
Пакет Intel Parallel Studio XE давно известен разработчикам, в том числе и по публикациям в блоге Intel на Хабре. Недавно вышло обновление - Intel Parallel Studio XE 2013 Service Pack 1 (SP1), имеющее ряд интересных новшеств. Становится проще программировать для со-процессоров и встроенной графики, во многом благодаря поддержке стандарта OpenMP 4.0 (частичной). Поиск ошибок стал гибче, утечки памяти теперь обнаруживаются до завершения процесса, т.е. их можно искать в долгоиграющих сервисах и «падающих» приложениях. Найти узкие места в производительности будет легче благодаря новому представлению дерева вызовов, оценке накладных расходов и детальной информации о параллельных конструкциях.
Intel Composer XE объединяет в себе С/С++ и Fortran компиляторы, многопоточные, математические и другие библиотеки. В Intel Composer XE 2013 SP1 появилось много улучшений, здесь остановимся на возможностях векторизации и использования со-процессоров и акселераторов, появившихся в стандарте OpenMP* 4.0.
Конструкция OpenMP* SIMD
Использование SIMD (Single Instruction Multiple Data) инструкций, или векторизация, позволяют реализовывать параллелизм по данным. Это один из наиболее эффективных способов оптимизации производительности ПО. Компилятор Intel делает всё возможное, чтобы векторизовать код автоматически, но это не всегда возможно, если, например, он подозревает возможность наличия зависимостей. Стандарт OpenMP 4.0 позволяет явно сообщить компилятору, что зависимостей нет и векторизовать можно, с помощью конструкции “#pragma omp simd” (есть аналог и для Fortran). Если перед циклом стоит “omp simd”, компилятор должен генерировать векторные инструкции, которые смогут обрабатывать одновременно по несколько итераций. Можно использовать дополнительные конструкции, например для «редукции»:
double pi()
{
double pi = 0.0;
double t;
#pragma omp simd private(t) reduction(+:pi)
for (i=0; i<count; i++) {
t = (double)((i+0.5)/count);
pi += 4.0/(1.0+t*t);
}
pi /= count
return pi;
}
Можно определить «поэлементные» SIMD функции, в которых разработчик описывает операции, производимые над отдельными элементами данных. Компилятор при этом знает, что функция может безопасно использоваться в SIMD цикле. Для определения SIMD функции используется конструкция “omp declare”:
#pragma omp declare simd notinbranch
float min(float a, float b) {
return a < b ? a : b;
}
#pragma omp declare simd notinbrach
float distsq(float x, float y) {
return (x - y) * (x - y);
}
Такие вещи позволяют вам комбинировать параллелизм по данным (SIMD) внутри одного ядра, и параллелизм по потокам или задачам, работающим на нескольких ядрах. Следующий цикл сначала векторизован, затем оставшееся количество итераций может выполняться разными потоками:
#pragma omp parallel for simd
for (i=0; i<N; i++)
d[i] = min(distsq(a[i], b[i]), c[i]);
Использование со-процессора
Акселераторы и со-процессоры, такие как Intel Xeon Phi, набирают популярность. В OpenMP 4.0 вы можете отправлять вычисления (которые хорошо параллелятся) на со-процессор, используя “omp target”. Эта конструкция запускает идущий за ней блок кода на акселераторе. Если его нет или он не поддерживается, код отработает на CPU в обычном режиме. Конструкция “map” позволяет организовывать данные, отправляемые на со-процессор:
#pragma omp target map(to(b:count)) map(to(c,d)) map(from(a:count))
{
#pragma omp parallel for
for (i=0; i<count; i++)
a[i] = b[i] * c + d;
}
Intel Advisor XE моделирует параллельное исполнение последовательного кода. Он используется для прототипирования параллельных алгоритмов, давая архитекторам возможность быстро поэкспериментировать с разными вариантами дизайна, до того, как будут потрачены значительные ресурсы на реализацию. Результатом является предсказание ускорения исполнения программы и масштабируемости, а также указание на гонки данных, которые могут появиться в параллельной версии.
Расширенный анализ ускорения и масштабируемости
Ранее оценка масштабируемости делалась от 2 до 32 ядер. Этого было обычно достаточно для CPU, но не для со-процессора Intel Xeon Phi, имеющего больше 240 аппаратных потоков. Новая версия Advisor XE делает оценку масштабируемости алгоритма на неограниченное число ядер. На картинке внизу показан пример с 512 ядрами. Теперь вы можете оценить, насколько ваш алгоритм готов к портированию на Intel Xeon Phi с точки зрения количества потоков (ещё надо оценить “векторизуемость” кода, ограничения памяти и т.д., чего Advisor XE пока не делает).
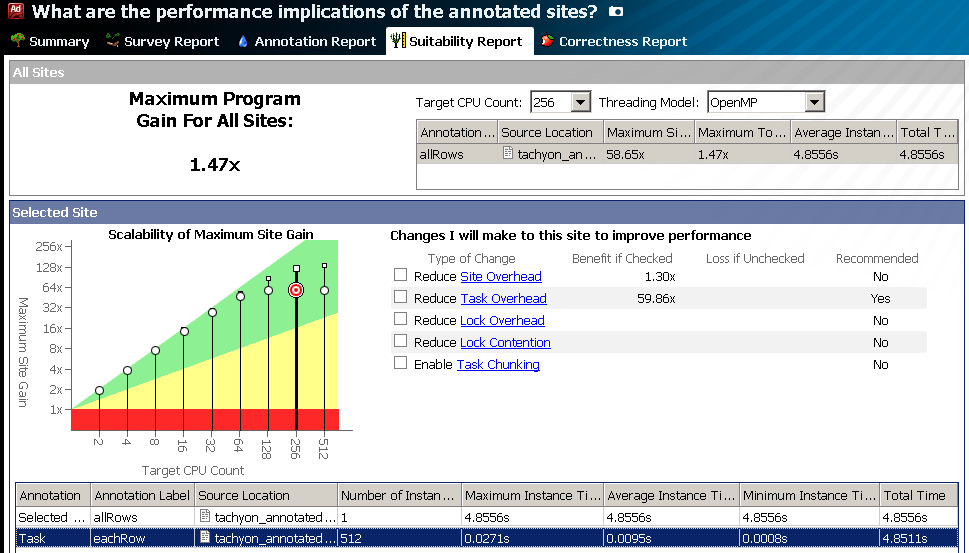
Копия эксперимента (experiment snapshot)
Пользователи Inspector XE и VTune Amplifier XE имеют возможность делать множество тестов и хранить все результаты, отслеживая изменения в производительности и состояние проблем. Advisor XE до недавнего времени был лишён такой возможности – хранился результат лишь последнего эксперимента, в силу сложности структуры профиля и его тесной связи с текущей версией кода.
Intel Advisor XE 2013 update 4, поставляющийся с Parallel Studio XE 2013 SP1, имеет возможность делать копию эксперимента (snapshot). Эта копия только для чтения, но она позволяет посмотреть, каковы были оценки производительности на более ранних версиях кода, и сравнить их с нынешней:
Анализ отдельных участков кода
Анализ Advisor XE может привносить значительные накладные расходы, т.к. проводится сложное моделирование параллельного исполнения «в реальном времени». Чтобы сэкономить время, теперь можно отметить отдельные участки кода, которые нужно проанализировать. Кроме того, такое «сужение» может повысить точность анализа за счёт устранения влияния других частей программы. Всё это реализуется новыми типами «аннотаций»: ANNOTATE_DISABLE_COLLECTION_PUSH и ANNOTATE_DISABLE_COLLECTION_POP (есть и кнопки для ручного контроля):
int main(int argc, char* argv[])
{
ANNOTATE_DISABLE_COLLECTION_PUSH
// Do initialization work here
ANNOTATE_DISABLE_COLLECTION_POP
// Do interesting work here
ANNOTATE_DISABLE_COLLECTION_PUSH
// Do finalization work here
ANNOTATE_DISABLE_COLLECTION_POP
return 0;
}
Intel Inspector XE — отладчик памяти и потоков, проводит динамический анализ во время исполнения приложения и может интегрироваться со стандартными отладчиками. Он может найти ошибки работы с памятью, такие как утечки, некорректный доступ к памяти и т.д., и ошибки работы с потоками – взаимные блокировки, гонки данных и другие. Такие проблемы могут быть упущены обычным функциональным тестированием или статическим анализом кода.
Импортирование правил подавления Valgrind* и Rational Purify*
В Inspector XE есть возможность подавлять отдельные проблемы или группы проблем, которые не интересуют разработчика. Например, проблемы в чужих модулях или ложные срабатывания. Схожая функциональность есть и в других инструментах. Правила подавления в больших проектах хранятся в отдельных файлах, определяющих место в коде, модуль, тип проблемы и другую информацию.
Новая версия Inspector XE – update 7 имеет возможность импортировать файлы с правилами подавления, сгенерированные другими инструментами — Valgrind и Rational Purify. Эти файлы конвертируются в формат Inspector XE. Это упрощает переход на Inspector XE с других инструментов, сохраняя время и прошлые вложения в формирование базы правил подавления.
Кроме того, правила подавления Inspector XE теперь хранятся в текстовом виде, и их можно редактировать вручную.
Поиск утечек памяти до завершения приложения
Обнаружение утечек памяти – одна из наиболее популярных возможностей анализа проблем памяти в Inspector XE. В предыдущих версиях для обнаружения утечки было необходимо, чтобы программа отработала от начала и до конца, чтобы Inspector XE смог отследить все выделения и освобождения памяти. Это не всегда удобно, если, например, приложение работает долго, или вообще «вечно», как демон или сервис. Кроме того, если программа завершается некорректно, «падает», отследить утечки таким образом тоже не получится.
В новой версии Inspector XE программист может отметить регион кода, в котором надо искать утечки памяти. Ограничить такой регион можно специальными API в исходном коде. Можно вызывать отчёт об обнаруженных к текущему моменту утечках кнопками в графическом интерфейсе и командами в командной строке.
Т.е. можно искать утечки в отдельно взятом участке кода, и узнавать о них, не дожидаясь завершения процесса.
Intel VTune Amplifier XE – профилировщик производительности. Он показывает наиболее затратные с точки зрения ресурсов CPU участки вашего приложения с различной гранулярностью – по потокам, модулям, функциям, инструкциям и т.д. Инструмент предоставляет информацию о балансе нагрузки между потоками, времени ожидания и объектах синхронизации, вызывающих эти ожидания. VTune Amplifier XE позволяет обнаружить микроархитектурные проблемы производительности, такие как промахи кэша, «false sharing» и многие другие.
Детальный отчёт о накладных расходах
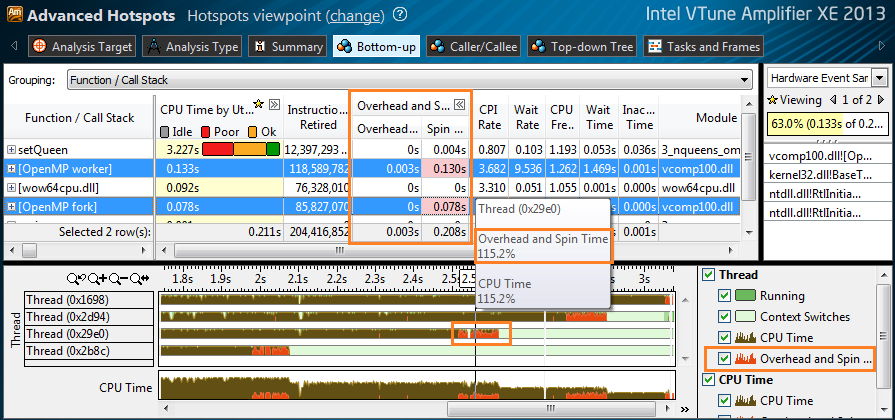
В многопоточной программе часть времени CPU неизбежно тратится на синхронизацию потоков, распределение работы между ними и т.д. Это время, потраченное не на основные вычисления, называют накладными расходами или «оверхедом». Эти накладные расходы нужно минимизировать для улучшения производительности. VTune Amplifier XE может теперь давать детальную информацию о накладных расходах и активном ожидании (spin waiting). Вы можете оценить, какая доля процессорного времени потрачена на накладные расходы в конкретной функции, модуле или инструкции. Инструмент может показывать «оверхед», исходящий из OpenMP, Intel Threading Building Blocks или Intel Cilk Plus. Вы можете использовать как значения времени в таблице, так и графическое представление на временной шкале:
Улучшения анализа OpenMP* приложений
Новый VTune Amplifier XE получил расширенные возможности анализа регионов OpenMP. Группировка по “Frame Domain” в панели Bottom-up показывает регионы OpenMP как фреймы – см. картинку ниже. Используя фильтры, вы можете сузить профиль производительности до отдельного параллельного региона, оценить, сколько там было потрачено времени, каков был баланс нагрузки и т.д. Строка “[No frame domain — Outside any frame]” представляет последовательную часть вашей программы, так что вы сможете оценить степень «параллельности» кода (вспомним закон Амдала).
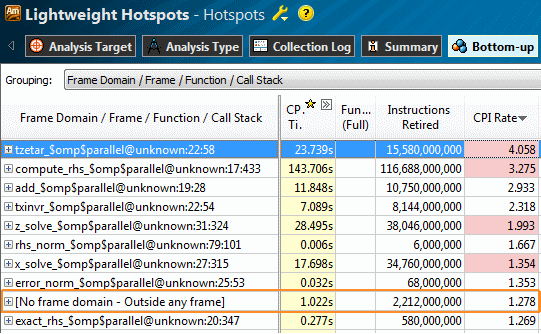
Накладные расходы и время активного ожидания, относящиеся к OpenMP, определяются не только для Intel OpenMP, но и для GCC* и Microsoft OpenMP*. На картинке выше (анализ Advanced Hotspots) “[OpenMP worker]” и “[OpenMP for]” относятся к библиотеке Microsoft OpenMP* – модуль vcomp100.dll.
Просмотр исходного кода и ассемблера из командной строки
В некоторых случаях командной строкой пользоваться удобнее, чем графическим интерфейсом. Например, когда вы работаете на удалённом Linux сервере через SSH. Теперь вы можете смотреть исходники в профиле VTune Amplifier XE прямо из командной строки. Так вам может не потребоваться копировать результаты профилировки с удалённой машины или конфигурировать VNC – можете быстро взглянуть на профиль из того же командного интерпретатора, из которого запускали сбор данных:
# amplxe-cl -report hotspots -source-object function=grid_intersect -r r000hs/
Source Line Source CPU Time:Self
----------- ------------------------------------------------------------ -------------
460 return 1;
461 }
462
463
464 /* the real thing */
465 static void grid_intersect(grid * g, ray * ry) 0.036
466 {
467
468
469 flt tnear, tfar, offset;
470 vector curpos, tmax, tdelta, pdeltaX, pdeltaY, pdeltaZ, nXp, nYp, nZp;
471 gridindex curvox, step, out;
472 int voxindex;
473 objectlist * cur;
474
475 if (ry->flags & RT_RAY_FINISHED)
476 return;
477
478 if (!grid_bounds_intersect(g, ry, &tnear, &tfar))
479 return;
480
481 if (ry->maxdist < tnear) 0.020
Анализ дерева вызовов Caller/Callee
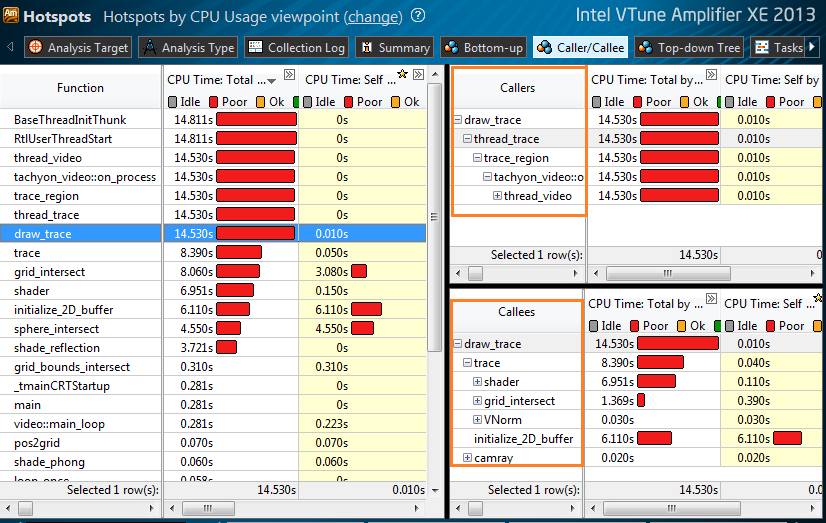
Новая вкладка Caller/Callee соединяет в себе лучшее от Bottom-up и Top-down. Там показаны собственное время исполнения каждой функции и полное время, с учётом вызываемых функций. Для выделенной функции в верхнем правом окне показаны её родители (Callers), а в нижнем правом – вызываемые функции (Callees). В окне Caller/Callee вы можете исследовать последовательности вызовов, и вклад каждого уровня в потребление CPU. Вы можете отфильтровать по полному времени любой функции и получить все деревья, имеющие эту функцию на каком-либо уровне. Так можно обнаружить наиболее критическую ветвь вызовов.
Профилирование GPU
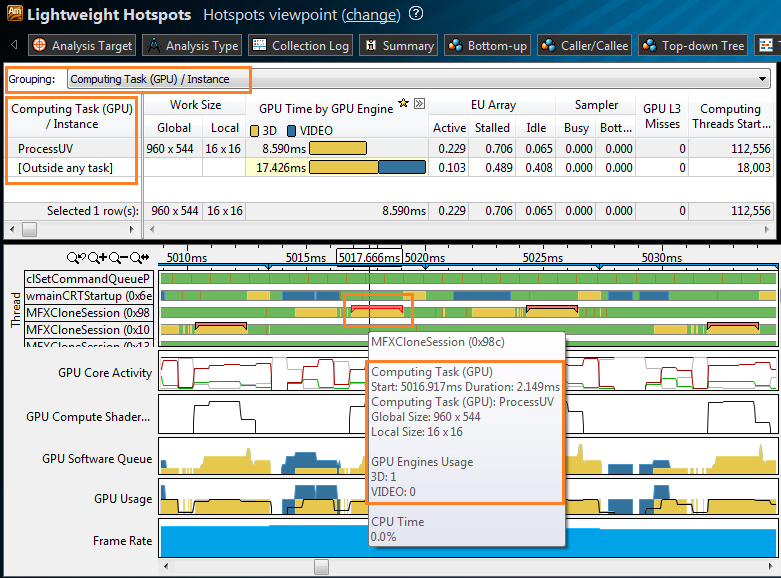
VTune Amplifier XE теперь может профилировать код, работающий на Intel Processor Graphics. Вы можете отслеживать общую активность GPU: используется ли оно для декодирования видео? Какие потоки CPU запускают GPU вычисления? Все ли ресурсы GPU используются? Эта возможность особенно интересна для вычислительных задач, работающих на GPU через OpenCL*. VTune Amplifier XE распознаёт OpenCL kernels (или computing task), можно увидеть размер работы и микроархитектурные проблемы, например промахи кэша L3. На временной шкале OpenCL kernels отмечены на CPU потоках, которые их запустили. Вы можете наблюдать состояние вычислительных ядер GPU (GPU Execution Units) с течением времени: active, idle или stalled. Имея данные о загрузке GPU, вы можете оценить, чем ограничена производительность программы: CPU или GPU, какие OpenCL kernels тратят больше ресурсов, где есть возможности для большей загрузки GPU и, соответственно, разгрузки CPU.
Анализ производительности «сверху вниз» на процессорах Intel Core четвёртого поколения
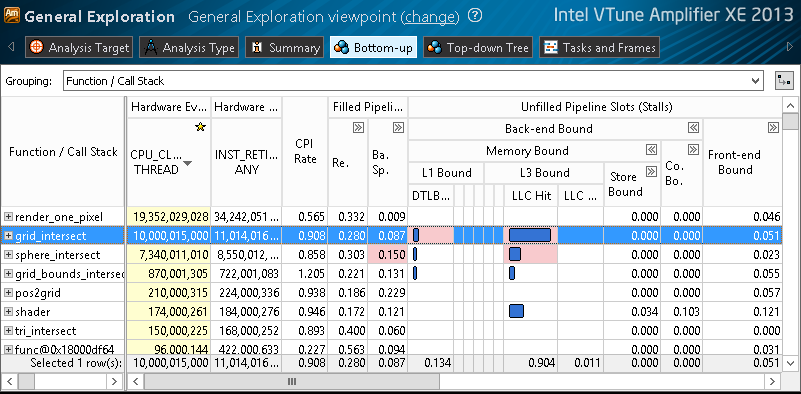
Исследование микроархитектурных проблем – задача нетривиальная. Требуется понимание микроархитектуры CPU и знание аппаратных событий, регистрирующих происходящее в процессоре. Для придания большей структурности и дружелюбности такому анализу, данные от аппаратных счётчиков в анализе General Exploration были сведены в более понятные метрики, и организованы «сверху вниз», или от общего к частному. Инструмент сам считает метрики для платформы, на которой собирались данные, и подсвечивает возможные проблемы, ограничивающие производительность. Иерархическое представление данных даёт возможность контролировать уровень детализации, навигация становится удобнее.
Резюме
Intel Parallel Studio XE 2013 SP1 даёт новые возможности эффективно программировать для со-процессоров, получать больше от параллельных моделей (таких как OpenMP), легче находить и исправлять сложные проблемы производительности на новых микроархитектурах, создавая отличные программные продукты. Качайте новую версию, проверьте, как новые функции могут улучшить ваш текущий проект.
