Библиотеки, реализующие стандарт MPI (Message Passing Interface) — наиболее популярный механизм организации вычислений на кластере. MPI позволяет передавать сообщения между узлами (серверами), но никто не мешает запускать несколько MPI процессов и на одном узле, реализуя потенциал нескольких ядер. Так часто и пишутся HPC приложения, так проще. И пока количество ядер на одном узле было мало, никаких проблем с «чистым MPI» подходом не было. Но сегодня количество ядер идёт на десятки, а то и на сотни для со-процессоров Intel Xeon-Phi. И в такой ситуации запуск десятков процессов на одной машине становится не совсем эффективным.
Дело в том, что MPI процессы общаются через сетевой интерфейс (хоть и реализованный через общую память на одной машине). Это влечет за собой избыточные копирования данных через множество буферов и увеличенный расход памяти.
Для параллельных вычислений внутри одной машины с общей памятью гораздо лучше подходят потоки и распределение задач между ними. Здесь наибольшей популярностью в мире HPC пользуется стандарт OpenMP.
Казалось бы – ладно, используем OpenMP внутри узла, и MPI для меж-узловых коммуникаций. Но не всё так просто. Использование двух фреймворков (MPI и OpenMP) вместо одного не только несёт дополнительную сложность программирования, но и не всегда даёт желаемый прирост производительности – по крайней мере, не сразу. Нужно ещё решить, как распределить вычисления между MPI и OpenMP, и, возможно, решить проблемы, специфичные для каждого уровня.
В этой статье я не буду описывать создание гибридных приложений – информацию найти не сложно. Мы рассмотрим, как можно анализировать гибридные приложения с помощью инструментов Intel Parallel Studio, выбирая оптимальную конфигурацию и устраняя узкие места на разных уровнях.
Для тестов будем использовать NASA Parallel Benchmark:
- CPU: Intel Xeon processor E5-2697 v2 @ 2.70GHz, 2 сокета, 12 ядер в каждом.
- OS: RHEL 7.0 x64
- Intel Parallel Studio XE 2016 Cluster Edition
- Компилятор: Intel Compiler 16.0
- MPI: Intel MPI library 5.1.1.109
- Workload: NPB 3.3.1, “CG — Conjugate Gradient, irregular memory access and communication” module, class B
Бенчмарк уже реализован гибридным и позволяет конфигурировать количество MPI процессов и OpenMP потоков. Понятно, что для меж-узловых коммуникаций альтернативы MPI тут нет (в рамках нашего приложения). Интрига в том, что запускать на одном узле – MPI или OpenMP.
MPI Performance Snapshot
У нас в распоряжении 24 ядра. Начнём с традиционного подхода – только MPI. 24 MPI процесс, по 1 потоку на каждый. Для анализа программы воспользуемся новым инструментом, вышедшим в последней версии Intel Parallel Studio – MPI Performance Snapshot. Просто добавляем ключ “-mps” в строку запуска mpirun:
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh
source /opt/intel/itac/9.1.1.017/intel64/bin/mpsvars.sh --vtune
mpirun -mps –n 24 ./bt-mz.B.24
mps -g stats.txt app_stat.txt _mps
Первые две строки выставляют нужное окружение, третья запускает программу с профилировкой MPS. Последняя строка формирует отчёт в формате html. Без -g отчёт будет выведен на консоль – удобно для просмотра сразу на кластере, но в HTML красивее:


MPS даёт верхнеуровневую оценку производительности. Накладные расходы на его запуск крайне малы, можно быстро сделать оценку приложения даже на больших масштабах (протестировано 32000 процессов).
Для начала смотрим доли MPI time и Computation time. У нас 32% времени уходит на MPI, почти всё из-за дисбаланса нагрузки – одни процессы ждут, пока другие считают. В блоках справа приводится оценка – время MPI помечено HIGH – слишком много тратиться на коммуникацию. Там же есть отсылка к другому инструменту – Intel Trace Analyzer and Collector (ITAC), для детального анализа MPI проблем. Про OpenMP никаких проблем не подсвечено, что неудивительно, ведь мы его фактически выключили.
MPS также считает аппаратные метрики эффективности: GFPLOS, CPI и метрику “Memory Bound” – общую оценку эффективности работы с памятью. А ещё потребление памяти (для одного MPI процесса) – максимальное и среднее.
Intel Trace Analyzer and Collector
MPS показал, что основная проблема в конфигурации “24х1” в MPI. Для выяснения причин собираем профиль ITAC:
source /opt/intel/itac/9.1.1.017/intel64/bin/itacvars.sh
mpirun -trace -n 24 ./bt-mz.B.24
Открываем трассу в ITAC GUI – я пользовался Windows версией. На графике Quantitative Timeline отчётливо видно, что доля MPI велика, и коммуникации распределены с некоторой цикличностью. Самый верхний график показывает периодические всплески MPI активности:

Если выделить несколько таких всплесков на шкале Event Timeline, можно наблюдать, что коммуникации распределены неравномерно. Процессы с рангами 0-4 больше считают, а с рангами 15-23 больше ждут. Дисбаланс нагрузки налицо:

На графике Message Profile можно оценить, какие именно процессы обмениваются сообщениями и где коммуникация наиболее долгая:
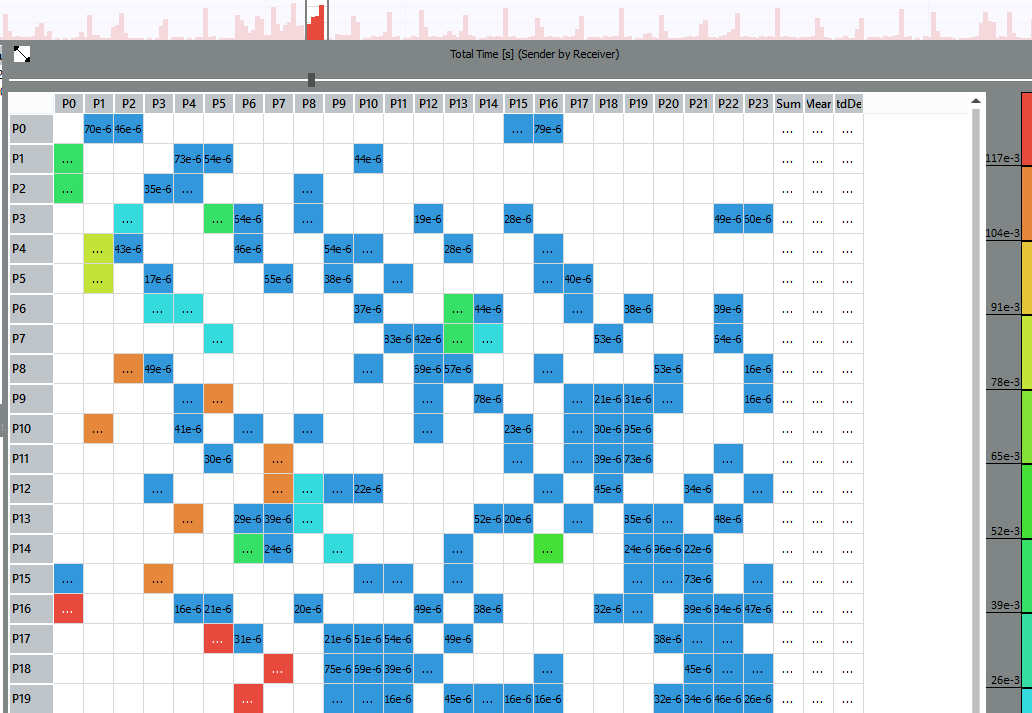
Например, дольше других проходят сообщения между процессами с рангами 17 и 5, 16 и 0, 18 и 7, и т.д. Увеличив ещё сильнее Event Timeline, можно кликнуть по чёрной линии на 17-м ранге и посмотреть детали пересылки – от кого кому, размер сообщения, вызовы отправки и получения:

Панель Performance Assistant описывает конкретные проблемы, найденные инструментом в выделенном регионе. Например, «поздняя отсылка»:

Дисбаланс в MPI может быть вызван не только недостатками в коммуникационной схеме, но и проблемами в полезных вычислениях – когда одни процессы считают медленнее других. Если мы заинтересовались, на что это приложение тратит время внутри какого-то из процессов, и в чём могут быть проблемы, ITAC может сгенерировать командную строку для запуска Intel VTune Amplifier для этого ранга (например, на 2-го):
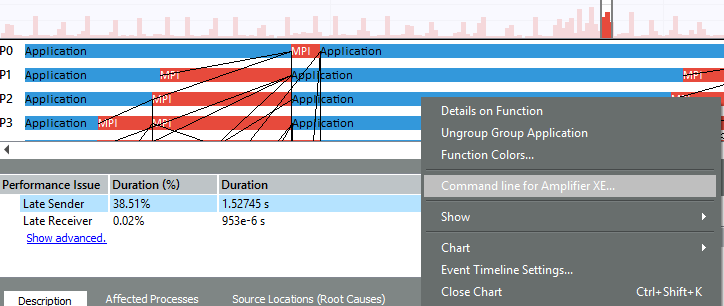

Но к VTune Amplifier вернёмся позже. Да и вообще, ITAC даёт массу возможностей для детального исследования MPI коммуникаций, но наша задача сейчас – выбрать оптимальный баланс между OpenMP и MPI. А для этого необязательно сразу исправлять MPI коммуникации на 24-х рангах – можно для начала попробовать другие варианты.
Другие варианты

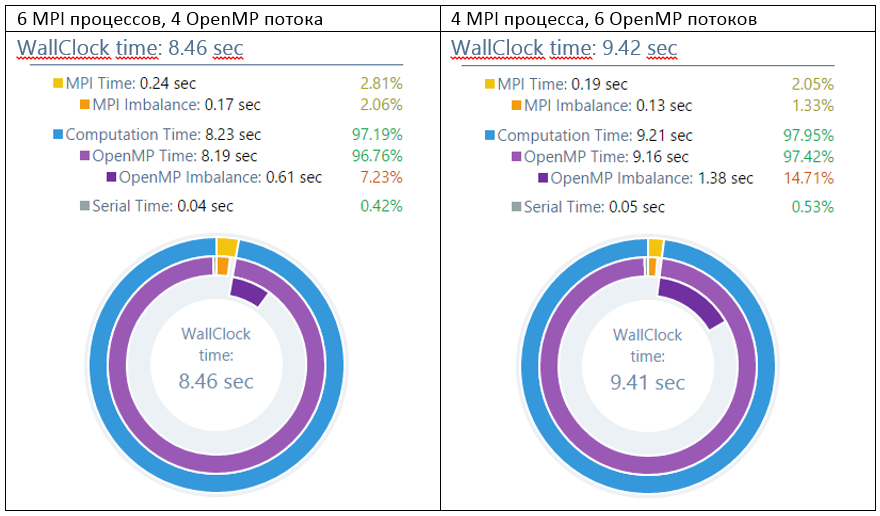
Итак, эмпирическим путём получилось, что распределения 12х2 и 6х4 работают лучше других. Даже 2 OpenMP потока на каждый процесс существенно быстрее, чем 2 MPI процесса. Однако, с ростом числа потоков время работы снова начинает расти: 2х12 ещё хуже, чем «чистый MPI», а 1х24 даже приводить нет смысла. И виной всему дисбаланс работы, которая плохо распределяется по большому количеству OpenMP потоков. Вариант 2х12 имеет аж 30% дисбаланса.
Здесь мы вполне может остановиться, т.к. достигнутый компромисс 12х2 или 6х4 вполне приемлем. Но можно и копнуть глубже — поисследовать, в чём проблема с OpenMP масштабированием.
VTune Amplifier
Для детального анализа проблем OpenMP отлично подойдёт Intel VTune Amplifier XE, о чём мы уже писалиподробно.
source /opt/intel/vtune_amplifier_xe/amplxe-vars.sh
mpirun -gtool "amplxe-cl -c advanced_hotspots -r my_result:1" -n 24 ./bt-mz.B.24
Для запуска анализаторов, таких как VTune Amplifier и Intel Advisor XE, стало очень удобно пользоваться синтаксисом опции gtool (только в Intel MPI). Она встраивается в строку запуска MPI приложения, позволяя запускать анализ лишь на выбранных процессах – в нашем примере только для ранга 1.
Посмотрим на профиль варианта “2 MPI процесса, 12 OpenMP потоков”. В одном из наиболее затратных параллельных циклов 0.23 секунды из 1.5 уходит на дисбаланс. Дальше в таблице видно, что тип диспетчеризации статический, перераспределения работы не происходит. Кроме того, в цикле всего 41 итерация, а в соседних циклах 10-20 итераций. Т.е. при 12 потоках каждому достанется всего 3-4 итерации. Видимо, этого не достаточно для эффективного баланса нагрузки.
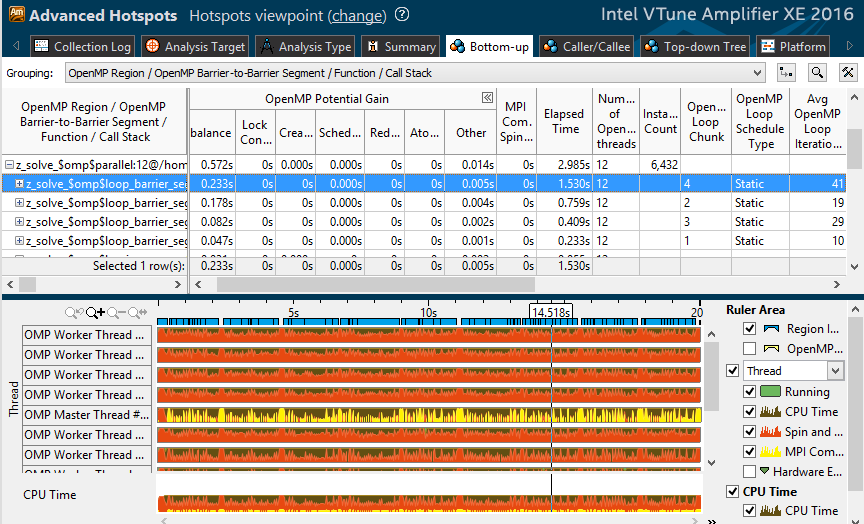
При 2-4 потоках каждому из них достаётся больше работы, и относительное время активного ожидания, вызванного дисбалансом, снижается. Что подтверждается профилем “6х4” – imbalance значительно ниже:

Кроме того, в версии Intel VTune Amplifier 2016 появилось время MPI – колонка «MPI Communication Spinning» и жёлтая разметка на временной шкале. Можно запустить профиль VTune сразу для нескольких процессов на одном узле, и наблюдать MPI spinning вместе с OpenMP метриками в каждом из них:


Intel Advisor XE
Спускаясь ниже по уровням параллелизма, от масштаба кластера (MPI), до потоков одного узла (OpenMP) добираемся до параллелизма по данным внутри одного потока – векторизации, основанной на SIMD инструкциях. Здесь тоже может быть серьёзный потенциал для оптимизации, однако не зря мы добрались до него в последнюю очередь – сначала нужно решить проблемы на уровнях MPI и OpenMP, т.к. там потенциально можно больше выиграть. Про Advisor не так давно было два поста (первый и второй), поэтому здесь я ограничусь строкой запуска:
source /opt/intel/advisor_xe/advixe-vars.sh
mpirun -gtool "advixe-cl -collect survey --project-dir ./my_proj:1" -n 2 ./bt-mz.2
Дальше проводим анализ векторизации кода, как мы писали раньше. Advisor составляет важную часть экосистемы анализа кластерных MPI программ. Кроме глубокого исследования векторизации кода, Advisor помогает прототипировать многопоточное исполнение и проверяет шаблоны доступа к памяти.
Резюме
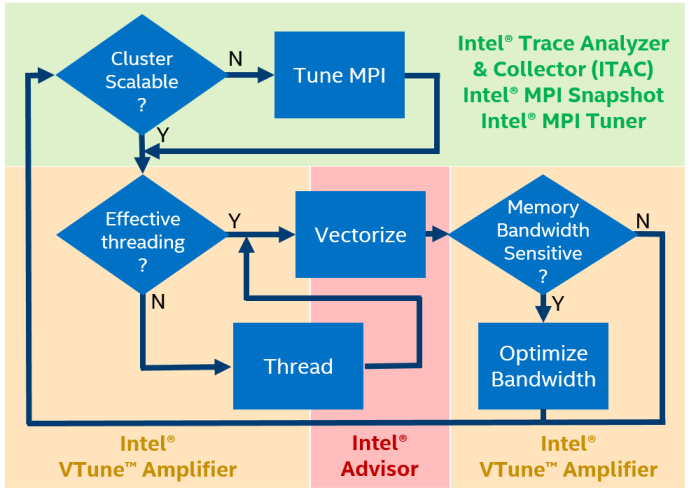
Intel Parallel Studio предлагает четыре инструмента для анализа производительности гибридных HPC приложений:
- MPI Performance Snapshot (уровень кластера) — быстрая оценка эффективности, минимальные накладные расходы, профилировка до 32000 MPI процессов, быстрая оценка дисбаланса MPI и OpenMP, общая оценка производительности (GFLOPS, CPI).
- Intel Trace Analyzer and Collector (уровень кластера) – детальное исследование MPI, выявление шаблонов коммуникации, локализация конкретных узких мест.
- Intel VTune Amplifier XE (уровень одного узла) – детальный профиль с исходным кодом и стэками, дисбалансы и другие проблемы OpenMP, анализ использования кэша и памяти и многое другое.
- Intel Advisor XE (уровень одного узла) – анализ использования векторных инструкций и выявление причин их неэффективности, прототипирование многопоточного исполнения, анализ шаблонов доступа к памяти.