В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ.

Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».
В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.

Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.

К взлёту готов! Intel® Desktop Board D5400XS
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.
Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.

Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).
Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т.к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?
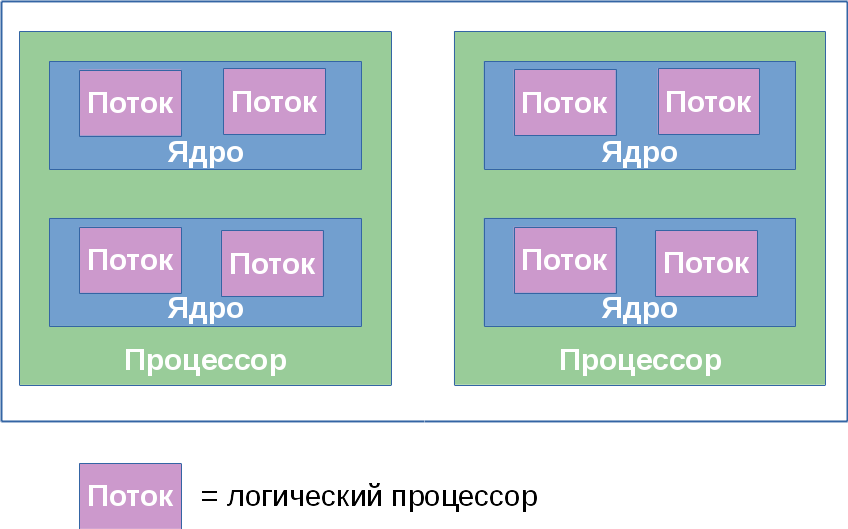
Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
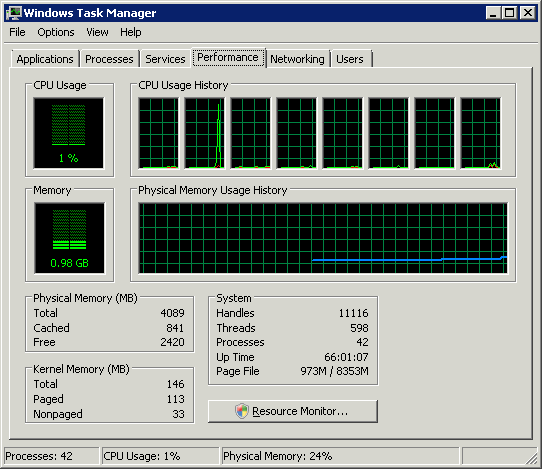
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?

Linux
Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
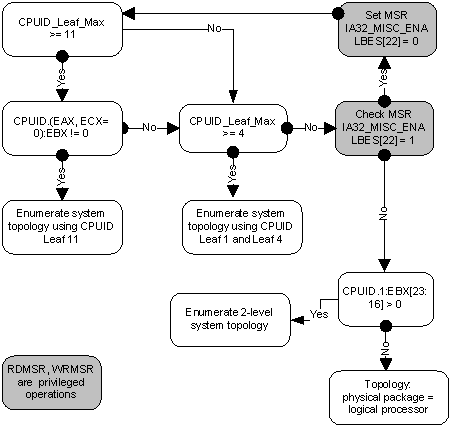
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
Local APIC (advanced programmable interrupt controller) — это устройство (ныне входящее в состав процессора), отвечающее за работу с прерываниями, приходящими к конкретному логическому процессору. Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC и xAPIC к x2APIC.
В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
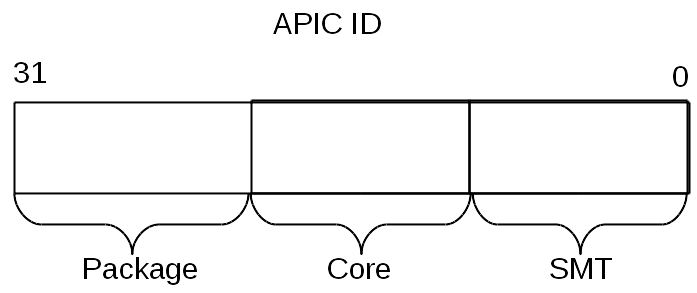
У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.
В Linux информация о топологии содержится в псевдофайле
В FreeBSD топология сообщается через механизм sysctl в переменной kern.sched.topology_spec в виде XML:
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.
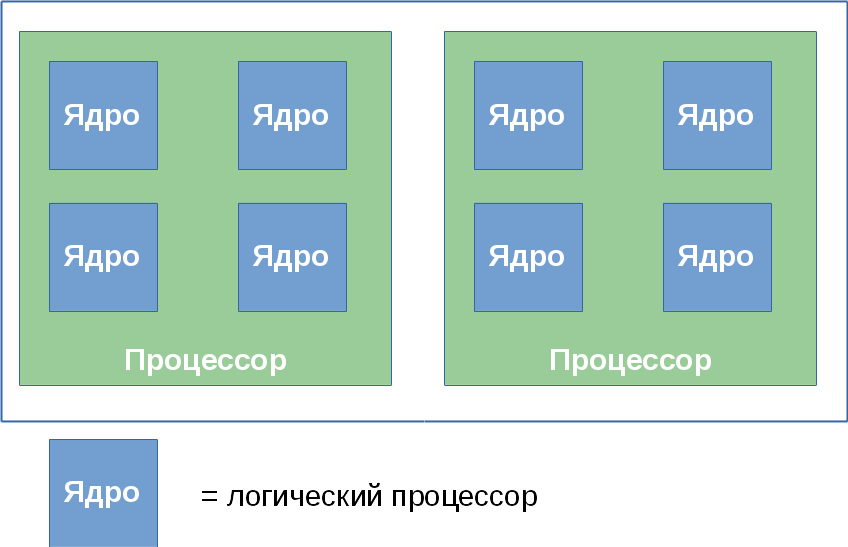
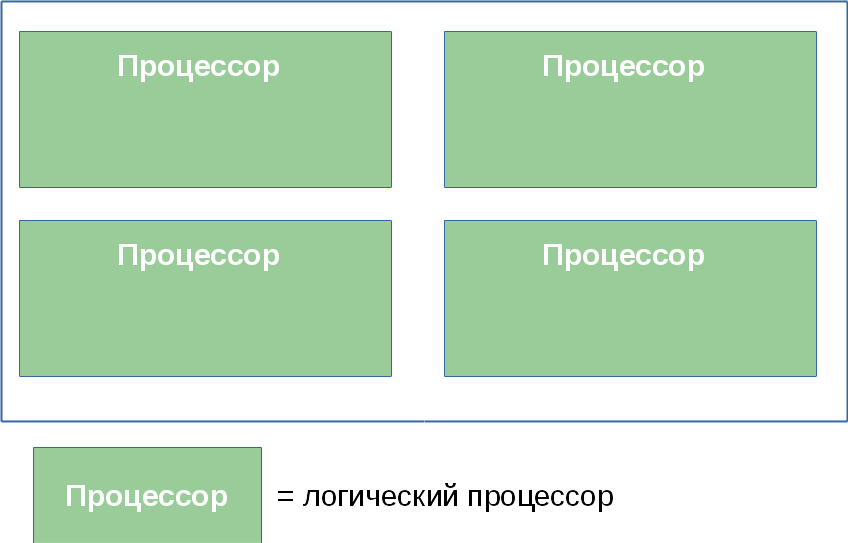
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.
Спасибо за внимание!
Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Предупреждение о знаках ®, ™, © в статье
Мой комментарий объясняет, почему сотрудники компаний должны в публичных коммуникациях использовать знаки авторского права. В этой статье их пришлось использовать довольно часто.
Процессор
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».
В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.
Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.
К взлёту готов! Intel® Desktop Board D5400XS
Ядро
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.
Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
Гиперпоток
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).
Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
Ограничения потоков
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т.к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Логический процессор
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?
Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?
Linux
top показывает 4 логических процессора.Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Программное определение топологии
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
APIC ID
Local APIC (advanced programmable interrupt controller) — это устройство (ныне входящее в состав процессора), отвечающее за работу с прерываниями, приходящими к конкретному логическому процессору. Свой собственный APIC есть у каждого логического процессора. И каждый из них в системе должен иметь уникальное значение APIC ID. Это число используется контроллерами прерываний для адресации при доставке сообщений, а всеми остальными (например, операционной системой) — для идентификации логических процессоров. Спецификация на этот контроллер прерываний эволюционировала, пройдя от микросхемы Intel 8259 PIC через Dual PIC, APIC и xAPIC к x2APIC.
В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Выяснение родственных связей
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы и топология
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.
В Linux информация о топологии содержится в псевдофайле
/proc/cpuinfo, а также выводе команды dmidecode. В примере ниже я фильтрую содержимое cpuinfo на некоторой четырёхядерной системе без HT, оставляя только записи, относящиеся к топологии:Скрытый текст
ggg@shadowbox:~$ cat /proc/cpuinfo |grep 'processor\|physical\ id\|siblings\|core\|cores\|apicid'
processor : 0
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 0
initial apicid : 0
processor : 1
physical id : 0
siblings : 4
core id : 0
cpu cores : 2
apicid : 1
initial apicid : 1
processor : 2
physical id : 0
siblings : 4
core id : 1
cpu cores : 2
apicid : 2
initial apicid : 2
processor : 3
physical id : 0
siblings : 4
core id : 1
cpu cores : 2
apicid : 3
initial apicid : 3
В FreeBSD топология сообщается через механизм sysctl в переменной kern.sched.topology_spec в виде XML:
Скрытый текст
user@host:~$ sysctl kern.sched.topology_spec
kern.sched.topology_spec: <groups>
<group level="1" cache-level="0">
<cpu count="8" mask="0xff">0, 1, 2, 3, 4, 5, 6, 7</cpu>
<children>
<group level="2" cache-level="2">
<cpu count="8" mask="0xff">0, 1, 2, 3, 4, 5, 6, 7</cpu>
<children>
<group level="3" cache-level="1">
<cpu count="2" mask="0x3">0, 1</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0xc">2, 3</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0x30">4, 5</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
<group level="3" cache-level="1">
<cpu count="2" mask="0xc0">6, 7</cpu>
<flags><flag name="THREAD">THREAD group</flag><flag name="SMT">SMT group</flag></flags>
</group>
</children>
</group>
</children>
</group>
</groups>
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Скрытый текст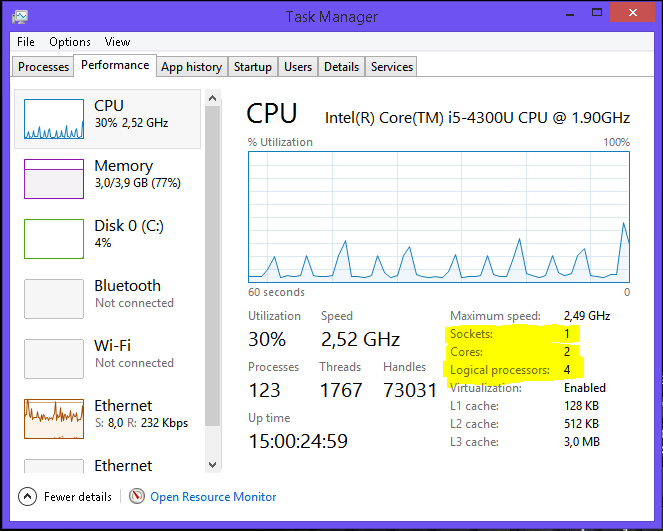
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Полная картина
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.
Система (2, 2, 2)
Система (2, 4, 1)
Система (4, 1, 1)
Прочие вопросы
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.
Кэши
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.
Лицензирование
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Виртуализация
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.
Спасибо за внимание!
Литература
- Intel Corporation. Intel® 64 and IA-32 Architectures Software Developer’s Manual. Volumes 1–3, 2014. www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
- Shih Kuo. Intel® 64 Architecture Processor Topology Enumeration, 2012 — software.intel.com/en-us/articles/intel-64-architecture-processor-topology-enumeration
- OSDevWiki. MADT. wiki.osdev.org/MADT
- OSDevWiki. Detecting CPU Topology. wiki.osdev.org/Detecting_CPU_Topology_%2880x86%29
