
Среди большого количества цикловых оптимизаций, одной из наиболее эффективных является техника разделения цикла на блоки (loop blocking). Суть её заключается в изменении итерационного пространства с целью более оптимальной работы с памятью, то есть уменьшения промахов кэша. Для этих целей в последней версии компилятора появилась специальная директива, позволяющая контролировать эту оптимизацию. Но обо всём по порядку.
Мы все знаем, что современные процессоры обладают кэшем – памятью с большой скоростью доступа, предназначенной для того, чтобы минимизировать доступ к ОЗУ. Расположена она между процессором и основной памятью и хранит копию части данных оперативной памяти:

Кэш-память делится на несколько уровней, причём каждый последующий уровень больше по размеру и медленнее по скорости доступа и передаче данных, чем предыдущий. Самый быстрый кэш первого уровня — L1, причем он разделён на два — кэш инструкций и кэш данных. А вот L2 кэш общий, а значит для каждого из ядер можно использовать необходимое количество памяти. Если использовать все ядра, кэш память разделяется на каждое из них динамически, в зависимости от нагрузки.
Доступ к памяти осуществляется процессором небольшими блоками, которые называют строками кэша, собственно, из них кэш и состоит. Обычно размер строки составляет 64 байта. При чтении любого значения из памяти, в кэш попадает как минимум одна строка кэша. Последующий доступ к какому-либо значению из этой строки происходит очень быстро. Переход на другую строчку занимает больше времени, ну а отсутствие данных во всём кэше приводит к очень серьёзным потерям в производительности, связанными с выгрузкой/загрузкой данных.
Таким образом, с точки зрения производительности, было бы идеально, чтобы весь наш массив помещался в кэш и доступ к его элементам производился по строкам.
Важно ещё сказать о таком понятие, как локальность данных. Обращения к памяти обладают временной и пространственной локальностью. Если происходит обращение к ячейке памяти, то с большой вероятностью эта ячейка памяти вскоре понадобится снова. Это временная локальность.
Под пространственной локальностью подразумевается, что при обращение к ячейке памяти с большой вероятностью будет произведено обращение к соседним ячейкам памяти.
Неспроста данные подгружаются не по одному байту, а кэш строками по 64. Обратившись к одному элементу массива в цикле, мы имеем сразу несколько следующих «наготове», и при условии последовательного доступа можем работать с ними максимально эффективно, реализуя пространственную локальность.
Временная локальность в циклах реализуется через использование одних и тех же данных для нескольких итераций цикла. Техника разделения цикла на блоки позволяет использовать временную локальность гарантируя, что если данные один раз загружены в кэш, то они не будут выгружены до тех пор, пока не будут использованы.
Теперь рассмотрим пример. Пусть у нас имеется некоторый цикл, работающий с массивами:
double A[MAX, MAX], B[MAX, MAX];
for (i=0; i< MAX; i++)
for (j=0; j< MAX; j++)
A[i,j] = A[i,j] + B[j, i];
На первой итерации при доступе к B[0, 0] будет подгружаться кэш линия, содержащая B[0, 0:7] (размер линии 64 байта, а каждый элемент по 8 байт). Так как во внутреннем цикле мы идем по индексу j для массива B, то каждый раз прыгаем на следующую строку, тем самым не попадая в строку кэша. При условии достаточно длиной строки A и из-за ограниченного размера кэша, эта строка будет вытеснена ещё до того момента, как внутренний цикл дойдёт до конца. Таким образом при доступе к любому элементу массива B мы имеем по промаху и повторного использования данных в кэше для B нет как явления.
Проблему можно решить, если работать с массивами блоками, попадающими в кэш.
for (i=0; i< MAX; i+=block_size)
for (j=0; j< MAX; j+=block_size)
for (ii=i; ii<i+block_size; ii++)
for (jj=j; jj<j+block_size; jj++)
A[ii,jj] = A[ii,jj] + B[jj, ii];
В этом случае массивы A и B подразбиваются на два прямоугольных блока таким образом, чтобы их сумма не превышала размер кэша:
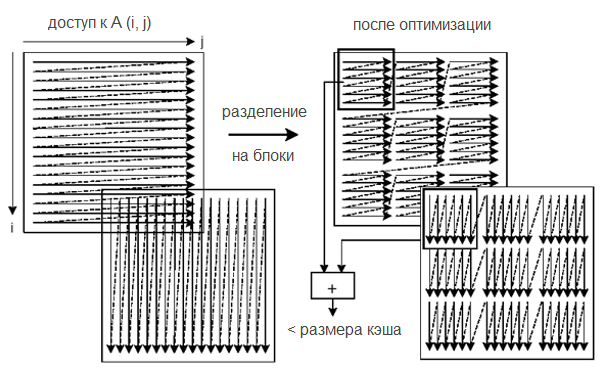
Например, если block_size равен 8, тогда каждый блок будет представлять из себя 8 кэш линий по 64 байта. При первой итерации внутреннего цикла, A[0, 0:7] и B[0, 0:7] попадут в кэш. В первой итерации внешнего цикла мы таки получим промах, но один раз вместо восьми.
Кстати если значение MAX в данном примере просто огромно, то с помощью этой техники мы так же сможем избежать накладных расходов, связанных с промахами в буфере ассоциативной трансляции (Translation lookaside buffer, TLB), который предназначен для ускорения трансляции адреса виртуальной памяти в адрес физической памяти. Кроме того, мы сможем сохранять пропускную способность внешней шины.
Пришло время собрать какой-то простенький код и показать эффективности техники.
#include <time.h>
#include <stdio.h>
#define MAX 8000
#define BS 16 //Block size is selected as the loop-blocking factor
void add(int a[][MAX], int b[][MAX]);
int main()
{
int i, j;
int A[MAX][MAX];
int B[MAX][MAX];
clock_t before, after;
//Initialize array
for (i=0; i<MAX; i++)
{
for(j=0;j<MAX; j++)
{
A[i][j]=j;
B[i][j]=j;
}
}
before = clock();
add(A, B);
add(A, B);
add(A, B);
add(A, B);
after = clock();
printf("\nTime taken to complete : %7.2lf secs\n", (float)(after - before)/ CLOCKS_PER_SEC);
}
Собственно, внутри add мы будем складывать массивы. Сначала без использования блоков:
void add(int a[][MAX], int b[][MAX])
{
int i, j;
for(i=0;i<MAX;i++)
for(j=0; j<MAX;j++)
a[i][j] = a[i][j] + b[j][i];
}
И с помощью разделения на блоки:
void add(int a[][MAX], int b[][MAX])
{
int i, j, ii, jj;
for(i=0; i<MAX; i+=BS)
for(j=0; j<MAX; j+=BS)
for(ii=i; ii<i+BS; ii++)
for(jj=j; jj<j+BS; jj++) //outer loop
//Array B experiences one cache miss for every iteration of outer loop
a[ii][jj] = a[ii][jj] + b[jj][ii];
}
Собираем это дело с достаточным размером стэка:
icl /Qoption,link,"/STACK:1000000000" test.cpp
Время, потраченное на выполнение обычной версии составило 4.67 секунды против 1.13 с “блокированием”. Более чем внушительный выигрыш.
А теперь то, ради чего я начал рассказывать про loop blocking. В последней версии компилятора появилась директива, способная облегчить жизнь и избавить нас от необходимости бить на блоки ручками. Это директива block_loop:
С/С++:
#pragma block_loop [clause[,clause]...]
#pragma noblock_loop
Фортран:
!DIR$ BLOCK_LOOP [clause[[,] clause]...]
!DIR$ NOBLOCK_LOOP
Через параметры можно контролировать размер блоков (factor) и уровень вложенности цикла(level), для которого делать оптимизацию (от 1 до 8). Если ничего не указать, то по умолчанию будут вычисляться нужные размеры блоков для вашего процессора. Для каждого цикла можно задать свой размер блока. Например:
#pragma block_loop factor(256) level(1)
#pragma block_loop factor(512) level(2)
Задает размер блока равный 256 для внешнего цикла и 512 для внутреннего (если у нас вложенный двойной цикл). Рассмотрим такой пример:
#pragma block_loop factor(256) level(1:2)
for(j=1; j<n ; j++){
f = 0;
for(i=1; i<n; i++){
f = f + a[i] * b[i];
}
c[j] = c[j] + f;
}
В этом случае директива преобразует наш код таким образом:
for(jj=1 ; jj<n/256+1; jj+){
for(ii=1; ii<n/256+1; ii++){
for(j=(jj-1)*256+1; j<min(jj*256, n); j++){
f = 0;
for (i=(ii-1)*256+1; i<min(ii*256,n); i++){
f = f + a[i] * b[i];
}
c[j] = c[j] + f;
}
}
}
Теперь вернёмся к примеру, для которого я запускал тесты, и модифицируем функцию add, добавив директиву #pragma block_loop. Пересобрав код с теми же опциями, я получил совсем неожиданный результат. Ничего в скорости выполнения приложения не изменилось. А всё дело в дефолтной опции O2, при которой компилятор не выполняет ряд цикловых оптимизаций, в том числе и разделение цикла на блоки. Для работы директивы нужно задать самый высокий уровень оптимизации O3:
icl /O3 /Qoption,link,"/STACK:1000000000" test.cpp
На выходе я получил 0.83 секунды, что даёт прирост по сравнению с тем, что я делал ручками. На самом деле там я не подбирал размер блоков идеально, а просто показывал технику, поэтому пространство для роста вполне оставалось. Кстати, чтобы убедиться в необходимости этой директивы, я пересобрал с O3 без неё. Как и ожидалось, производительность не улучшилась, и я видел те же грустные 4.69 на выходе.
Мне кажется, данная директива будет весьма полезна, учитывая магический эффект, который она даёт. Отмечу ещё что на данный момент она доступна в бета версии 16.0, релиз которого уже не за горами. Всем пробовать!
