 Наглухо застряв в пробке за рулем машины, теоретически способной развивать скорость более 200 км\ч, и глядя, как меня обгоняют велосипедисты
Наглухо застряв в пробке за рулем машины, теоретически способной развивать скорость более 200 км\ч, и глядя, как меня обгоняют велосипедисты Теперь вернемся к CPU. Заменим «топливо» на «электричество», а «скорость» на «производительность», и получим полную аналогию поведения Inel Atom и Intel Core. Но тогда разумно предположить, что существуют такие «пробки»и «закоулки», в которых Atom обгонит Core. Давайте их поищем.
Итак, по всем общепринятым замерам производительности Intel Core существенно обгоняет Atom. В разделе «Производительность» статьи про Intel Atom в wikipedia читается суровый приговор: "примерно половина производительности процессора Pentium M той же частоты"
Если же сравнивать Atom именно с Core, то по данным тестов tomshardware Intel Core i3-530 побеждает Intel Atom D510 с разгромным счетом:
| 3DS MAX 2010 (рендеринг) | Core i3 быстрее в 4.36 раз |
| Adobe Acrobat 9 (создание pdf). | Core i3 быстрее в 4.55 раз |
| Photoshop CS4 (применение ряда фильтров) | Core i3 быстрее в 3.8 раз |

При этом, надо отметить, что tomshardware к Atom относится явно предвзято. Так, например, если время работы какой-то задачи на Core-i3 — 1:38, то именно так об этом и сообщается — «одна минута, 38 секунд». А если Atom исполняет что-то за 7:26, то это, по мнению авторов «около восьми минут». Но главное — сравнивать процессоры с разной тактовой частотой (2.93 GHz Core i3 и 1.66 GHz Atom ) и не делать поправку
Почему Atom медленнее?
Быстрый ответ: потому что дешевле и энергоэкономичнее, что несовместимо с высокой производительностью.
Правильный ответ: Во-первых, потому, что у Atom сохранилась шина FSB, в то время как Core i3 имеет интегрированный в CPU контроллер памяти, что ускоряет доступ к данным. Кроме того, у Atom в четыре раза меньше размер кэш-памяти, а если данные не умещаются в кэш, то более медленный доступ к памяти сказывается на производительности по полной программе.
А во-вторых, микроархитектура Atom — это не Core2, использованная в Core i3, а Bonnell. Вкратце, Bonnell -продолжатель идей Pentium, в нем имеется только 2 целочисленных ALU (против трех в Core), а главное, отсутствуют присущие Core изменение порядка инструкций (instruction reordering), переименование регистров (register renaming), а также спекулятивное исполнение (speculative execution).
Откуда понятно, что чтобы помочь Atom обогнать Core, надо:
- Взять
нанонаборнебольшой набор данных, так, чтобы он помещался в кэш. - Попробовать использовать float данные, чтобы загружать не ALU, a FPU
- По возможности, лишить Core преимуществ неупорядоченного исполнения.
Поскольку с первыми двумя пунктами все ясно, можно запустить первые тесты.
Они проводились на имеющемся у меня Intel Core i5 2.53 GHz и уже упомянутом Atom D510, и представляли собой набор вызовов математических функций для float данных со встроенной оценкой производительности «количество функций в секунду», т.е. чем больше — тем лучше.
Тесты включали расчет тригонометрических функций как напрямую (C runtime, тест «x87»), так и разложением в ряд; с использованием кода мат.библиотеки Cephes; а также векторную реализацию через SSE intrinsic функции (тесты с окончанием _ps). При этом, учитывая разницу тактовых частот, результаты масштабировались на 2.53/1.66~1.524
Тесты компилировались Microsoft Visual Studio 2008 с оптимизацией в release по умолчанию.
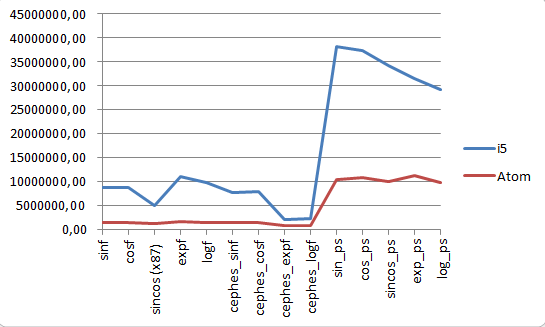
Полученные данные полностью подтверждают первое место Intel Atom с конца. То есть, цель не достигнута, переходим к следующему пункту — осложним работу Out-of-order CPU.
Усложняем задачу
Создадим искусственный тест, который будет содержать непредсказуемые ветвления, содержащие вычислительно тяжелые функции, так, чтобы результат спекулятивных вычислений Core постоянно отбрасывался, т.е. оказывался ненужной работой.
Примерно так:
int rnd= rand()/(RAND_MAX + 1.) * 3;
if (rnd%3==0) fn0();
if (rnd%3==1) fn1();
if (rnd%3==2) fn2();
Более того, функции будут состоять из цепочечных вычислений, так чтобы Core не мог путем переупорядочивания инструкций и переименования регистров посчитать что-то из таких выражений заранее, «вне очереди». Вот простейший пример подобного кода
for (i=0; i < N; ++i) {
y+=((x[i]*x[i]+ A)/B[i]*x[i]+C[i])*D[i];
}Кстати, подобные функции и использованы в вышепоказанных тестах cephes_logf и cephes_expf, где преимущество Core минимально.
Но, несмотря на все препятствия, Core все равно оказался быстрее. Минимальный отрыв Core от Atom, который мне удалось получить различными комбинациями вычислений и случайностей — в целых два раза! То есть, Atom по-прежнему отстает.
Но если бы я на этом остановилась, то вы бы про это просто не узнали — пост бы не состоялся.
Следующим шагом была компиляция тестов с помощью Intel Compiler. Использовалась версия Composer XE 2011 update 9 (12.1) c настройками оптимизации Release по умолчанию — аналогично компилятору Microsoft.
На графике ниже приведены результаты работы вышеупомянутых тестов, включая добавленный мной rand, скомпилированные как VS2008, так и Intel Compiler.

Смотрите внимательно. Это — не обман зрения. Для четырех тестов точки зеленой линии, показывающие результат Atom для тестов, скомпилированных Intel Compiler, находится выше, чем точки бордовой — результат i5 для тестов, скомпилированных VS2008. То есть, Atom оказывается реально, более чем в два раза, быстрее на _том же коде_, что и Core i5.
Думаете, что это реклама компилятора Intel?
Абсолютно нет. Я не работаю ни в отделе рекламы, ни в компиляторной группе.
Это просто констатация того, что ваш оптимизированный код может выполняться на Atom гораздо быстрее, чем неоптимизированный на Core. Или — неоптимизированный на Core будет медленнее, чем оптимизированный на Atom.
Это — как раз те самые кочки и закоулки, которые мешают машине разогнаться.
Выводы можете сделать сами.
