
Этим летом мне посчастливилось попасть на летнюю стажировку в компанию Itseez. Мне было предложено исследовать современные методы, которые позволили бы выделить местоположения объектов на изображении. В основном такие методы опираются на сегментацию, поэтому я начала свою работу со знакомства с этой областью компьютерного зрения.
Сегментация изображения — это разбиение изображения на множество покрывающих его областей. Сегментация применяется во многих областях, например, в производстве для индикации дефектов при сборке деталей, в медицине для первичной обработки снимков, также для составления карт местности по снимкам со спутников. Для тех, кому интересно разобраться, как работают такие алгоритмы, добро пожаловать под кат. Мы рассмотрим несколько методов из библиотеки компьютерного зрения OpenCV.
Алгоритм сегментации по водоразделам (WaterShed)


Алгоритм работает с изображением как с функцией от двух переменных f=I(x,y), где x,y – координаты пикселя:



Значением функции может быть интенсивность или модуль градиента. Для наибольшего контраста можно взять градиент от изображения. Если по оси OZ откладывать абсолютное значение градиента, то в местах перепада интенсивности образуются хребты, а в однородных регионах – равнины. После нахождения минимумов функции f, идет процесс заполнения “водой”, который начинается с глобального минимума. Как только уровень воды достигает значения очередного локального минимума, начинается его заполнение водой. Когда два региона начинают сливаться, строится перегородка, чтобы предотвратить объединение областей [2]. Вода продолжит подниматься до тех пор, пока регионы не будут отделяться только искусственно построенными перегородками (рис.1).



Рис.1. Иллюстрация процесса заполнения водой
Такой алгоритм может быть полезным, если на изображении небольшое число локальных минимумов, в случае же их большого количества возникает избыточное разбиение на сегменты. Например, если непосредственно применить алгоритм к рис. 2, получим много мелких деталей рис. 3.

Рис. 2. Исходное изображение

Рис. 3. Изображение после сегментации алгоритмом WaterShed
Как справиться с мелкими деталями?
Чтобы избавиться от избытка мелких деталей, можно задать области, которые будут привязаны к ближайшим минимумам. Перегородка будет строиться только в том случае, если происходит объединение двух регионов с маркерами, в противном случае будет происходить слияние этих сегментов. Такой подход убирает эффект избыточной сегментации, но требует предварительной обработки изображения для выделения маркеров, которые можно обозначить интерактивно на изображении рис. 4, 5.

Рис. 4. Изображение с маркерами

Рис. 5. Изображение после сегментации алгоритмом WaterShed с использованием маркеров
Если требуется действовать автоматически без вмешательства пользователя, то можно использовать, например, функцию findContours() для выделения маркеров, но тут тоже для лучшей сегментации мелкие контуры следует исключить рис. 6., например, убирая их по порогу по длине контура. Или перед выделением контуров использовать эрозию с дилатацией, чтобы убрать мелкие детали.

Рис. 6. В качестве маркеров использовались контуры, имеющие длину выше определенного порога
Рис. 4. Изображение с маркерами
Рис. 5. Изображение после сегментации алгоритмом WaterShed с использованием маркеров
Если требуется действовать автоматически без вмешательства пользователя, то можно использовать, например, функцию findContours() для выделения маркеров, но тут тоже для лучшей сегментации мелкие контуры следует исключить рис. 6., например, убирая их по порогу по длине контура. Или перед выделением контуров использовать эрозию с дилатацией, чтобы убрать мелкие детали.
Рис. 6. В качестве маркеров использовались контуры, имеющие длину выше определенного порога
В результате работы алгоритма мы получаем маску с сегментированным изображением, где пиксели одного сегмента помечены одинаковой меткой и образуют связную область. Основным недостатком данного алгоритма является использование процедуры предварительной обработки для картинок с большим количеством локальных минимумов (изображения со сложной текстурой и с обилием различных цветов).
Пример кода для запуска алгоритма:
Mat image = imread("coins.jpg", CV_LOAD_IMAGE_COLOR);
// выделим контуры
Mat imageGray, imageBin;
cvtColor(image, imageGray, CV_BGR2GRAY);
threshold(imageGray, imageBin, 100, 255, THRESH_BINARY);
std::vector<std::vector<Point> > contours;
std::vector<Vec4i> hierarchy;
findContours(imageBin, contours, hierarchy, CV_RETR_TREE, CV_CHAIN_APPROX_SIMPLE);
Mat markers(image.size(), CV_32SC1);
markers = Scalar::all(0);
int compCount = 0;
for(int idx = 0; idx >= 0; idx = hierarchy[idx][0], compCount++)
{
drawContours(markers, contours, idx, Scalar::all(compCount+1), -1, 8, hierarchy, INT_MAX);
}
std::vector<Vec3b> colorTab(compCount);
for(int i = 0; i < compCount; i++)
{
colorTab[i] = Vec3b(rand()&255, rand()&255, rand()&255);
}
watershed(image, markers);
Mat wshed(markers.size(), CV_8UC3);
for(int i = 0; i < markers.rows; i++)
{
for(int j = 0; j < markers.cols; j++)
{
int index = markers.at<int>(i, j);
if(index == -1) wshed.at<Vec3b>(i, j) = Vec3b(0, 0, 0);
else if (index == 0) wshed.at<Vec3b>(i, j) = Vec3b(255, 255, 255);
else wshed.at<Vec3b>(i, j) = colorTab[index - 1];
}
}
imshow("watershed transform", wshed);
waitKey(0);
Алгоритм сегментации MeanShift
MeanShift группирует объекты с близкими признаками. Пиксели со схожими признаками объединяются в один сегмент, на выходе получаем изображение с однородными областями.


Например, в качестве координат в пространстве признаков можно выбрать координаты пикселя (x, y) и компоненты RGB пикселя. Изобразив пиксели в пространстве признаков, можно заметить сгущения в определенных местах.
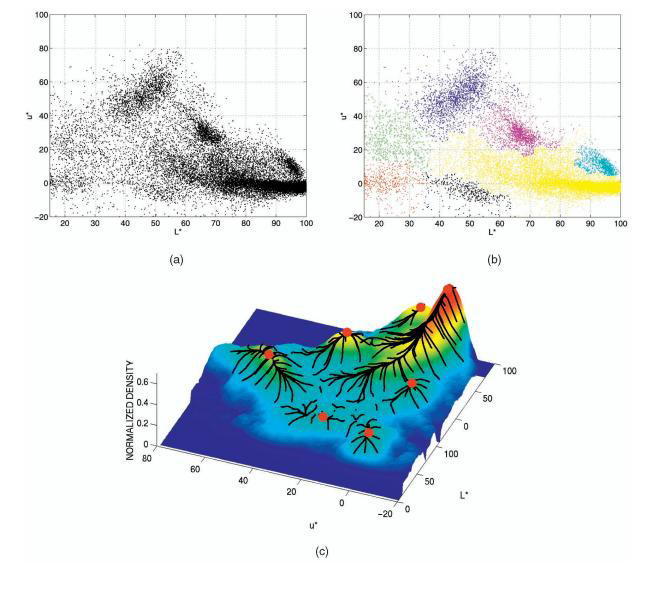
Рис. 7. (a) Пиксели в двухмерном пространстве признаков. (b) Пиксели, пришедшие в один локальный максимум, окрашены в один цвет. (с)
Чтобы легче было описывать сгущения точек, вводится функция плотности:

Оценка градиента от функции плотности
Для оценки градиента функции плотности можно использовать вектор среднего сдвига 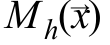
В качестве ядра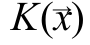 в OpenCV используется ядро Епанечникова [4]:
в OpenCV используется ядро Епанечникова [4]:

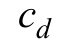 — это объем d-мерной сферы c единичным радиусом.
— это объем d-мерной сферы c единичным радиусом.

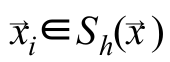 означает, что сумма идет не по всем пикселям, а только по тем, которые попали в сферу радиусом h с центром в точке, куда указывает вектор
означает, что сумма идет не по всем пикселям, а только по тем, которые попали в сферу радиусом h с центром в точке, куда указывает вектор  в пространстве признаков [4]. Это вводится специально, чтобы уменьшить количество вычислений.
в пространстве признаков [4]. Это вводится специально, чтобы уменьшить количество вычислений. 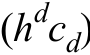 — объем d-мерной сферы с радиусом h, Можно отдельно задавать радиус для пространственных координат и отдельно радиус в пространстве цветов.
— объем d-мерной сферы с радиусом h, Можно отдельно задавать радиус для пространственных координат и отдельно радиус в пространстве цветов.  — число пикселей, попавших в сферу. Величину
— число пикселей, попавших в сферу. Величину  можно рассматривать как оценку значения
можно рассматривать как оценку значения  в области
в области  .
.
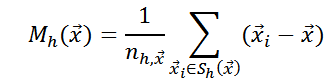
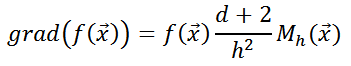
Поэтому, чтобы шагать по градиенту, достаточно вычислить значение — вектора среднего сдвига. Следует помнить, что при выборе другого ядра вектор среднего сдвига будет выглядеть иначе.
В качестве ядра
— число пикселей, попавших в сферу. Величину можно рассматривать как оценку значения Поэтому, чтобы шагать по градиенту, достаточно вычислить значение
При выборе в качестве признаков координат пикселей и интенсивностей по цветам в один сегмент будут объединяться пиксели с близкими цветами и расположенные недалеко друг от друга. Соответственно, если выбрать другой вектор признаков, то объединение пикселей в сегменты уже будет идти по нему. Например, если убрать из признаков координаты, то небо и озеро будут считаться одним сегментом, так как пиксели этих объектов в пространстве признаков попали бы в один локальный максимум.
Если объект, который хотим выделить, состоит из областей, сильно различающихся по цвету, то MeanShift не сможет объединить эти регионы в один, и наш объект будет состоять из нескольких сегментов. Но зато хорошо справиться с однородным по цвету предметом на пестром фоне. Ещё MeanShift используют при реализации алгоритма слежения за движущимися объектами [5].
Пример кода для запуска алгоритма:
Результат:

Рис. 8. Исходное изображение

Рис. 9. После сегментации алгоритмом MeanShift
Mat image = imread("strawberry.jpg", CV_LOAD_IMAGE_COLOR);
Mat imageSegment;
int spatialRadius = 35;
int colorRadius = 60;
int pyramidLevels = 3;
pyrMeanShiftFiltering(image, imageSegment, spatialRadius, colorRadius, pyramidLevels);
imshow("MeanShift", imageSegment);
waitKey(0);
Результат:
Рис. 8. Исходное изображение
Рис. 9. После сегментации алгоритмом MeanShift
Алгоритм сегментации FloodFill
С помощью FloodFill (заливка или метод «наводнения») можно выделить однородные по цвету регионы. Для этого нужно выбрать начальный пиксель и задать интервал изменения цвета соседних пикселей относительно исходного. Интервал может быть и несимметричным. Алгоритм будет объединять пиксели в один сегмент (заливая их одним цветом), если они попадают в указанный диапазон. На выходе будет сегмент, залитый определенным цветом, и его площадь в пикселях.
Такой алгоритм может быть полезен для заливки области со слабыми перепадами цвета однородным фоном. Одним из вариантов использования FloodFill может быть выявление поврежденных краев объекта. Например, если, заливая однородные области определенным цветом, алгоритм заполнит и соседние регионы, то значит нарушена целостность границы между этими областями. Ниже на изображении можно заметить, что целостность границ заливаемых областей сохраняется:


Рис. 10, 11. Исходное изображение и результат после заливки нескольких областей
А на следующих картинках показан вариант работы FloodFill в случае повреждения одной из границ в предыдущем изображении.


Рис. 12, 13. Иллюстрация работы FloodFill при нарушение целостности границы между заливаемыми областями
Пример кода для запуска алгоритма:
В переменную area запишется количество “залитых" пикселей.
Результат:


Mat image = imread("cherry.jpg", CV_LOAD_IMAGE_COLOR);
Point startPoint;
startPoint.x = image.cols / 2;
startPoint.y = image.rows / 2;
Scalar loDiff(20, 20, 255);
Scalar upDiff(5, 5, 255);
Scalar fillColor(0, 0, 255);
int neighbors = 8;
Rect domain;
int area = floodFill(image, startPoint, fillColor, &domain, loDiff, upDiff, neighbors);
rectangle(image, domain, Scalar(255, 0, 0));
imshow("floodFill segmentation", image);
waitKey(0);
В переменную area запишется количество “залитых" пикселей.
Результат:
Алгоритм сегментации GrabCut
Это интерактивный алгоритм выделения объекта, разрабатывался как более удобная альтернатива магнитному лассо (чтобы выделить объект, пользователю требовалось обвести его контур с помощью мыши). Для работы алгоритма достаточно заключить объект вместе с частью фона в прямоугольник (grab). Сегментирование объекта произойдет автоматически (cut).


Могут возникнуть сложности при сегментации, если внутри ограничивающего прямоугольника присутствуют цвета, которые встречаются в большом количестве не только в объекте, но и на фоне. В этом случае можно поставить дополнительные метки объекта (красная линия) и фона (синяя линия).



Рассмотрим идею алгоритма. За основу взят алгоритм интерактивной сегментации GraphCut, где пользователю надо поставить маркеры на фон и на объект. Изображение рассматривается как массив
 . Z — значения интенсивности пикселей, N-общее число пикселей. Для отделения объекта от фона алгоритм определяет значения элементов массива прозрачности
. Z — значения интенсивности пикселей, N-общее число пикселей. Для отделения объекта от фона алгоритм определяет значения элементов массива прозрачности 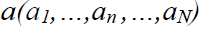 , причем
, причем  может принимать два значения, если = 0, значит пиксель принадлежит фону, если = 1, то объекту. Внутренний параметр
может принимать два значения, если = 0, значит пиксель принадлежит фону, если = 1, то объекту. Внутренний параметр 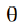 содержит гистограмму распределения интенсивности переднего плана и гистограмму фона:
содержит гистограмму распределения интенсивности переднего плана и гистограмму фона: 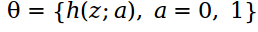 .
.Задача сегментации — найти неизвестные
. Рассматривается функция энергии: 
Причем минимум энергии соответствует наилучшей сегментации.

V (a, z) — слагаемое отвечает за связь между пикселями. Сумма идет по всем парам пикселей, которые являются соседями, dis(m,n) — евклидово расстояние.
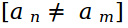 отвечает за участие пар пикселей в сумме, если a n = a m, то эта пара не будет учитываться.
отвечает за участие пар пикселей в сумме, если a n = a m, то эта пара не будет учитываться. Найдя глобальный минимум функции энергии E, получим массив прозрачности
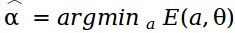 . Для минимизации функции энергии, изображение описывается как граф и ищется минимальный разрез графа. В отличие от GraphCut в алгоритме GrabCut пиксели рассматриваются в RGB пространстве, поэтому для описания цветовой статистики используют смесь гауссиан (Gaussian Mixture Model — GMM). Работу алгоритма GrabCut можно посмотреть, запустив сэмпл OpenCV grabcut.cpp.
. Для минимизации функции энергии, изображение описывается как граф и ищется минимальный разрез графа. В отличие от GraphCut в алгоритме GrabCut пиксели рассматриваются в RGB пространстве, поэтому для описания цветовой статистики используют смесь гауссиан (Gaussian Mixture Model — GMM). Работу алгоритма GrabCut можно посмотреть, запустив сэмпл OpenCV grabcut.cpp. Мы рассмотрели только небольшую часть существующих алгоритмов. В результате сегментации на изображении выделяются области, в которые объединяются пиксели по выбранным признакам. Для заливки однородных по цвету объектов подойдет FloodFill. С задачей отделения конкретного объекта от фона хорошо справится GrabCut. Если использовать реализацию MeanShift из OpenCV, то пиксели, близкие по цвету и координатам, будут кластеризованы. WaterShed подойдет для изображений с простой текстурой. Таким образом, алгоритм сегментации следует выбирать, конечно, исходя из конкретной задачи.
Литература:
- G. Bradski, A. Kaehler Learning OpenCV: OReilly, second edition 2013
- Р. Гонсалес, Р. Вудс Цифровая обработка изображений, Москва: Техносфера, 2005. – 1072 с.
- D. Comaniciu, P. Meer Mean Shift: A Robust Approach Toward Feature Space Analysis. IEEE Transactions on Pattern Analysis and Machine Intelligence, 2002, pp. 603–619.
- D. Comaniciu, P. Meer Mean shift analysis and applications, IEEE International Conference on Computer Vision, 1999, vol. 2, pp. 1197.
- D. Comaniciu, V. Ramesh, P. Meer Real-Time Tracking of Non-Rigid Objects Using Mean Shift, Conference on CVPR, 2000, vol. 2, pp. 1-8.
- С. Rother, V. Kolmogorov, A. Blake Grabcut — interactive foreground extraction using iterated graph cuts, 2004
- Сэмплы OpenCV
