Comments 42
Сейчас уже готов тестовый образец памяти STTMRAM. Размер рабочей части ячейки составляет 11 нм. Соответственно, память такого типа будет производиться по 10-нм техпроцессу.
Не указано. Много тестовых 4-кбит массивов с разными размерами ячеек.
http://dx.doi.org/10.1109/LMAG.2016.2539256 Dependence of Voltage and Size on Write Error Rates in Spin-Transfer Torque Magnetic Random-Access Memory — IEEE Magnetics Letters Volume:7, 2016 (указывалось иное название "Voltage and size dependence on write-error-rates in STT MRAM down to 11 nm junction size." в http://www.eetimes.com/document.asp?doc_id=1330058)
(что защита делается элементарно — понимаю, интересует теоретически)
еще OLED телевизоры нам обещали. Телевизоров мы так и не получили...
Как это нет, не далеко от меня продаются несколько OLED телевизоров 4k8k с полутрометровыми диагоналями за пару миллионов йен. На всякую «мелочь» не смотрел, наверняка тоже есть.
Ну и, в теории, становятся возможны такие финты ушами — запускаем машину, запускаем задачи, переводим в спящий режим, вытаскиваем оперативку, вставляем в другой компьютер, включаем, продолжаем с точки останова.
Вообще было бы очень приятно получить хорошую замену как минимум флэш-памяти и жёстким дискам. Первая дорогая и не слишком надёжная, вторые большие, медленные и боятся механических воздействий. Однако, несмотря на количество проектов неволатильной памяти, ни одна не вышла на широкий рынок. Максимум — нишевые решения. Так что я повременю радоваться пока не выпустят хоть одну небольшую серию потребительских железок.
А по теме: реальный прорыв в технологиях хранения данных, высокая скорость доступа, высокая плотность записи, нет ограничений на количество перезаписей, энергонезависимое хранение… похоже, что век flash-SSD будет коротким (как у CD примерно).
У них в данном случае не 10нм литография, у них 10 нм (11.1 нм) ширина одной структуры — https://hsto.org/files/a20/d78/730/a20d787304fd46d4a0f2be9d0b6fccfb.jpg. (Но тестовые структуры на "7 нм" техпроцесс в IBM уже делают — https://geektimes.ru/company/ibm/blog/253254/)
{kind=link}
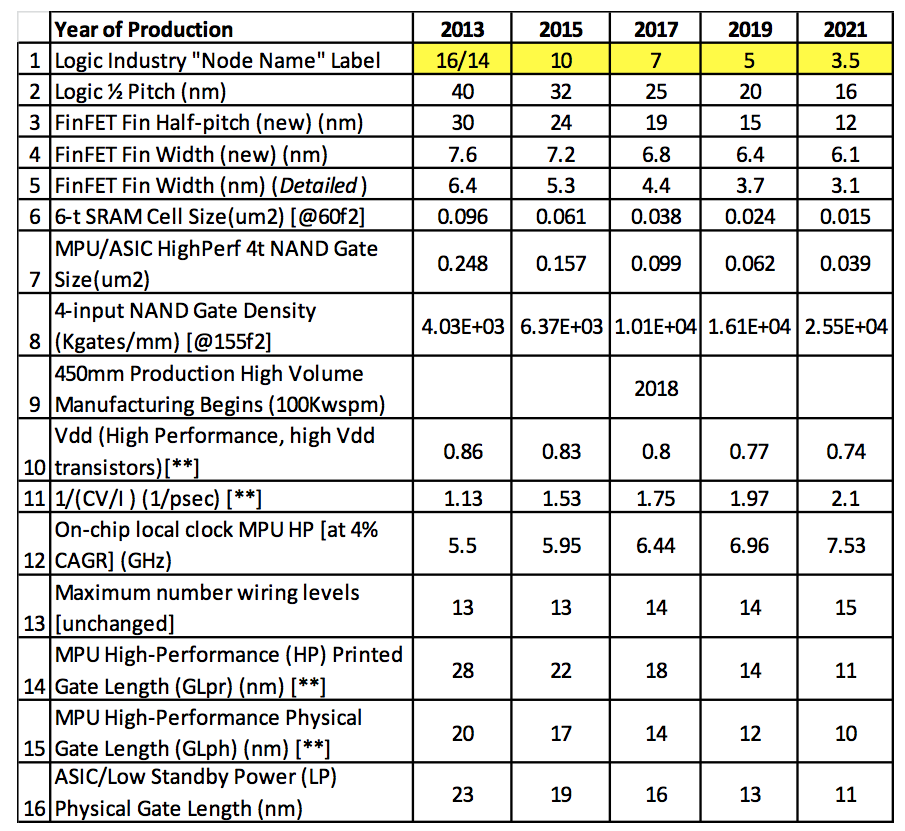
В настоящей "14 нм" литографии (на базе 193nm ArF excimer с иммерсией + Double patterning / triple patterning "on one or more critical layers.") нет элементов с размером в 14 нм (см слайд 16 из Rani Borkar, A Multi-Year Journey, 2014:
Minimum Feature Size(nm); 22 nm node / 14 nm node: Transistor Fin Pitch 60 / 42; Transistor Gate Pitch 90 / 70; Interconnect Pitch 80 / 52). Маркетинговые обозначения техпроцессов лишь указывают на удвоение максимальной плотности размещения элементов по сравнению с предыдущим техпроцессом (и название получается умножением предыдущего на 0.7). Реальные расстояния между элементами получаются больше чем обозначение техпроцесса, а некоторые размеры отдельных элементов — меньше, см. прогноз Table 1: ITRS 2013 Data for CMOS Technology “Nodes” из http://semiengineering.com/a-node-by-any-other-name/
{kind=link}
{kind=link}
высокая плотность записи
Плотность элементов они пока что не демонстрируют. В статье http://dx.doi.org/10.1109/LMAG.2016.2539256 https://www.researchgate.net/publication/297676487_Voltage_and_Size_Dependence_on_Write-Error-Rates_in_STT_MRAM_down_to_11_nm_Junction_Size лишь упомянут объем каждого массива из 38 изготовленных — 4 килобита, каждый массив имеет переход различного диаметра (от 50 нм до 11), но линейные размеры ячеек или всего массива не указаны:
… device size was examined in individual devices of 38 STT MRAM 4 kbit chips. Each of the 38 arrays had a different junction diameter.
Вероятно (с учетом 200 мм пластин в руках у Guohan Hu), для исследований использовалась не самые современные литографы...
IBM сообщила, что STT-MRAM может заменить встроенный флеш в логических техпроцессах ("28нм" и тоньше):
https://www.ibm.com/blogs/research/2016/07/ibm-celebrates-20-years-spin-torque-mram-scaling-11-nanometers/
… makes MRAM an ideal technology for always-on devices such as Internet of Things sensors, mobile devices and wearable electronics,… because MRAM uses standard transistors, ..it’s more easily embedded on the same chip as logic and other functions, compared to flash memory. Therefore many semiconductor foundries are considering replacing embedded flash with embedded Spin Torque MRAM at the 28-nm node and beyond.
PS: У Everspin есть MRAM на 256 мегабит, 40nm и 28nm. А флеш-память уже имеет плотность в 256 гигабит, на 3 порядка выше. Intel обещает 128 gbit в Optane (3D XPoint).
Сейчас используют 193 нм засветку, ширину элементов в 16-17 нм получают
http://www.embedded.com/print/4395587 Figure: TEM cross-section perpendicular to the fins and along metal gate.
Для одиночных отверстий/линий (расположенных далеко от других элементов) можно найти сочетание литографии и травлений, которые создадут нужный размер элемента.
Снизу на https://hsto.org/files/a20/d78/730/a20d787304fd46d4a0f2be9d0b6fccfb.jpg видна часть линии (WL или BL), её размер значительно больше 10 нм.
Кстати, для экспериментов вполне могли воспользоваться e-beam litho: "it can draw custom patterns (direct-write) with sub-10 nm resolution"
Они используют интерференцию при экспонировании фотошаблонов. Как они тогда фотошаблоны готовят? Однозначно! Это заговор! :)
Как они тогда фотошаблоны готовят?
Фотошаблоны ныне имеют линейные размеры в 4 раза больше области засвета (максимальное поле засвета 26х33 мм, шаблоны — ~ 104 x 132 мм). Структуры на шаблонах должны иметь точность нанесения в нм близкую к разрешению литографа (~40-50 нм, см NXT — Technical Specifications). Пишут маски (шаблоны) с помощью лазеров или электронных пучков, в течение часов (десятков часов); затем (в нескольих итерациях) проверяют что записалось (микроскопом) и чинят (ионными пучками?).
В одном проекте десятки шаблонов (30-40, т.н. photomask set), из них 1/4-1/3 — для "критических слоёв", имеющих значительную стоимость (~100 тыс USD) максимальное разрешение (OPC+PSM) — т.е. для транзисторов (FEOL, несколько слоев: n-well, poly, sources, drains, nitride, contacts), и нескольких (1-4) нижних слоев металла (2 слоя на каждый металл: переходные отверстия между слоями и сам слой металла). При использовании Double patterning требуется две маски на слой. Для ряда критических слоев на 14 нм Интел уже использует triple patterning — по три маски на слой ("Bohr revealed that Intel is already using triple patterning for certain critical layers at 14nm").
Верхние металлы (BEOL) имеют более "толстые" техпроцессы с более простыми (дешевыми) масками.
Процесс изготовления простых (binary) масок, Roger Robbins "Photomask Making" 2007: http://www.utdallas.edu/~rar011300/LithographyProcess/PhotomaskMaking.pdf
Кто как, но Интел уже сделал для себя специальный кластер для подготовки шаблонов.
Вот статья про кластер для SMIC (Китай), Application of HPC in Mask Manufacturing — упрощенная схема подготовки шаблонов:
http://www.intel.com.tr/content/dam/www/public/us/en/documents/case-studies/xeon-e5-smic-paper.pdf Semiconductor Manufacturing International Corporation (SMIC) mask factory deploys high-performance computing solution to reduce costs and shorten the semiconductor manufacturing cycle. 2015
Собственные мощности: http://www.nextplatform.com/2015/11/26/intel-supercomputer-powers-moores-law-life-support/ Intel’s Own Supercomputer Powers Moore’s Law Life Support — November 26, 2015
Bohr says it takes a million CPU hours to design the photomasks to pattern the integrated circuits at scale currently. “That is the price we have to pay to pattern ten nanometer dimensions using 193 nanometer light.
Подробная статья про HPC внутри самого Intel для изготовления чипов
http://www.intel.com/content/dam/www/public/us/en/documents/white-papers/intel-it-hpc-silicon-design-paper.pdf High-Performance Computing For Silicon Design. 2013
• Four generations of HPC have successfully enabled Intel silicon tapeout, reducing tapeout time from 25 to less than 10 days.
… electronic design automation (EDA) tools. These tools apply extremely compute-intensive resolution enhancement techniques (RET) to update layout data for mask manufacturability and verify the data for compliance to mask manufacturing rules. A key EDA application within the tapeout stage is optical proximity correction (OPC), which makes it possible to create circuitry that contains components far smaller than the wavelength of light directed at the mask. OPC is a complex, compute-bound process. To accelerate the process, OPC applications take advantage of distributed parallel processing; tasks are divided into thousands of smaller jobs that run on large server clusters. It is critical to complete tapeout as fast as possible—and to minimize errors
HPC-1 45nm 2006-2008, HPC-2 32nm 2008-2010, HPC-3 22nm 2010-2012, HPC-4 14nm 2012-
The largest tapeout jobs, such as design rule check (DRC) workloads, require servers with a very large RAM capacity. We also use these large-memory servers as master servers for distributed OPC applications.
To illustrate the scale of the challenge, there may be as many as 40,000 OPC jobs executing concurrently on thousands of servers.
Про HPC-5 для "10 нм" техпроцесса http://media15.connectedsocialmedia.com/intel/12/14135/Hyperscale_High_Performance_Computing_Silicon_Design.pdf декабрь 2015
HPC-5 Large-Memory Compute Server with 3 TB and up to 6 TB of RAM… 4 Rack Units… 1.49 kW consumed
EDA application license server… simultaneous license checkout of 1,000 keys per second from a single machine
We are currently developing the sixth-generation HPC (HPC-6), which is planned to support the tape-out of 7nm processors.
Они используют интерференцию при экспонировании фотошаблонов
Высчитывают: https://en.wikipedia.org/wiki/Computational_lithography ftp://download.intel.com/pressroom/kits/research/computational_litho_poster.pdf
IBM и Samsung разработали 11-нм память STTMRAM