Comments 20
у вас есть сравнение по gcc (с++) vs intel ps xe (тоже c++)? по той же скорости и компиляции, и исполнения скомпилированного в результате? не идеальные кони в вакууме для измерения, а нечто живое? ну, тот же майнинг. за какое время окупится приобретение вашего компилятора?
Да, это конечно важный вопрос. Показывать насколько хорош в плане производительности компилятор принято на общеизвестных тестах/бенчмарках. Так принято в индустрии. Эти тесты могут быть как «идеальными конями в вакууме», так и более сложными, приближенными к реальной жизни (они разные). Для С++ мы часто ориентируемся на SPEC, и в посте про прошлую версию 17.0 я давал данные по производительности на этой бенчмарке:
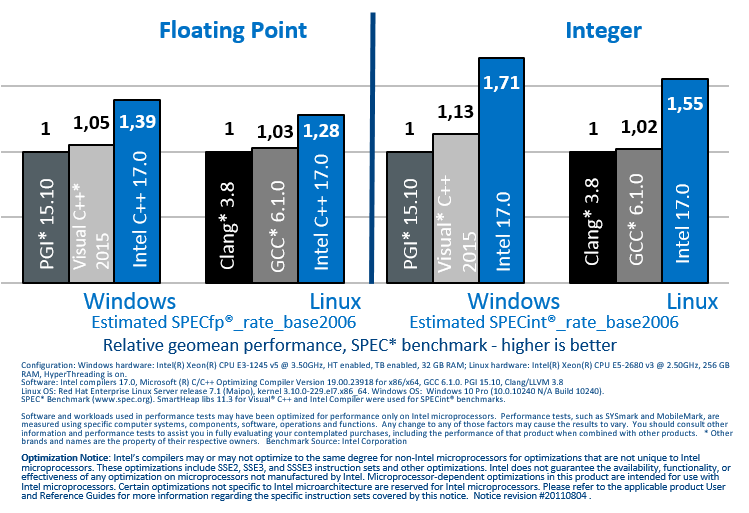
На конкретном железе и с данными версиям компилятора выигрыш был ощутимый (порядка 60% с Microsoft и 50 с GNU).
Для 18 версии данные тоже будут подготовлены позднее и, думается, сравнивать будем уже с 2017 версией.
Но если есть желание понять, какой будет прирост на именно вашем приложении (а это то, что обычно интересует разработчиков, а не цифры про «вакуум»), то имеет смысл просто качнуть тестовую бесплатную версию (для этого она у нас и есть) и посмотреть своими глазами. Обычно, поиграв с опциями из этого поста, можно весьма неплохо разогнаться.
На конкретном железе и с данными версиям компилятора выигрыш был ощутимый (порядка 60% с Microsoft и 50 с GNU).
Для 18 версии данные тоже будут подготовлены позднее и, думается, сравнивать будем уже с 2017 версией.
Но если есть желание понять, какой будет прирост на именно вашем приложении (а это то, что обычно интересует разработчиков, а не цифры про «вакуум»), то имеет смысл просто качнуть тестовую бесплатную версию (для этого она у нас и есть) и посмотреть своими глазами. Обычно, поиграв с опциями из этого поста, можно весьма неплохо разогнаться.
есть вопросы:
1. возвращаете ли вы что-нибудь существенное в gcc/llvm регулярно?
2. вы же читаете исходники gcc/llvm, анализируете их? так вот: знаете ли вы сами, почему ваш компиллер делает более быстрый код? видите ли вы просчёты в gcc/llvm?
3. за счёт чего такой разрыв в скорости скомпиленных приложений (до полутора раз по вашим словам)? это особенности процессоров интел, которые известны только вам?
или это общие алгоритмы, общие системные решения, которые у вас проработаны лучше?
а может это потому, что gcc/llvm, как открытые системы, основаны на «красивых» решениях, а ваши закрытые компиляторы могут себе позволить… ну, скажем, некрасивый код, и за счёт этого могут получать преимущество?
4. превосходство достигается только на процессорах интел (я только про x86-64) или на процессорах амд тоже? может и для арм ваш компайлер может лучше? (я пока не качал и не пробовал)
1. возвращаете ли вы что-нибудь существенное в gcc/llvm регулярно?
2. вы же читаете исходники gcc/llvm, анализируете их? так вот: знаете ли вы сами, почему ваш компиллер делает более быстрый код? видите ли вы просчёты в gcc/llvm?
3. за счёт чего такой разрыв в скорости скомпиленных приложений (до полутора раз по вашим словам)? это особенности процессоров интел, которые известны только вам?
или это общие алгоритмы, общие системные решения, которые у вас проработаны лучше?
а может это потому, что gcc/llvm, как открытые системы, основаны на «красивых» решениях, а ваши закрытые компиляторы могут себе позволить… ну, скажем, некрасивый код, и за счёт этого могут получать преимущество?
4. превосходство достигается только на процессорах интел (я только про x86-64) или на процессорах амд тоже? может и для арм ваш компайлер может лучше? (я пока не качал и не пробовал)
Компилятор просто делает ряд оптимизаций лучше, в частности, максимальный прирост даёт векторизация. Если её отключать в нашем компиляторе, то это большой вопрос, будет ли прирост (даже если отключить её для сравнения и в других компиляторах). Векторизатор умеет распознавать достаточно сложные конструкции, и на выходе мы имеем большее число циклов, которые используют регистры по «максимуму», и при этом с использованием последних инструкций. Конечно, и другие оптимизации могут «додавать» производительности, но это ключевая.
Безусловно, у компиляторов Intel есть опции для оптимизации под конкретную микроархитектуру, и здесь мы тоже получим дополнительное преимущество. Тем не менее, возможность сгенерировать код под другие процессоры тоже есть. Возможно, где-то выложены сравнения компиляторов и на других процессорах, мы это не отслеживаем.
В целом, высокая производительность получаемого кода всегда была и остается основным преимуществом Интеловских компиляторов, поэтому сюда и инвестируется много ресурсов/времени.
У gcc есть ряд своих преимуществ, например доступность, открытость кода, поддержка языковых стандартов (появляется чуть раньше, чем у нас).
Безусловно, у компиляторов Intel есть опции для оптимизации под конкретную микроархитектуру, и здесь мы тоже получим дополнительное преимущество. Тем не менее, возможность сгенерировать код под другие процессоры тоже есть. Возможно, где-то выложены сравнения компиляторов и на других процессорах, мы это не отслеживаем.
В целом, высокая производительность получаемого кода всегда была и остается основным преимуществом Интеловских компиляторов, поэтому сюда и инвестируется много ресурсов/времени.
У gcc есть ряд своих преимуществ, например доступность, открытость кода, поддержка языковых стандартов (появляется чуть раньше, чем у нас).
Тем не менее, возможность сгенерировать код под другие процессоры тоже есть.
Нашумевшая история
Есть-то она есть, но была не хорошая история, когда не зависимо от поддержки процессором векторных инструкций они эмулировались софтово, на платформах отличных от Интел. Даже выпускали патчеры-активаторы, настолько много было на рынке «медленных» бинарников в коммерческих проектах. Как обстоит с этим дело на современном уровне, пруфы, что всё норм есть?
Пардон за много букв. Более короткий ответ — обычно мы не хуже gcc, а если ваш тест покажет обратное — вам точно нужно связаться с нами, и, очень вероятно, это будет исправлено. В поддержке кроется весомое преимущество.
Вот пример сходу. Есть такой крошечный тест — рекурсивное вычисление факториала (практической ценности, разумеется, не имеет):
На одном и том же железе (и системе) файл сгенерированный gcc работает 7с, в то время как сгенерированный icc (17.0.4) — 16с. Более чем в два раза медленнее! В обоих случаях использовалась только одна опция, -O3. Если использовать -xHost для icc то результат 14с. Лучше, чем 16, но все равно в два раза медленнее. Пример, конечно, банальный, но разница тоже не маленькая…
#include <stdio.h>
long fib(long n) {
if (n < 2)
return 1;
return fib(n-2) + fib(n-1);
}
int main(int argc, char const* argv[]) {
printf("%ld\n", fib(47));
return 0;
}
На одном и том же железе (и системе) файл сгенерированный gcc работает 7с, в то время как сгенерированный icc (17.0.4) — 16с. Более чем в два раза медленнее! В обоих случаях использовалась только одна опция, -O3. Если использовать -xHost для icc то результат 14с. Лучше, чем 16, но все равно в два раза медленнее. Пример, конечно, банальный, но разница тоже не маленькая…
Только что протестировал:
$ gcc --version
gcc (GCC) 6.2.0
Copyright © 2016 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ gcc test.c
$ time ./a.out
4807526976
real 0m15.512s
user 0m15.465s
sys 0m0.000s
$ icc -V
Intel® C Intel® 64 Compiler for applications running on Intel® 64, Version 17.0.4.196 Build 20170411
Copyright © 1985-2017 Intel Corporation. All rights reserved.
$ icc test.c
$ time ./a.out
4807526976
real 0m10.567s
user 0m10.529s
sys 0m0.000s
$ gcc --version
gcc (GCC) 6.2.0
Copyright © 2016 Free Software Foundation, Inc.
This is free software; see the source for copying conditions. There is NO
warranty; not even for MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE.
$ gcc test.c
$ time ./a.out
4807526976
real 0m15.512s
user 0m15.465s
sys 0m0.000s
$ icc -V
Intel® C Intel® 64 Compiler for applications running on Intel® 64, Version 17.0.4.196 Build 20170411
Copyright © 1985-2017 Intel Corporation. All rights reserved.
$ icc test.c
$ time ./a.out
4807526976
real 0m10.567s
user 0m10.529s
sys 0m0.000s
Ну и стоит сказать, что на таких тестах не стоит ожидать большей производительности, векторизации здесь нет.
Я тоже только что повторил тест без флагов оптимизации: gcc — 17.8, icc — 14,0. То есть что касается icc то -O3 вообще не оказыват влияния на результат в данном случае, а вот gcc ускоряется почти в три раза. Проведите тест с флагом -O3, как я и писал в самом начале. Для полноты картины:
gcc -O3 fib.c -o fib-gcc
icc -O3 -xHost fib.c -o fib-icc
Да, векторизации тут нет и именно это и интересно — тестируются только самые базовые элементы языка. Я не представляю какие тут вообще возможны варианты кроме уровня оптимизации, и тем не менее разница в два раза.
gcc -O3 fib.c -o fib-gcc
icc -O3 -xHost fib.c -o fib-icc
Да, векторизации тут нет и именно это и интересно — тестируются только самые базовые элементы языка. Я не представляю какие тут вообще возможны варианты кроме уровня оптимизации, и тем не менее разница в два раза.
Да, с О3 интеловский компилятор уже медленнее. Нужно посмотреть, что делал gcc с O3.
Но опять таки — без векторизации не стоит ожидать чудес от компилятора.
Но опять таки — без векторизации не стоит ожидать чудес от компилятора.
Сам по себе этот пример, конечно, малореалистичный, но все-таки разница в два раза это как-то слишком. Просто интересно за счет чего — как я уже говорил, тут используются уж очень базовые элементы языка, вроде бы никаких вариаций быть не должно, но тем не менее разница в два раза.
Сам я, к сожалению, не обладаю достаточной квалификацией чтобы быстро прояснить эту ситуацию, так что если кто доступно объяснит — было бы любопытно узнать )
Сам я, к сожалению, не обладаю достаточной квалификацией чтобы быстро прояснить эту ситуацию, так что если кто доступно объяснит — было бы любопытно узнать )
а в дизассемблере что? не может быть, чтобы такой простой код рождал какие-то сильно разные инструкции. профилировать? может просто долгий старт или долгое завершение?
Ну дизассемблер нам не нужен, раз у нас в руках компилятор есть. Можно сразу посмотреть ассемблер. Быстро глянул, и заметил, что в случае с дефолтными опциями оба компилятора генерят примерно одинаковый код для main, вызывая fib. А вот c O3 gcc придумал что-то поинтереснее — он там организовал цикл для вызова fib:
А по дефолту это выглядело так:
В icc похожее на дефолтное у gcc. Нужно взять VTune и посмотреть более детально, могу даже пост про это написать. Но мне думается, что мы просто похуже работаем с рекурсиями, потому что они не очень то востребованы — только в образовательных целях.
main:
.LFB12:
subq $8, %rsp
.LCFI15:
movl $45, %esi
xorl %r8d, %r8d
.p2align 4,,10
.p2align 3
.L46:
cmpq $1, %rsi
jbe .L47
leaq -2(%rsi), %rdx
xorl %ecx, %ecx
.p2align 4,,10
.p2align 3
.L45:
movq %rdx, %rdi
call fib
subq $1, %rdx
addq %rax, %rcx
cmpq $-1, %rdx
jne .L45
addq $1, %rcx
.L44:
subq $1, %rsi
addq %rcx, %r8
cmpq $-1, %rsi
jne .L46
leaq 1(%r8), %rsi
movl $.LC0, %edi
xorl %eax, %eax
call printf
xorl %eax, %eax
addq $8, %rsp
.LCFI16:
ret
А по дефолту это выглядело так:
main:
.LFB1:
pushq %rbp
.LCFI4:
movq %rsp, %rbp
.LCFI5:
subq $16, %rsp
movl %edi, -4(%rbp)
movq %rsi, -16(%rbp)
movl $47, %edi
call fib
movq %rax, %rsi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.LCFI6:
ret
В icc похожее на дефолтное у gcc. Нужно взять VTune и посмотреть более детально, могу даже пост про это написать. Но мне думается, что мы просто похуже работаем с рекурсиями, потому что они не очень то востребованы — только в образовательных целях.
icc делает всё «в лоб», то есть
a0 = fib(43);
a1 = fib(42);
a2 = fib(43);
a3 = fib(44);
a4 = fib(45);
А можно было бы оптимизировать так:
a0 = fib(43);
a1 = fib(42);
a2 = a0
a3 = a2 + a1;
a4 = fib(45);
a4 = a3 + a0
a0 = fib(43);
a1 = fib(42);
a2 = fib(43);
a3 = fib(44);
a4 = fib(45);
А можно было бы оптимизировать так:
a0 = fib(43);
a1 = fib(42);
a2 = a0
a3 = a2 + a1;
a4 = fib(45);
a4 = a3 + a0
Собственно, подобное и делает gcc, и кэширует часть вычислений. Возможно, что в 18 версии (не Бета) на этом примере мы тоже сделаем подобное, ведь не просто так я копался сидел.
Спасибо за объяснение! Конечно, такой пример сам по себе вряд ли встретится в реальном коде, но подобная оптимизация может быть полезна для целого класса более реалистичных алгоритмов. Я это расхождение между gcc и icc заметил давно, просто руки не доходили об этом написать, но вот сегодня наткнулся на этот пост… Меня это всегда удивляло — тут ничего не распараллеливается, ничего не векторизуются, тут просто нет опций которые можно комбинировать и смотреть что получится. Оказывается, все не так уж загадочно )
И ещё одно замечание «вдогонку». В вопросе так же был интерес в самом времени компиляции, а не только выполнении. И вот тут у нас должен быть ощутимый прогресс в 18 версии, поскольку было пофикшено несколько подобных проблем (как в сравнении с gcc, так и с Visual C++, когда мы существенно дольше собирали код).
Но это всегда оборотная сторона медали — если хочешь, чтобы компилятор хорошо (читай как дольше) оптимизировал код, а приложение потом хорошо (читай как быстро) исполнялось — придётся где-то тратить больше времени (или на этапе компиляции, или выполнения).
Но это всегда оборотная сторона медали — если хочешь, чтобы компилятор хорошо (читай как дольше) оптимизировал код, а приложение потом хорошо (читай как быстро) исполнялось — придётся где-то тратить больше времени (или на этапе компиляции, или выполнения).
Sign up to leave a comment.
Новые «плюшки» компилятора – безопасней, быстрее, совершеннее