой, и iSCSI устройством размещенным за тысячи километров, и сложным проприетарным СХД и еще тысячей других вариантов реализации СХД.
То есть тут получается гибкость ровно на том же уровне, как и у KVM. Но, разумеется, не без ложки дегтя. Взять и подключить блочное устройство к контейнеру «совсем красиво» (под этим я подразумеваю поддержку такой фичи в официальной поставке) нельзя, нужно его грамотно монтировать через спец-скрипты.
А папка может быть и примонтированной флешкой, и iSCSI устройством размещенным за тысячи километров, и сложным проприетарным СХД и еще тысячей других вариантов реализации СХД.
То есть тут получается гибкость ровно на том же уровне, как и у KVM. Но, разумеется, не без ложки дегтя. Взять и подключить блочное устройство к контейнеру «совсем красиво» (под этим я подразумеваю поддержку такой фичи в официальной поставке) нельзя, нужно его грамотно монтировать через спец-скрипты.
ploop — это loop девайс «нового поколения». Через некоторое время он (или почти он) появится в мейнстримном ядре. У него нет двойного кеширования, он поддерживает разные форматы дисков, есть возможность делать снапшоты.
А вот формат дисков — это уже другое. По понятным причинам OpenVZ использует формат, который используется для виртуальных машин в PCS. Этот формат по фичам и структуре аналогичен форматам используемым в KVM, т е ваше рассуждение о проблемах связанных с форматами в корне не верное. Проблемы в этом месте у всех одинаковые.
А вот формат дисков — это уже другое. По понятным причинам OpenVZ использует формат, который используется для виртуальных машин в PCS. Этот формат по фичам и структуре аналогичен форматам используемым в KVM, т е ваше рассуждение о проблемах связанных с форматами в корне не верное. Проблемы в этом месте у всех одинаковые.
А чем ploop будет отличаться от выброшенного в систему хоста с помощью qemu-nbd qcow2 образа по функциональности и производительности?
* будет быстрее, просто потому что nbd не очень быстро работает.
* qcow2 очень похож на формат ploop-а. Какая функциональность вам интересует. ploop формат поддерживает снапшоты, балунинг, умеет сжиматься, расширяться. Мог что-то забыть.
* qcow2 очень похож на формат ploop-а. Какая функциональность вам интересует. ploop формат поддерживает снапшоты, балунинг, умеет сжиматься, расширяться. Мог что-то забыть.
То есть, за исключением возможности эскпозиться в хост, что актуально только для чрутов/контейнеров, плуп не отличается от существующих форматов CoW? Ballooning подразумевает онлайн расширение-сжатие?
Да, подразумевает сжатие и расширение наживую. Но лишь для ext4, разумеется, используется обычный resize2fs.
Для ресайза вниз в онлайне вешаются хуки или это не возможно все же?
Через балун возможно. Балуном рулят снаружи (из хоста).
Мм, а как это согласуется с возможностями ext4? Понятно, что гостю можно послать нотифай об изменении геометрии, но обойти ограничения фс тривиально нельзя.
OpenVZ использует кастомное ядро. Балун — это файл на файловой системе, которые видно не всем. Ну и когда показывают статистику по файловой системе, берут во внимание размеры этого файла. Т е надули балун на 1Gb, объем файловой системы на 1Gb сократился. Это как KVM балун для памяти, только для диска.
Чет я не понял, о чем это ты. Есть расширение и сжатие через балун, а есть через средства файловой системы.
Еще одна opensource VM это Proxmox. вроде бы вполне интересная, если у когото был опыт интересно было бы почитать о минусах.
Proxmox – это оркестровка, под капотом там те же KVM и OpenVZ.
Да, у них используется почти стандартное OpenVZ ядро с openvz.org, которое в свою очередь само по себе отлично поддерживает и KVM и OpenVZ изоляцию. Proxmox добавляет веб-управление, некоторые драйверы и платную поддержку.
Но после перехода этого проекта в режим «платные обновления», он опять же выходит за рамки «свободного решения по виртулизации», хотя проект, безусловно, достойный.
Но после перехода этого проекта в режим «платные обновления», он опять же выходит за рамки «свободного решения по виртулизации», хотя проект, безусловно, достойный.
спасибо, не знал.
А как обстоят дела с живыми миграциями в мире LXC/OpenVZ, дело движется?
В lxc, вроде бы, пока ее не существует в чистом виде.
Но есть вот такой чудесный проект: criu.org/Main_Page с полной поддержкой со стороны Upstream ядра, который уже включен в 20ю Федору и почти промышленно стабилен. Он позволяет сериализовать/десериализовать любой Linux процесс.
А в OpenVZ живая миграция уже года 4, можете подробнее прочесть вот тут: openvz.org/Man/vzmigrate.8 А около года назад когда появился ploop, живая миграция в OpenVZ стала совсем-совсем-совсем крутой за счет ploop write tracker: openvz.livejournal.com/41835.html
Но есть вот такой чудесный проект: criu.org/Main_Page с полной поддержкой со стороны Upstream ядра, который уже включен в 20ю Федору и почти промышленно стабилен. Он позволяет сериализовать/десериализовать любой Linux процесс.
А в OpenVZ живая миграция уже года 4, можете подробнее прочесть вот тут: openvz.org/Man/vzmigrate.8 А около года назад когда появился ploop, живая миграция в OpenVZ стала совсем-совсем-совсем крутой за счет ploop write tracker: openvz.livejournal.com/41835.html
В OpenVZ живая миграция уже больше 4 лет. Разработчики давно хотели запушать ее в мейнстрим, но никак не могли найти правильного решения. Около двух лет назад это решение было найдено и родился проект CRIU. Буквально недавно вышла версия 1.0. Я писал несколько статей об этом проекте.
«любой Linux процесс» — группу процессов с сопутствующими объектами. Любые процессы не может, т к процесс может иметь внешние связи, которые просто так не восстановишь Прелесть контейнеров в том, что это фактические изолированная группа процессов.
«любой Linux процесс» — группу процессов с сопутствующими объектами. Любые процессы не может, т к процесс может иметь внешние связи, которые просто так не восстановишь Прелесть контейнеров в том, что это фактические изолированная группа процессов.
Спасибо за статью, очень интересно! Только не совсем понятно как контейнерный вариант будет соперничать! Я не спорю что действительно overhead маленький, больше ресурсов для клиентов, но, на мой взгляд подобное решение не совсем для промышленного сектора. VmWare к примеру может предоставить миграцию, FT, HA, тут же все реализовано в куче как я понял и таким образом будет страдать отказоустойчивость. К тому же вряд ли клиент, желающий получить свои мощности, захочет сидеть на одной оси с еще десятком. Но бесспорно решение интересное!
Спасибо за спасибо :) А OpenVZ умеет Live миграцию, а также недавно была доведена до стабильной фазы разработка фреймворка CRIU, который дает возможность сделать Live миграцию и на апстрим ядре, но пока в готовом виде ее нет.
FT, HA в свою очередь требуют поддержки со стороны системы хранения, в принципе HA «в лоб» реализуется доволньо просто силами централизованного хранилища + 2 рабочие машины с OpenVZ и keepalived.
Но, опять же, для контейнеров из ядра — этого пока нет.
FT, HA в свою очередь требуют поддержки со стороны системы хранения, в принципе HA «в лоб» реализуется доволньо просто силами централизованного хранилища + 2 рабочие машины с OpenVZ и keepalived.
Но, опять же, для контейнеров из ядра — этого пока нет.
FT тоже не для промышленного использования. Во всяком случае я не представляю себе рабочий сервер, достаточно важный для использования дорогущей фичи из дорогущего комплекта, но при этом чтоб ему хватало одного ядра. А все остальное можно делать и в контейнерах.
Если же смотреть на такие решения как опенстак, то там хоть HA и миграция в принципе бывают, подход к поддержанию ВМ (или контейнеров — не важно) на плаву там совсем другой. см. pets vs cattle in the cloud.
Если же смотреть на такие решения как опенстак, то там хоть HA и миграция в принципе бывают, подход к поддержанию ВМ (или контейнеров — не важно) на плаву там совсем другой. см. pets vs cattle in the cloud.
Ой, а уточните фразу «при этом чтоб ему хватало одного ядра». Честно говоря, не понял, почему одного ядро.
Текущая версия FT от VMware ограничена одним ЦП. Они обещают реализовать поддержку мультипроцессорных конфигураций уже на протяжении трёх лет, но дальше демок пока не продвинулись.
А, я думал вы про контейнеры. Тогда получается, что красивого HA толком ни у кого и нету-то…
HA есть практически у всех, а вот FT толкает только вмварь. в принципе это можно сделать и на KVM и на Xen (мы делали, эксперимента ради) но с ограничением в один процессор, плюс еще кучка не менее жестких рамок остается, и продавать такое просто нет смысла. FT на сегодня — чисто маркетинговая штука у вмварей, типа «смотрите как еще мы можем»
Там где нужно FT, чаще всего достаточно одного ядра. Обещание сделать поддержку мультипроцессорности, может быть вызовом придти и занести денег. Я думаю не для кого не секрет, что некоторые фичи делаются по заказу конкретных кастомеров или группы кастомеров.
Полценный FT мог бы стать хорошим конкурентным преимуществом, а пока заказчики используют Stratus.
> Там где нужно FT, чаще всего достаточно одного ядра
ой ли? а можно пример? а то пока что из примеров где FT таки нужен, и нельзя обойтись простым HA мне пришло в голову только про терминальные серверы. А они, с одним процессором, мало чего стОят
ой ли? а можно пример? а то пока что из примеров где FT таки нужен, и нельзя обойтись простым HA мне пришло в голову только про терминальные серверы. А они, с одним процессором, мало чего стОят
Вот сижу дума и на самом деле не понимаю, когда FT нужен не в real-time системе. Зачем оно на терминальном сервере? Если пользовательский ввод и чтоб пользователь не повторял свои действия с непонятной точки, то не ясно зачем тут больше 1 cpu.
> Зачем оно на терминальном сервере? Если пользовательский ввод и чтоб пользователь не повторял свои действия с непонятной точки, то не ясно зачем тут больше 1 cpu
потому что терминалы не кластеризуются, а с HA будет даунтайм и потеря сессии. А больше чем один CPU нужен потому что терминал с одним процессором не потянет кучу пользователей, а если он их не потянет, то зачем он нужен? с одним юзером это уже VDI
> Вот сижу дума и на самом деле не понимаю, когда FT нужен не в real-time системе
под рукой нет линков, но на vmworld 2012 был задан вопрос лектору, на одной из сессий по compute — когда они начнут поддерживать хоть какие нибудь RTOS. Oтвет был «никогда, виртуализация не для того»
потому что терминалы не кластеризуются, а с HA будет даунтайм и потеря сессии. А больше чем один CPU нужен потому что терминал с одним процессором не потянет кучу пользователей, а если он их не потянет, то зачем он нужен? с одним юзером это уже VDI
> Вот сижу дума и на самом деле не понимаю, когда FT нужен не в real-time системе
под рукой нет линков, но на vmworld 2012 был задан вопрос лектору, на одной из сессий по compute — когда они начнут поддерживать хоть какие нибудь RTOS. Oтвет был «никогда, виртуализация не для того»
Обрабатывать ввод юзеров и считать то что они попросили можно на разных серверах. Юзеров можно хендлить из нескольких вмок с одним процессором с FT. А на тех мощностях, где происходит реальная обработка запросов юзеров FT не нужен. Там можно делать итеративные снапшоты раз в несколько секунд и в случая сбоя восстанавливаться и проигрывать юзеровский ввод с определенной точки.
Контейнеры тоже предоставляют миграцию и HA. То что более оптимальная система, чаще оказывается сложнее, это обычное явление.
> К тому же вряд ли клиент, желающий получить свои мощности, захочет сидеть на одной оси с еще десятком.
Если эти оси друг на друга не влияют, то проблем никаких нет. С этой точки зрения контейнеры не сильно отличаются от виртуальных машин.
> К тому же вряд ли клиент, желающий получить свои мощности, захочет сидеть на одной оси с еще десятком.
Если эти оси друг на друга не влияют, то проблем никаких нет. С этой точки зрения контейнеры не сильно отличаются от виртуальных машин.
А как обстоят дела со стабильностью Windows-контейнеров? Или это не к вам вопрос?
Вы можете попробовать самостоятельно их: www.parallels.com/products/parallels-containers-windows/
Но это исключительно коммерческий закрытый продукт, так что какие-то особенности реализации можно найти разве что в технической сопроводительной документации.
Но это исключительно коммерческий закрытый продукт, так что какие-то особенности реализации можно найти разве что в технической сопроводительной документации.
Я ими не занимаюсь. Надо понимать особенность технологии. Если в Linux все открыто и разработчик всегда четко понимает, что он делает. То в Windows все закрыто и там приходится делать разные трюки.
Sign up to leave a comment.
Контейнеры — это будущее облаков