
В конце прошлого месяца 2ГИС начал отображать подъезды. Входы в организации мы показываем аж с 2013 года, а подъезды — вроде бы те же входы. Так почему только сейчас? Все внутренние продукты и процессы готовы, всего-то нужно дособрать ещё чуть-чуть да подправить отображение в UI.
Кроме стандартного ответа «Были другие приоритеты» есть и не совсем стандартный: «Не всё так просто». Эта статья про то, какие были сложности и как мы их решили.
Во-первых, подъезд — это не вход. Так, в один подъезд может вести несколько входов, обычно с разных сторон здания. Некорректно и определение «(многоуровневый) блок квартир с общим входом». Бывает, что один вход ведёт на первый этаж подъезда, а другой — на второй и последующие этажи.
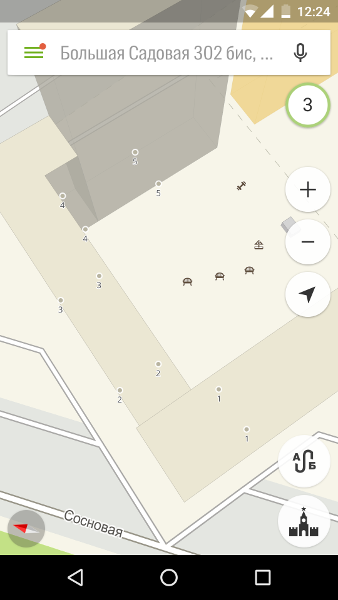
Во-вторых, подъезды хочется искать.
Это довольно востребованная возможность, так как подъезды далеко не всегда расположены очевидным образом.
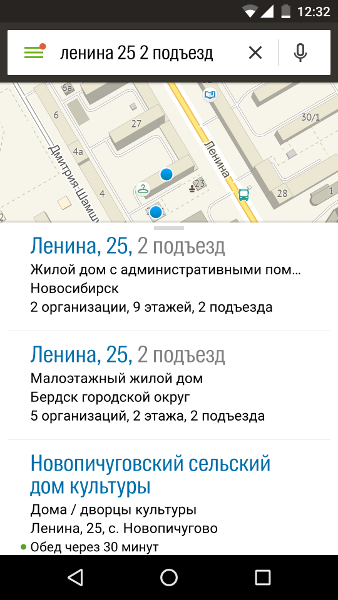
Помимо номеров подъездов встречаются и названия (как правило, из одной буквы).
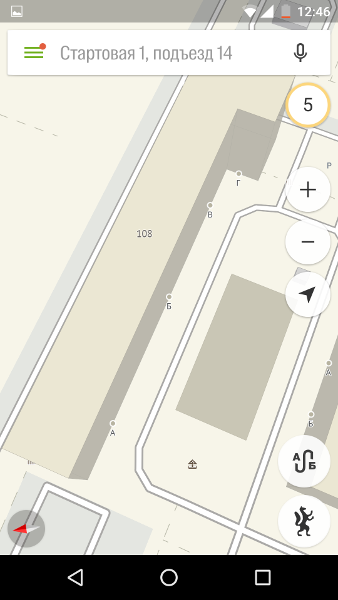
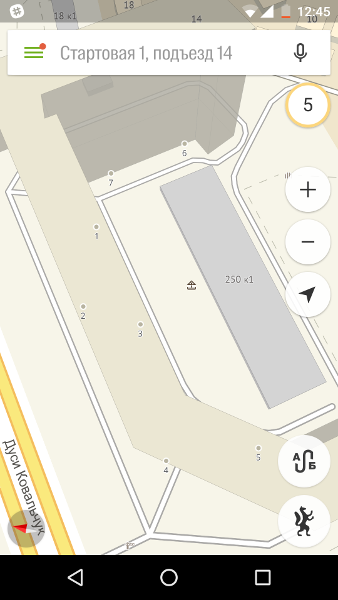
Или даже как в Калининграде — отдельный адрес присваивается именно подъезду.
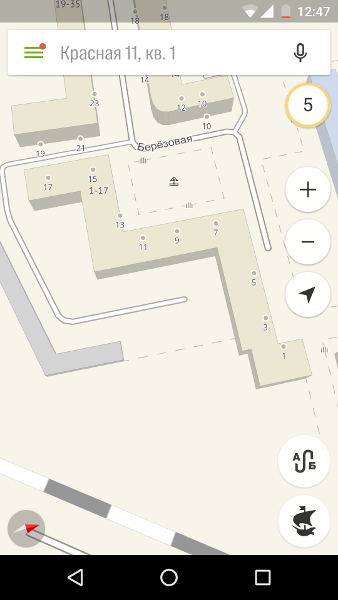
В-третьих, мы решили, что если уж делать поиск подъездов, то почему бы сразу не поддержать и поиск по номеру квартиры. Решили — и собрали диапазоны квартир, правда, пока без поэтажной привязки. Как и с подъездами, у квартир могут быть не только числовые названия (чаще всего встречаются варианты с буквой «а»), да и диапазоны далеко не всегда непрерывны. В старых домах Санкт-Петербурга нумерация довольно странная: квартиры 1 и 3 могут находиться в одном подъезде, а квартира 2 — в противоположной части здания.

Лирическое отступление про валидацию данных
Не пытайтесь сделать валидацию собираемых данных шибко умной — в северной столице нередки случаи, когда в одну квартиру можно попасть из нескольких подъездов, а в некоторых европейских населённых пунктах адрес содержит помимо дома ещё и название подъезда и номер квартиры в этом подъезде. Питер радует ещё и зданием с двумя восьмыми подъездами.
В-четвёртых, подъезды хочется показывать на карте всегда, а не только когда мы изучаем информацию конкретного дома или подъезда.
И, наконец, подъездов много — по текущей оценке в одной только Москве их около ста тысяч. Первая оценка «на пальцах» и вовсе давала какие-то астрономические цифры — мы ошиблись раз в шесть в большую сторону.
Выводы:
- Нам нужна дополнительная сущность, которая имеет своё название, содержит список диапазонов квартир и к которой могут быть привязаны входы в здание.
- Эту сущность мы будем искать и будем показывать для неё отдельную карточку с информацией.
- Мы вынуждены либо в очередной раз увеличить размер данных, загружаемых мобильным приложением, либо показывать эти данные только при наличии подключения к сети, либо что-то придумать с форматом.
Приступаем к решению
Первые два пункта требуют изменений как во внутренних продуктах, так и во внешних, но это — рутина. Последний же — совсем другое дело. Поскольку мы не любим расстраивать пользователей, поставили себе ограничение: данные должны быть доступны офлайн, а их добавление не должно увеличить размер баз.
Как? С одной стороны, нужно уменьшить текущий размер данных, с другой — можно придумать такой формат хранения информации о подъездах, чтобы объём дополнительных данных был минимальным.
Сокращаем объём данных
Уменьшать можно двумя способами:
- Посмотреть внимательно на хранимые данные и попытаться найти что-нибудь, без чего мы можем обойтись.
- Подумать, можно ли как-то хранить данные эффективнее, чем мы делаем это сейчас.
Эволюция формата хранения данных до наступления эры подъездов
Традиционный способ сохранить сложные данные — нормализовать их, поместить в табличную базу данных и создать вспомогательные индексы. Когда-то 2ГИС так и делал, разве что для уменьшения размера содержимое каждой таблицы сортировалось таким образом, чтобы как можно чаще значения ячеек совпадали со значениями из предыдущей строки. Столбцы мы хранили независимо, а последовательности одинаковых значений схлопывали.
Сильно упрощённый пример оптимизации хранения таблицы со зданиями:
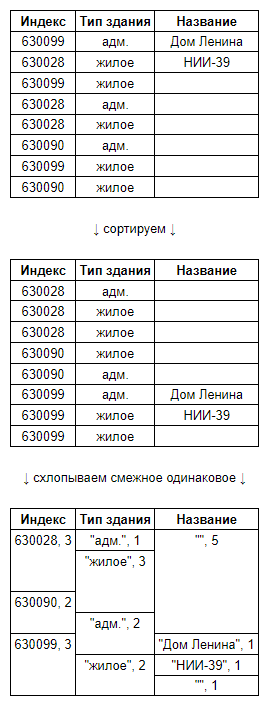
Нормализация позволяет уменьшить избыточность, но есть и негативная сторона — для формирования UI-элемента для какого-то объекта приходится делать несколько запросов, обращающихся к большому количеству таблиц. Впрочем, в то время эти таблицы использовались не только для получения данных для отображения, а практически для всех задач, включая поиск по тексту и различные типы поиска проезда. Для всех этих задач нормализованные данные как раз позволяли уменьшить количество обрабатываемой информации.
Данные для отрисовки карты уже тогда имели собственный бинарный формат и хранились в отдельном блоке. Постепенно мы сделали отдельные бинарные форматы для ускорения поиска проезда и поиска по тексту. В базе данных осталась только информация, которая использовалась для отображения карточек объектов, а также для связей одних объектов с другими.
Как можно упростить работу с данными? Получать разом все данные, необходимые для отрисовки карточки, по идентификатору объекта. Поскольку онлайн-версия и так получает от API все данные за один запрос в формате JSON, можно заодно и объединить форматы, используемые всеми нашими продуктами.
И json’ы для отображения карточек, и связи нужно получать для ограниченного количества объектов, от силы нескольких десятков за раз. Но существуют сценарии, где отдельные атрибуты нужно получать разом для больших выборок, вплоть до сотни тысяч. Такие атрибуты логичнее выделить в отдельную сущность с отдельным форматом хранения — свойства. Свойства могут иметь тип и храниться более эффективно в бинарном формате.
Наивный подход хранения json’ов — использование key-value базы данных. Возьмём для примера Москву, как самый большой из наших проектов. Даже в максимально простом виде — для каждого объекта хранится сам json, 8 байт идентификатора и символ-разделитель — справочник займёт 1,9 ГиБ. Полученный размер почти в шесть раз больше, чем у предыдущего описанного варианта, и это ещё без связей и свойств.
Мы специально раздули объекты, засунув в них информацию обо всём, что может понадобиться для отображения их карточек, а ведь ещё необходимо хранить имена полей, кавычки, запятые и скобки.
Нормализация — не единственный способ устранения избыточности. Второй популярный способ — сжатие. lzma-архив нашего невероятно толстого файла занимает всего 55 МиБ.
Конечно, использовать напрямую такой формат мы не можем, так как для доступа к произвольному объекту нужно распаковать все данные, хранящиеся раньше, да и lzma-архивы распаковываются не сильно быстро.
Как нам получить с одной стороны быстрый произвольный доступ, а с другой — при помощи сжатия данных уменьшить размер требуемого места? Ответ — использовать постраничное разбиение.
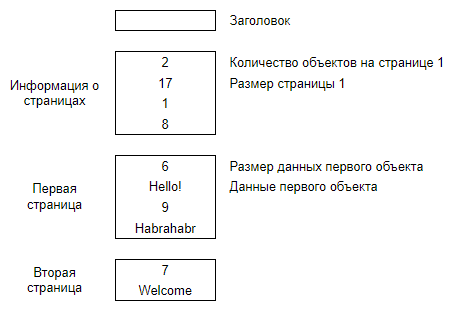
Теперь, когда данные разбиты по страницам, мы можем сжать каждую по отдельности. Для доступа к произвольному месту нам требуется распаковать и просканировать страницу, но это гораздо быстрее распаковки и сканирования всего архива.
В таком формате хранятся все данные — json’ы, связи и свойства. Осталось связать эти данные с идентификаторами объектов. Для каждого идентификатора нам нужно хранить одну или несколько пар <номер хранилища, номер данных в хранилище>.

Все порядковые номера, смещения и размеры хранятся в сжатом формате, похожем на UTF-8, где маленькие значения занимают всего один байт. Это позволяет нам уменьшить размер ссылок, просто отсортировав содержимое бинарных хранилищ по уменьшению частоты встречаемости.

Некоторые свойства имеют много частотных значений, а потому сортировка даёт большой выигрыш в размере. С другой стороны, из-за неё же порядковый номер данных не может совпадать для всех хранилищ.
Также далеко не все объекты имеют данные во всех хранилищах, а потому хранить номера хранилищ оказывается эффективнее, чем ссылаться на пустые объекты.
У описанного формата есть одна проблема. Чтобы найти номер объекта, хранящего индексы для указанного идентификатора, нам нужно прогнать бинарный поиск внутри данных первого объекта. Для этого нужно либо загрузить 10,9 МиБ в память, либо сделать 21 дополнительное чтение. Оба решения нам не подходят, а потому мы уменьшаем число чтений, храня данные в виде дерева.

Группируем данные по 32 объекта, а в промежуточных уровнях храним по 128 первых идентификаторов вложенных узлов. Мы добавили три уровня дерева и уменьшили количество дополнительных чтений до четырёх (а на самом деле, с учётом кэширования прочитанных ранее узлов дерева, даже до 1–3). Цена — чуть менее 400 КиБ.
На данном этапе мы довольно эффективно храним связи и свойства, но json’ы занимают много места. Это понятно. Чем больше размер страницы, тем больше туда попадает объектов и тем лучше алгоритм сжатия способен определить, какая информация избыточна. Но, с другой стороны, тем больше работы нам нужно совершить, чтобы прочитать отдельный объект. Json’ы же — довольно большие объекты, а потому в одной странице их находится совсем немного. Следовательно, нужно помочь алгоритму лучше справляться со своей работой.
Во-первых, многие объекты имеют совпадающие схемы данных, различаются только значения атрибутов. Во-вторых, многие значения атрибутов совпадают даже у объектов с разными схемами. Выделим схемы и значения атрибутов в отдельные хранилища, а сами json’ы будем хранить в виде: ссылка на схему + ссылки на значения атрибутов.

В нашей схеме данных количество названий атрибутов ограничено. Значит, мы можем вынести их в отдельный файл и вместо них хранить номер. Также сделаем ещё несколько изменений, попутно учитывая, что json’ы у нас всегда являются объектами.

Да, мы по сути сами сжали наши данные, уменьшив простор для работы алгоритма. Но зато мы совсем немного замедлили доступ к данным, а алгоритм всё равно помогает, сжимая хранящиеся рядом похожие значения.
Устанавливаем размер страницы в 1 КиБ и оказывается, что пока мы оптимизировали формат так, чтобы, с одной стороны, чтение не было сильно медленным, а с другой — данные запаковывались максимально хорошо, мы… уже обошли «оптимизированные таблицы» и по размеру, и по удобству использования. Но не зря же всё это было! Максимальный выигрыш должен быть от сжатия значений атрибутов, свойств и схем. Натравливаем zlib и проверяем, что на фоне остальной работы чтение данных из базы занимает незначительное время. Удовлетворённые результатом, переключаемся на другие задачи.
Самый первый и самый простой вариант
Традиционный способ сохранить сложные данные — нормализовать их, поместить в табличную базу данных и создать вспомогательные индексы. Когда-то 2ГИС так и делал, разве что для уменьшения размера содержимое каждой таблицы сортировалось таким образом, чтобы как можно чаще значения ячеек совпадали со значениями из предыдущей строки. Столбцы мы хранили независимо, а последовательности одинаковых значений схлопывали.
Сильно упрощённый пример оптимизации хранения таблицы со зданиями:
Нормализация позволяет уменьшить избыточность, но есть и негативная сторона — для формирования UI-элемента для какого-то объекта приходится делать несколько запросов, обращающихся к большому количеству таблиц. Впрочем, в то время эти таблицы использовались не только для получения данных для отображения, а практически для всех задач, включая поиск по тексту и различные типы поиска проезда. Для всех этих задач нормализованные данные как раз позволяли уменьшить количество обрабатываемой информации.
Данные для отрисовки карты уже тогда имели собственный бинарный формат и хранились в отдельном блоке. Постепенно мы сделали отдельные бинарные форматы для ускорения поиска проезда и поиска по тексту. В базе данных осталась только информация, которая использовалась для отображения карточек объектов, а также для связей одних объектов с другими.
Упрощаем работу
Как можно упростить работу с данными? Получать разом все данные, необходимые для отрисовки карточки, по идентификатору объекта. Поскольку онлайн-версия и так получает от API все данные за один запрос в формате JSON, можно заодно и объединить форматы, используемые всеми нашими продуктами.
И json’ы для отображения карточек, и связи нужно получать для ограниченного количества объектов, от силы нескольких десятков за раз. Но существуют сценарии, где отдельные атрибуты нужно получать разом для больших выборок, вплоть до сотни тысяч. Такие атрибуты логичнее выделить в отдельную сущность с отдельным форматом хранения — свойства. Свойства могут иметь тип и храниться более эффективно в бинарном формате.
Наивный подход хранения json’ов — использование key-value базы данных. Возьмём для примера Москву, как самый большой из наших проектов. Даже в максимально простом виде — для каждого объекта хранится сам json, 8 байт идентификатора и символ-разделитель — справочник займёт 1,9 ГиБ. Полученный размер почти в шесть раз больше, чем у предыдущего описанного варианта, и это ещё без связей и свойств.
Мы специально раздули объекты, засунув в них информацию обо всём, что может понадобиться для отображения их карточек, а ведь ещё необходимо хранить имена полей, кавычки, запятые и скобки.
Сжимаем данные
Нормализация — не единственный способ устранения избыточности. Второй популярный способ — сжатие. lzma-архив нашего невероятно толстого файла занимает всего 55 МиБ.
Конечно, использовать напрямую такой формат мы не можем, так как для доступа к произвольному объекту нужно распаковать все данные, хранящиеся раньше, да и lzma-архивы распаковываются не сильно быстро.
Как нам получить с одной стороны быстрый произвольный доступ, а с другой — при помощи сжатия данных уменьшить размер требуемого места? Ответ — использовать постраничное разбиение.
Теперь, когда данные разбиты по страницам, мы можем сжать каждую по отдельности. Для доступа к произвольному месту нам требуется распаковать и просканировать страницу, но это гораздо быстрее распаковки и сканирования всего архива.
В таком формате хранятся все данные — json’ы, связи и свойства. Осталось связать эти данные с идентификаторами объектов. Для каждого идентификатора нам нужно хранить одну или несколько пар <номер хранилища, номер данных в хранилище>.
Все порядковые номера, смещения и размеры хранятся в сжатом формате, похожем на UTF-8, где маленькие значения занимают всего один байт. Это позволяет нам уменьшить размер ссылок, просто отсортировав содержимое бинарных хранилищ по уменьшению частоты встречаемости.
Некоторые свойства имеют много частотных значений, а потому сортировка даёт большой выигрыш в размере. С другой стороны, из-за неё же порядковый номер данных не может совпадать для всех хранилищ.
Также далеко не все объекты имеют данные во всех хранилищах, а потому хранить номера хранилищ оказывается эффективнее, чем ссылаться на пустые объекты.
Ускоряем поиск данных
У описанного формата есть одна проблема. Чтобы найти номер объекта, хранящего индексы для указанного идентификатора, нам нужно прогнать бинарный поиск внутри данных первого объекта. Для этого нужно либо загрузить 10,9 МиБ в память, либо сделать 21 дополнительное чтение. Оба решения нам не подходят, а потому мы уменьшаем число чтений, храня данные в виде дерева.
Группируем данные по 32 объекта, а в промежуточных уровнях храним по 128 первых идентификаторов вложенных узлов. Мы добавили три уровня дерева и уменьшили количество дополнительных чтений до четырёх (а на самом деле, с учётом кэширования прочитанных ранее узлов дерева, даже до 1–3). Цена — чуть менее 400 КиБ.
На данном этапе мы довольно эффективно храним связи и свойства, но json’ы занимают много места. Это понятно. Чем больше размер страницы, тем больше туда попадает объектов и тем лучше алгоритм сжатия способен определить, какая информация избыточна. Но, с другой стороны, тем больше работы нам нужно совершить, чтобы прочитать отдельный объект. Json’ы же — довольно большие объекты, а потому в одной странице их находится совсем немного. Следовательно, нужно помочь алгоритму лучше справляться со своей работой.
Разбиваем json’ы на части
Во-первых, многие объекты имеют совпадающие схемы данных, различаются только значения атрибутов. Во-вторых, многие значения атрибутов совпадают даже у объектов с разными схемами. Выделим схемы и значения атрибутов в отдельные хранилища, а сами json’ы будем хранить в виде: ссылка на схему + ссылки на значения атрибутов.
В нашей схеме данных количество названий атрибутов ограничено. Значит, мы можем вынести их в отдельный файл и вместо них хранить номер. Также сделаем ещё несколько изменений, попутно учитывая, что json’ы у нас всегда являются объектами.
Да, мы по сути сами сжали наши данные, уменьшив простор для работы алгоритма. Но зато мы совсем немного замедлили доступ к данным, а алгоритм всё равно помогает, сжимая хранящиеся рядом похожие значения.
Устанавливаем размер страницы в 1 КиБ и оказывается, что пока мы оптимизировали формат так, чтобы, с одной стороны, чтение не было сильно медленным, а с другой — данные запаковывались максимально хорошо, мы… уже обошли «оптимизированные таблицы» и по размеру, и по удобству использования. Но не зря же всё это было! Максимальный выигрыш должен быть от сжатия значений атрибутов, свойств и схем. Натравливаем zlib и проверяем, что на фоне остальной работы чтение данных из базы занимает незначительное время. Удовлетворённые результатом, переключаемся на другие задачи.
Избавляемся от ненужного
Начинаем уменьшать с поиска данных, от которых можно избавиться. Оказывается, что за время существования формата мы научились обходиться без самой большой связи. Это 10% размера!
Код на эти данные всё ещё был завязан, но необходимые изменения довольно тривиальны. А вот уже выпущенные приложения так просто не поменяешь. Мы стремимся максимально долго поддерживать не только обратную, но и прямую совместимость. И если первая знакома всем, то про вторую многие могут счастливо не думать. Мы вынуждены её поддерживать из-за довольно длинного хвоста пользователей, по разным причинам отключивших автоматическое обновление и не спешащих перейти на новую версию приложения.
Распределение пользователей по версиям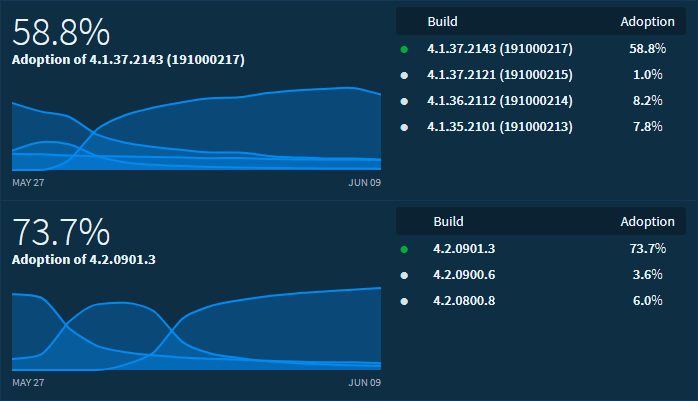
В самом верху — распределение пользователей по последним версиям Android-приложения. Снизу — iOS.
Несложно заметить, что пользователи iOS-устройств обновляются гораздо охотнее, но даже среди них пользователей старых версий очень много.
В самом верху — распределение пользователей по последним версиям Android-приложения. Снизу — iOS.
Несложно заметить, что пользователи iOS-устройств обновляются гораздо охотнее, но даже среди них пользователей старых версий очень много.
Также мы до сих пор выпускаем новые данные для замороженной версии под Windows Phone. И пусть пользователи WP8 составляют лишь малую долю от нашей аудитории, в абсолютных числах это почти 200 000 в месяц.
У нас уже давно есть механизм, который позволяет выпускать несколько форматов данных, и автоматически определяет, на какие версии что должно попасть. Возможность — это хорошо, но нужно ещё научиться эти форматы выгружать. Первой большой задачей и стала реализация сервиса, который будет получать все данные и отфильтровывать новое для старого формата базы данных и старое для нового.
Приятный бонус от проделанной работы — уменьшение размера ежемесячных обновлений, так как удалённая связь сильно изменялась от месяца к месяцу, раздувая размер diff’ов.
Если посмотреть на оставшиеся данные, то суммарно можно выжать ещё те же 10%, однако цена будет несопоставимо больше. Пока решили не трогать.
Оптимизируем текущий формат хранения
Как было написано выше, мы делали страницы размером 1 КиБ и запаковывали не все бинарные хранилища.
Первое, что делаем — пробуем упаковать ещё и страницы со связями, и проверяем, что разница в скорости получения данных находится в районе погрешности.
Следующий пункт — выбор оптимального размера страницы. Чем больше размер страницы, тем более эффективно сжимаются данные, но тем медленнее происходит выборка данных. И если с увеличением размера страницы расходы по времени и памяти растут линейно, то выигрыш становится всё менее заметным. После тестов решаем увеличить размер до 8 КиБ.
Влияние размера страницы на большие выборки
Если увеличение страницы ожидаемо замедляет маленькие выборки, то вот большие — от сотен элементов — при этом даже ускоряются. Это означает, что по-хорошему нужно выбирать разные размеры для хранилищ в зависимости от сценариев использования хранящихся в них данных.
Суммарно только эти два пункта позволяют уменьшить базу на 18%!
Меняем формат сжатия
zlib, конечно, классика, но zstd обеспечивает большую скорость распаковки при большей же степени сжатия. Более того, zstd позволяет сначала построить единый словарь для всех имеющихся данных, а затем сохранить его один раз и сжать им все страницы. Таким образом, мы прилично замедляем процесс формирования файла с базой данных, но зато выжимаем дополнительные 8%.
Добавляем подъезды
Простой способ
Самый простой способ — сделать каждый подъезд отдельным объектом, отдельно их индексировать (по грубым оценкам +10% размера индекса) и отдельно же в данных для отрисовки карты хранить их геометрию.
Такой способ раздует базу суммарно на 3%. На предыдущих этапах мы выиграли более чем достаточно, чтобы успокоиться и работать с подъездами по привычной схеме, но… на момент старта работ мы не были в этом уверены, а работа над альтернативным форматом шла параллельно.
Подробная оценка, для заинтересованных
Попробуем оценить увеличение размера пакета с базой данных на каждый объект:
8 байт — идентификатор,
6 байт — номера используемых хранилищ (данные + пять свойств; свойства выделены из основных данных и хранятся в бинарном виде, так как часто нужны для большого числа объектов разом),
3 байта — индекс в хранилище данных,
2 байта — смещение данных объекта,
5 байт — значения данных — 2 байта на схему, 3 байта в среднем на информацию о квартирах (считаем, что будет много повторяющихся и сами данные хранятся один раз),
6 байт — смещения данных координат (остальные свойства имеют много повторяющихся значений и будут схлопнуты),
8 байт — значения координат.
Итого 38 байт на объект. В случае Москвы это 4,5 МиБ для более чем 124 тысяч собранных входов.
Далее нам нужно хранить ещё и связь между домом и входами, это 2,5 байта на каждый жилой дом и 8 байт на каждый вход. Ещё 1 МиБ.
Теперь считаем, сколько всё это займёт в карте.
Во-первых, мы должны хранить геометрии. Для полилиний первая точка всегда занимает 8 байт, а все последующие хранятся в виде diff’ов нужной точности. Здесь нас устроит точность до дециметров. Большая часть входов состоит из двух точек, не сильно удалённых друг от друга, а потому можно считать, что сама геометрия будет занимать 10 байт. Итого 1,2 МиБ.
Ещё нам нужно связать идентификатор входа и объект с его геометрией. Индекс — такое же бинарное хранилище, как и всё остальное, только в данных хранится назначение связи (1 байт), номер слоя (1 байт) и номер объекта (3 байта). Плюс по 8 байт на идентификатор, а также дерево быстрого поиска. Итого ещё 1,5 МиБ.
Как было сказано в самом начале статьи, подъезды мы хотим постоянно отображать на карте, а самый простой способ это сделать — выгрузить ещё один слой с точками, но… можно и переиспользовать слой с геометриями, создав новый условный знак, который будет выводить нужную нам картинку в последней точке полилинии.
10% индекса поиска — это 5,9 МиБ. Суммируя всё, получаем 14,2 МиБ, что как раз чуть больше 3%.
8 байт — идентификатор,
6 байт — номера используемых хранилищ (данные + пять свойств; свойства выделены из основных данных и хранятся в бинарном виде, так как часто нужны для большого числа объектов разом),
3 байта — индекс в хранилище данных,
2 байта — смещение данных объекта,
5 байт — значения данных — 2 байта на схему, 3 байта в среднем на информацию о квартирах (считаем, что будет много повторяющихся и сами данные хранятся один раз),
6 байт — смещения данных координат (остальные свойства имеют много повторяющихся значений и будут схлопнуты),
8 байт — значения координат.
Итого 38 байт на объект. В случае Москвы это 4,5 МиБ для более чем 124 тысяч собранных входов.
Далее нам нужно хранить ещё и связь между домом и входами, это 2,5 байта на каждый жилой дом и 8 байт на каждый вход. Ещё 1 МиБ.
Теперь считаем, сколько всё это займёт в карте.
Во-первых, мы должны хранить геометрии. Для полилиний первая точка всегда занимает 8 байт, а все последующие хранятся в виде diff’ов нужной точности. Здесь нас устроит точность до дециметров. Большая часть входов состоит из двух точек, не сильно удалённых друг от друга, а потому можно считать, что сама геометрия будет занимать 10 байт. Итого 1,2 МиБ.
Ещё нам нужно связать идентификатор входа и объект с его геометрией. Индекс — такое же бинарное хранилище, как и всё остальное, только в данных хранится назначение связи (1 байт), номер слоя (1 байт) и номер объекта (3 байта). Плюс по 8 байт на идентификатор, а также дерево быстрого поиска. Итого ещё 1,5 МиБ.
Как было сказано в самом начале статьи, подъезды мы хотим постоянно отображать на карте, а самый простой способ это сделать — выгрузить ещё один слой с точками, но… можно и переиспользовать слой с геометриями, создав новый условный знак, который будет выводить нужную нам картинку в последней точке полилинии.
10% индекса поиска — это 5,9 МиБ. Суммируя всё, получаем 14,2 МиБ, что как раз чуть больше 3%.
Текущий вариант
Вместо того, чтобы индексировать подъезды и раздувать поисковый индекс, мы ищем дома, но дополнительно размечаем слова запроса и выделяем из него адреса (актуально для поиска подъездов в Калининграде), подъезды и/или квартиры. Таким образом, на выходе у нас есть идентификатор дома и типизированные текстовые поля, по которым мы должны найти нужный нам подъезд.
Примечание
Это спорный пункт. С одной стороны он позволяет нам сократить размер базы, а с другой ставит ограничения на формат ввода — подъезды не будут находиться по многим запросам, которые были бы правильно обработаны при использовании честного поиска.
Далее, вместо выгрузки отдельных объектов всю информацию о входах мы включаем прямо в данные здания.
И, наконец, переносим часть геометрий в справочник.
Последнее стоит раскрыть подробнее.
Во-первых, замечаем, что большинство входов состоит из двух точек и имеют одинаковую длину. Такие входы можно хранить в виде точка + направление, т.е. экономить по 1 байту на каждый вход.
Во-вторых, предполагаем, что большинство домов в современных городах являются типовыми, следовательно, смещения точек их входов относительно центральной точки дома совпадут с точностью до поворота.
Центральные точки зданий у нас уже есть. Что, если для здания добавить новое свойство — его целочисленное «направление», а для каждого входа выделить ещё два — целочисленные смещения в дециметрах вдоль и перпендикулярно линии направления? Учитывая, как у нас хранятся json’ы с информацией, геометрия входа в среднем будет занимать чуть более двух байт.
Дополнительный бонус — поскольку геометрия находится в справочнике, нам более не нужно хранить соответствие между идентификатором входа и номером объекта в слое карты.
Минус — усложнился код. Ранее мы просто говорили карте «покажи такие-то объекты», а теперь при отображении входов добываем эти данные из json’а и добавляем на карту динамические объекты. Тут всё не сильно страшно. К моменту отображения стрелочек входов json’ы соответствующих объектов у нас уже есть, то есть нет необходимости дополнительно идти в базу. С отображаемыми точками подъездов всё несколько хуже — теперь нам приходится в фоне определять, какие дома видны, вытаскивать данные этих домов из базы данных, разбирать json’ы, и, если там есть входы, создавать для них динамические объекты.
Примечание
Неоднозначное решение. Даже с учётом всевозможных оптимизаций и довольно быстрой работы всё равно совершаем дополнительные действия, без которых можно было обойтись, увеличив размер базы на 0,2% (972 КиБ для Москвы).
Поскольку для отображения входов подъездов у нас уже написан дополнительный код, ничего не мешает начать хранить в справочнике и двухточечные входы в организации. Выигрыш в этом случае будет небольшим, зато бесплатным.
Сколько нам это дало? 3% превратились в 0,5%. Можно было бы ещё меньше, но мы оставили в данных идентификаторы (которые довольно плохо сжимаются), чтобы упростить обработку сообщений пользователей о неточных входах.
Результат
Мы добавили большое количество подъездов, при этом сократив размер файла с данными карты на 0,5% и уменьшив на 26,6% размер файла с данными справочника. Последний по-прежнему является самым большим из наших файлов, но он — лишь один из четырёх «тяжёлых» файлов, так что общее изменение получилось более скромным — 10,1%.
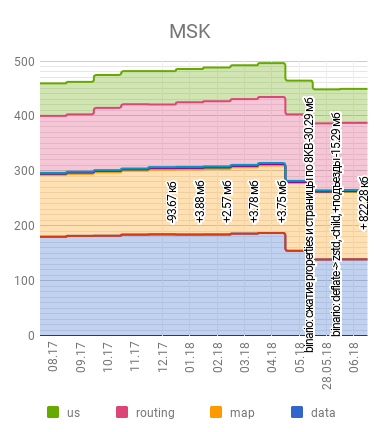
Подъезды собраны пока не все. Размер баз со временем немного подрастёт (по текущей оценке та же Москва увеличится на 0,4%), но в любом случае цель выпустить подъезды, не увеличив размер, более чем достигнута.
Что дальше?
Если говорить о продуктовых доработках, то собираемся поддержать подъезды и квартиры в подсказках поиска, а также в поиске начальной и конечной точек поиска проезда. Также думаем о том, чтобы аналогично подъездам отображать важные входы в здания (в основном в торговых центрах).
В технических же планах есть проверка нескольких идей, которые могут привести к дальнейшему уменьшению размера файла со справочными данными, да и на другие файлы надо внимательно посмотреть.
И, конечно, будем править ошибки, которых пока что имеется.
One more thought: используйте JSON разумно
Из написанного выше напрашивается вывод, что можно не сильно думать о бинарных форматах и просто использовать JSON. Это не совсем так. У нас это работает, так как единомоментно нам нужно получать от силы несколько десятков объектов. Плюс мы используем rapidjson, а он очень шустрый и потребляет мало памяти.
Также стоит ограничивать передачу данных в формате JSON из C++ в UI, написанный на другом языке.
Во-первых, вам придётся превратить его в строку.
Во-вторых, парсеры, доступные из UI-части, будут повторно эту строку разбирать, и будут делать это заметно медленнее.
Лучше самостоятельно доставать из JSON’а все данные, а на сторону UI прокидывать простые интерфейсы, адаптированные для отображения конкретных элементов.
