На прошлой неделе компания IBM подтвердила серьёзные намерения по развитию дата-майнинга, объявив о выпуске системы на Hadoop для хранения и анализа данных, а также о больших инвестициях в это направление. Разрабатывая софт на базе open source технологии, IBM официально гарантирует Hadoop свою защиту и покровительство.
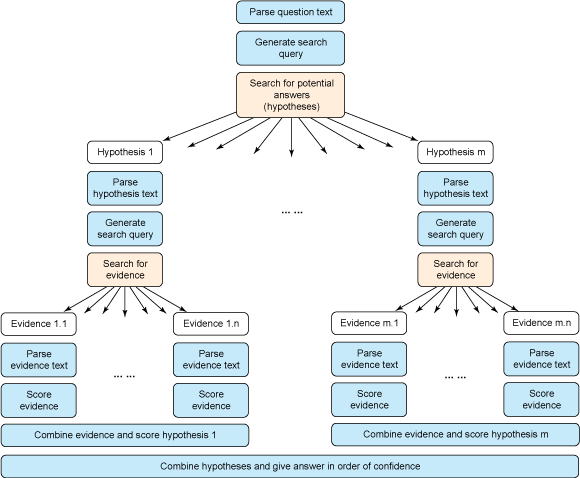
На другом фронте дата-майнинга IBM демонстрирует ещё более значительные успехи. Разработчики суперкомпьютера IBM Watson (который способен отвечать на вопросы, разбираясь в массиве неструктурированных данных) продолжают накачивать его БД медицинской информацией. По их словам, уже сейчас компьютер усвоил всю информацию, которую должен знать студент медицинского колледжа. И это только начало обучения.
Вполне возможно, что разработчиков IBM Watson вдохновляет сериал «Доктор Хаус». Из этого фильма широкие массы впервые смогли узнать, как работает врач-диагност. Мы видим, что его работа исключительно формальна и напоминает интеллектуальную головоломку, а ведь IBM Watson является чемпионом в интеллектуальном шоу Jeopardy — игре, где нужно быстро отвечать на вопросы (российским клоном является «Своя игра»). Компьютер гораздо лучше человека приспособлен для решения таких головоломок, потому что здесь требуется широкая эрудиция и очень глубокие познания. В то же время обыкновенные врачи отлично диагностируют часто встречающиеся болезни (список 100 самых распространённых диагнозов), но если встречается что-то необычное, то у врача обычно не хватает ни опыта, ни знаний.
Сейчас IBM Watson приспосабливают для ответа на вопросы вроде «Чем болен данный пациент с данным набором симптомов и данной историей болезни?», снабжая его всей необходимой информацией для этого. При постановке диагнозов IBM Watson использует тот же самый алгоритм ответов на вопросы, что и в игре Jeopardy.
Консультантом IBM в данном проекте является д-р Элиот Сигал (Eliot Siegal) из Мэрилендского университета. Он уже был свидетелем создания подобных программ для диагностики болезней в 70-е и 80-е годы, но все они были неудачными, пишет журнал Forbes.
Полтора года назад д-р Сигал помог программистам из IBM определить круг медицинских журналов и учебников, необходимых компьютеру для обучения на первое время, а также на какие вопросы его нужно учить отвечать для начала. Watson начал читать издания из национальной медицинской базы PubMed и десятки учебников. Вскоре он уже смог отвечать на вопросы на текстах и экзаменах, которые сдают студенты медицинского колледжа. Разумеется, ни один студент не смог бы усвоить такой же объём информации, поэтому IBM Watson здесь был вне конкурса.
Затем Watson начал пробовать решать известные клинико-патологические головоломки, которые публикуются в каждом номере журнала New England Journal of Medicine. Обучение происходит таким же образом, как на первом этапе, когда компьютер всё лучше и лучше отвечал на вопросы Jeopardy, пока не достиг чемпионского уровня среди людей. Так и здесь, точность диагнозов IBM Watson постепенно растёт.
Следующий этап обучения будет более сложным. В компьютер загрузят записи с историями болезней пациентов, так что Watson получит сведения о тех методах лечения, которые в реальности применялись на практике, и об их эффективности. Потом нужно пополнить его базу подробными массивами данных по отдельным болезням, например, по лейкемии — такие записи ведутся в медицинских институтах, которые специализируются на изучении той или иной болезни.
Хотя сейчас компьютеры широко используются в качестве справочных инструментов для постановки диагнозов, но IBM Watson — это система совершенно иного уровня. В перспективе IBM Watson должен стать идеальным врачом-диагностом, который путём анализа симптомов и истории болезни пациента способен поставить диагноз и назначить самое вероятное лечение.
По прогнозу разработчиков, через три-пять лет Watson будет готов для первых пилотных тестов по лечению реальных пациентов, а через 8–10 лет эти компьютеры могут найти широкое применение в больницах в качестве диагностического инструмента.
Дополнительную информацию о применении IBM Watson в медицине и дополнительную литературу можно найти здесь.
На другом фронте дата-майнинга IBM демонстрирует ещё более значительные успехи. Разработчики суперкомпьютера IBM Watson (который способен отвечать на вопросы, разбираясь в массиве неструктурированных данных) продолжают накачивать его БД медицинской информацией. По их словам, уже сейчас компьютер усвоил всю информацию, которую должен знать студент медицинского колледжа. И это только начало обучения.
Вполне возможно, что разработчиков IBM Watson вдохновляет сериал «Доктор Хаус». Из этого фильма широкие массы впервые смогли узнать, как работает врач-диагност. Мы видим, что его работа исключительно формальна и напоминает интеллектуальную головоломку, а ведь IBM Watson является чемпионом в интеллектуальном шоу Jeopardy — игре, где нужно быстро отвечать на вопросы (российским клоном является «Своя игра»). Компьютер гораздо лучше человека приспособлен для решения таких головоломок, потому что здесь требуется широкая эрудиция и очень глубокие познания. В то же время обыкновенные врачи отлично диагностируют часто встречающиеся болезни (список 100 самых распространённых диагнозов), но если встречается что-то необычное, то у врача обычно не хватает ни опыта, ни знаний.
Сейчас IBM Watson приспосабливают для ответа на вопросы вроде «Чем болен данный пациент с данным набором симптомов и данной историей болезни?», снабжая его всей необходимой информацией для этого. При постановке диагнозов IBM Watson использует тот же самый алгоритм ответов на вопросы, что и в игре Jeopardy.
Консультантом IBM в данном проекте является д-р Элиот Сигал (Eliot Siegal) из Мэрилендского университета. Он уже был свидетелем создания подобных программ для диагностики болезней в 70-е и 80-е годы, но все они были неудачными, пишет журнал Forbes.
Полтора года назад д-р Сигал помог программистам из IBM определить круг медицинских журналов и учебников, необходимых компьютеру для обучения на первое время, а также на какие вопросы его нужно учить отвечать для начала. Watson начал читать издания из национальной медицинской базы PubMed и десятки учебников. Вскоре он уже смог отвечать на вопросы на текстах и экзаменах, которые сдают студенты медицинского колледжа. Разумеется, ни один студент не смог бы усвоить такой же объём информации, поэтому IBM Watson здесь был вне конкурса.
Затем Watson начал пробовать решать известные клинико-патологические головоломки, которые публикуются в каждом номере журнала New England Journal of Medicine. Обучение происходит таким же образом, как на первом этапе, когда компьютер всё лучше и лучше отвечал на вопросы Jeopardy, пока не достиг чемпионского уровня среди людей. Так и здесь, точность диагнозов IBM Watson постепенно растёт.
Следующий этап обучения будет более сложным. В компьютер загрузят записи с историями болезней пациентов, так что Watson получит сведения о тех методах лечения, которые в реальности применялись на практике, и об их эффективности. Потом нужно пополнить его базу подробными массивами данных по отдельным болезням, например, по лейкемии — такие записи ведутся в медицинских институтах, которые специализируются на изучении той или иной болезни.
Хотя сейчас компьютеры широко используются в качестве справочных инструментов для постановки диагнозов, но IBM Watson — это система совершенно иного уровня. В перспективе IBM Watson должен стать идеальным врачом-диагностом, который путём анализа симптомов и истории болезни пациента способен поставить диагноз и назначить самое вероятное лечение.
По прогнозу разработчиков, через три-пять лет Watson будет готов для первых пилотных тестов по лечению реальных пациентов, а через 8–10 лет эти компьютеры могут найти широкое применение в больницах в качестве диагностического инструмента.
Дополнительную информацию о применении IBM Watson в медицине и дополнительную литературу можно найти здесь.
