Comments 39
Большое спасибо за Вашу статью. В принципе, данные по фундаментальным показателям компаний за предыдущие кварталы есть и на finance.yahoo.com, совершенно бесплатно. Также там есть и исторические курсы (конечно не от сотворения мира, но для Эппла с конца 1980 года), есть и API (см. stackoverflow). Впечатляют и Ваши финансовые показатели, правда 51 сделка за 30 дней это ведь больше двух сделок в день, слишком интенсивно для многих.
Я как то с яху по пробной подписке скачал все доступные данные для росс компаний и стал наугад сравнивать с данными по финансовым отчётностям, которые выложены на сайтах компаний за разные года. И к своему удивлению обнаружил, что на Яху данные не совпадали в некоторых местах с отчетностью. Разница казалась не такой значимой, но для некоторых показателей для расчёта value это может быть очень чувствительным
Рынки могут падать полгода, год и больше. Причем не обязательно резко. В таких условиях данная ТС наврядли сможет дать положительное мат.ожидание.
Мне кажется, что автор пытается переизобрести факторное инвестирование, а именно фактор «стоимости» HML Фамы и Френча. Даже вопрос, который задаёт автор — как быть, если отношение P/E не определено при E=0 — очень похож на мысли классиков. Они, кстати, решили в качестве индикатора брать отношение book/market, то есть акционерного капитала по отчётности к рыночной капитализации. Выяснилось, что на длинной дистанции компании «стоимости» (высокое B/M и скорее всего низкое P/E) в среднем обгоняют компании «роста» (низкое B/M и скорее всего высокое P/E). Поэтому сама идея проводить скрининг акций по этому или другим похожим мультипликаторам, что называется, напрашивается.
Проблем тут две. Во-первых, ставка на стоимость работает далеко не всегда. За последние 20 лет фактор HML на рынке США заработал примерно ноль, то есть выбор акций по критерию «стоимости» не помогал обогнать рынок. Во-вторых, ставка на фактор HML (или на любой другой) — это в чистом виде ставка на систематический риск, за который на дистанции вы зарабатываете премию за риск. Хорошо бы понимать, как именно вы отличаетесь от среднего инвестора на рынке, и почему именно вы готовы взять на себя систематический риск компаний «стоимости», а остальные — нет.
Я не против факторного инвестирования как такового. Но я уверен, что выбор отдельных акций — точно не то, чем стоит заниматься. Лучше инвестировать в индексный фонд, основанный на нужном факторе. Например, найдите ETF, который отбирает акции по критерию value, и инвестируйте в него. Диверсификация — единственный бесплатный обед на рынке.
Я думаю, что автор существенно улучшит свои будущие результаты, если познакомится с тем, что финансисты-академики успели написать про фондовый рынок с 1960-х годов. В моём профиле есть серия статей о теории инвестиций для начинающих. Уверен, что специалист по ML проглотит их за пару часов без малейших затруднений. Комбинация ML и здравого смысла это хорошо, но комбинация ML, здравого смысла и финансовой теории — ещё лучше.
В случае когда берешь акции в долгий срок, нейросети не особо нужны, можно самому быстро изучить рынок, утилит для этого достаточно уже.
Присоединяюсь к сказанному выше abak. От себя хочется позанудствовать что работа с такой моделью не имеет смысла без бенчмарка, что для портфеля акций обычно — биржевой индекс. Если автор попробует свои модели на исторических данных (раньше это было удобно делать на Quantopian, сейчас не знаю), то он может обнаружить что чуда не случилось.
Отлично с точки зрения подхода ML к оценке компании, очень интересно и сам хочу реализовать нечто подобное, но пока что в процессе сбора данных по отчетности росс. компании. Как закончу, напишу обязательно статью. Имея финансовое образование, хочу заметить, что ваша модель оценки капитализации не учитывает те факторы, которые учитываются финансовыми фондами для оценки value, от сюда может быть сильный разбег между спрогнозированной оценкой и рыночной. А такого разбега быть не может, потому что фонды вкладывают огромные усилия в стоимостную оценку, в тч применяя методы ml и огромные гэпы уже давно были бы закрыты. Основа оценки компании это DCF модель, а там недостаточно знать текущую выручку, ее надо экстраполировать на будущие периоды, а затем дисконтировать. Ставка дисконтирования очень сильно влияет на стоимость компании и вы ее никак не учитываете, на сколько я понял (в этом может крыться сильный гэп в стоимостной оценке). Но, что хорошо, ее можно довольно легко определить с помощью WACC. Найдите сайт Damodaran, там будут исторические исходные данные для расчета wacc. Если интересно, могу вас проконсультировать по оценке
Ставка фрс это только один компонент ставки дисконтирования, по отраслям бетта отличается + каждая компания разная по риску за счёт соотношения долг/рыночная капитализация. Так что тут имеет смысл все таки посчитать конкретную ставку для каждой компании. По поводу предсказания выручки — вы правы, это довольно сложно, если действовать через предсказания драйверов (объём рынка, доля компании, цена товара). Но зная то, чем торгует компания, в модель можно добавить цены соответствующих товаров (если они биржевые), что добавит динамики для модели. Ведь если мы знаем цену и она снижается, то выручка тоже будет снижаться (при постоянном объеме). В остальном упрощая подход, можно основываться на темпе роста выручки за предыдущие годы. Но и выручка это не все, оценка это про денежные потоки, значит от выручка надо переходить к free cash flow через прогноз других показателей (объём инвестиций например в основные средства). И часто дивиденды платятся именно из показателя fcf, что влияет на желаемость акции участниками рынка (низкие дивиденды без роста — мало желающих). Поэтому в модель точно надо добавлять дивиденды
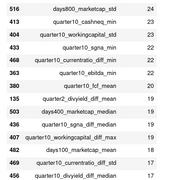 Видно, что признаки с ними действительно важны и встречаются в топе(на картинке только топ~50, а всего признаков более 500). Возможно и предсказание на будущее что-то даст…
Видно, что признаки с ними действительно важны и встречаются в топе(на картинке только топ~50, а всего признаков более 500). Возможно и предсказание на будущее что-то даст…500 факторов — впечатляет) а рэйшос добавляли? Вижу в топе только карент рэйшо — это ликвидность, но, например, долг/капитализация (хотя бы на t-1) нет, но это точно должно существенно влиять на стоимость, как и стоимость заимствования (% / debt).
По поводу fcf — он может быть не стабильным, именно поэтому переходят от выручки к нему, накладывая корректировки, даже если выручка это просто экстраполяция, а не экстраполируют напрямую. Думаю тут пригодился бы ещё темп роста основных средств и показатель выручка/основные средства. Исходя из вашего подхода к обучению модели, применена идея «одинаковые компании должны стоить одинаково». Соответственно, такой поход часто базируется на стандартных и всем известных мультипликаторах, так что соотношения строк баланса и pl тоже бы очень пригодились
- долг/капитализация
- выручка/основные средства
- соотношения строк баланса и pl(тут, честно говоря, не до конца понял — это то же самое, что и собственные средства/чистую прибыль?)
Может быть что-то еще есть убойное?)
>>(хотя бы на t-1)
у меня все фичи сразу агрегатами считаются на 10 кварталов)
Про соотношения строк баланса это как пример пункт 1. Потому что это соотношение используется для расчёта wacc и вообще оценки риска компании. 2 этот показатель важен, потому что в производстве, именно ОС генерят выручку, поэтому чем больше ос тем больше выручка (поэтому размер инвестиций в ос является важным фактором). Но это может не работать в написании софта, потому что софт пишут люди, а не ос) 3. Тут можно подойти так — посчитать соотношения всех строк со всеми и отбросить не значимые, но это брутал, конечно, потому что 90% соотношений ничего не значат. Я бы добавил ещё, что например, существует такой показатель как чистый долг: Debt — Cash, стоимость заимствования interest expense*(1-tax rate) / debt. А tax rate = income tax / EBT. Плюс пара прочих показателей ликвидности. И ещё, DCF это не единственный способ оценки, есть модель EVA — тоже примеряется. Тут скорее я вас отправлю читать «valuation» от маккинзи, там хорошо разбирается Ева (по крайней мере можно от туда взять формулы), модель хороша тем, что использует норму рентабельности активов и реально важно понимать, какая она, потому что если рентабельность низкая, то наращивание низкорентабельных активов пойдёт скорее в минус оценки, чем в плюс. И все ещё — дамодаран, скачайте эксельки с 2000 года по отраслям по Бетта коэффициенту для сша. Это должно помочь
А по поводу цен — вы можете добавить для начала торгуемые коммодитиз, я на 100% уверен, что они будут значимы для модели. Потому что например, не смотря на то, что авиалинии не торгуют нефтью, цена на нефть влияет на себестоимость горючки для самолётов, что приводит к снижению прибыльности и денежных потоков :)
Золото и платина скорее всего коррелированны при этом. У меня есть сильное подозрение, что модель абсолютной оценки упирается в особенности решающих деревьев. тут скорее что то вроде регрессии надо пробовать, потому что практика показывает что цена акций, например, золотодобытчиков, очень сильно связана с ценой на золото (что логично) и неплохо прогнозируется именно простой регрессией. Как вариант, может быть ансамбль регрессия — деревья (на ошибке регрессии), тогда уберётся необходимость экстраполяции для деревьев, чего они делать не умеют
Кстати, а вы как то учитываете количество акций в обороте? Просто если знать выручку, то даже самый большой гуру не сможет предсказать цену акции, не зная их количество в обороте (соответственно нужна фича выручка/количество акций и тд).
Я кстати использовал линейную регрессию для предсказания цены Алросы на основе выручки, wacc, курса доллара — вышло годно, но не устойчиво. В конце 2020 и 2021 сильная недооценка по сравнению с рынком была, потому что последняя отчётность была с кризисной выручкой и естественно никак не учитывала ожидания по восстановлению рынка алмазов в 2021 году (что делали участники рынка)
Вообще такое может сработать для компаний с устойчивым состоянием (то есть те кто устойчиво растут или уже выросли и находятся на текущем состоянии). Думаю тут фича в виде длительности работы компании может сработать. И ещё кстати есть фактор дисконта за малую капитализацию (такое реально применяют)
Потому что по мелким предсказывать value автоматизированно может быть очень сложно, там, во первых, низкая ликвидность, а значит высокая волатильность (и зашумленный таргет), во вторых, надо сильно погружаться в бизнес компании, потому что там высокий элемент «ожиданий», так что тут я бы упор на новости точно делал скорее
И ещё существует такая вещь как статистический арбитраж, поэтому некоторые фонды его торгуют и он может влиять на текущую оценку компании. А значит соотношения между стоимостями компаний тоже играет роль. Я уже не говорю про огромный объём пассивных инвестиций индексного типа, поэтому доля в индексе и ее изменение может играть сильную роль в оценке, а также кучу хомячков, которые торгуют на индикаторах и вносят элемент Хаоса
Для американского рынка бесплатных источников я не нашел, но есть недорогой (около 30$) поставщик довольно качественных данных с удобным API
Возможно, IEX Cloud будет обходиться дешевле чем Qandl. Если будете укладываться в 5M их попугаев кредитов в месяц, будет стоить $9 в месяц. Правда, фундаментальные данные "дорогие" и кредиты могут быстро закончиться если часто дёргать API.
Мои machine learning тулы для инвестирования