
Представьте, что вам надо вызвать такси. Вы открываете приложение, видите, что машина приедет минут через семь, нажимаете «Заказать» — и… автомобиль в 15 минутах от вас, если вообще найден. Согласитесь, неприятно?
Под катом поговорим о том, как методы машинного обучения помогают Яндекс.Такси более качественно прогнозировать ETA (Estimated Time of Arrival — ожидаемое время прибытия).

Для начала напомним, что пользователь видит в приложении перед заказом:
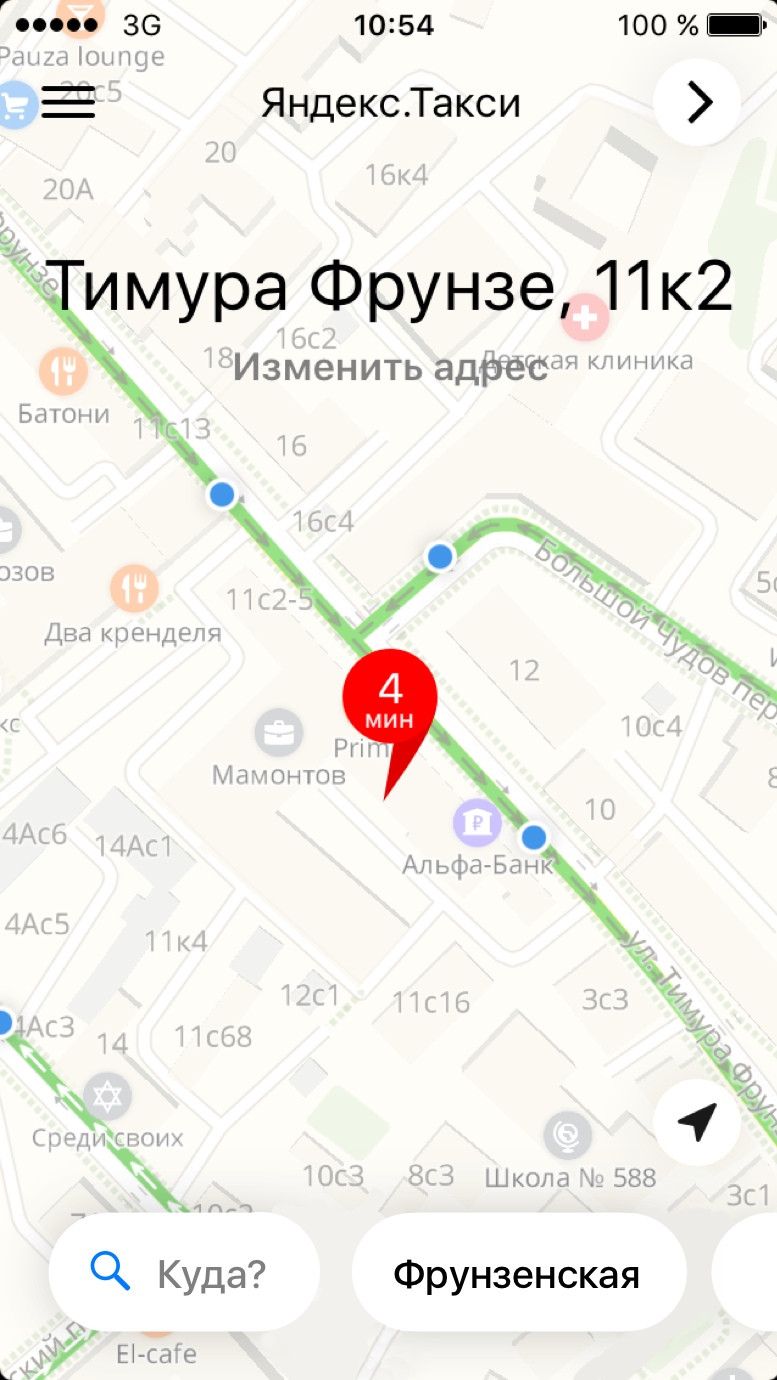
На карте синим отмечены оптимальные точки для посадки в такси. Красный пин — точка, к которой пользователь вызывает такси. В пине отображается, через какое время прибудет машина. В идеальном мире. Но в реальном мире другие люди неподалеку тоже вызывают себе машину через приложение Яндекс.Такси. И мы не знаем, какой автомобиль к кому поедет, ведь они распределяются только после заказа. Если машина уже назначена, для прогноза мы воспользуемся роутингом Яндекс.Карт и временем при движении по оптимальному пути. Это время (возможно, с небольшим запасом) мы и покажем пользователю сразу после заказа. Остается вопрос: а как же спрогнозировать ETA до заказа?
И здесь появляется машинное обучение. Составим выборку с объектами и правильными ответами и обучим алгоритм угадывать ответ по признакам объекта. В нашем случае объекты — это пользовательские сессии, ответы — это время, через которое фактически приехала машина. Признаками объекта могут быть числовые параметры, известные до заказа: количество водителей и пользователей приложения рядом с пином, расстояние до ближайших автомобилей сервиса и другие потенциально полезные величины.
В идеальном мире люди все делают заранее и всегда безошибочно планируют свое время. Но мы живем в реальном мире. Если человек опаздывает на работу или, хуже того, в аэропорт, ему важно понимать, успеет ли он вовремя выехать и добраться до места назначения.
Решая, что заказать, будущий пассажир руководствуется в том числе временем ожидания. Оно может сильно отличаться и в разных приложениях для вызова такси, и в разных тарифах одного приложения. Чтобы пользователь не пожалел о выборе, очень важно показывать точное ЕТА.
Кажется, все просто. Придумать побольше признаков, обучить модель, например CatBoost, спрогнозировать время до прибытия машины — и можно закончить на этом. Но опыт показывает, что лучше не спешить и хорошенько подумать, а потом делать.
Сначала мы не сомневались, что нужно прогнозировать то время, через которое к пользователю фактически приедет водитель. Да, до заказа мы не знаем наверняка, какая именно машина будет назначена. Но мы можем предсказать ETA, используя данные не о конкретном водителе, а о водителях поблизости от заказа. Разумеется, прогноз должен быть достаточно честным, чтобы пользователь мог планировать время.
Но что значит «честным»? Ведь любой алгоритм прогнозирования плох или хорош только статистически. Встречаются и удачные, и откровенно плохие результаты, но нужно «в среднем» не сильно отклоняться от правильных ответов. Здесь надо понимать, что «в среднем» бывает разное. Например, среднее — это как минимум три понятия из статистики: матожидание, медиана и мода. Картинка из великолепной книги Дарелла Хаффа «Как лгать при помощи статистики» прекрасно показывает различие:

Мы хотим, чтобы модель в среднем ошибалась мало. В зависимости от значения «в среднем» возникает два варианта оценки качества прогнозов. Первый вариант — показывать пользователю математическое ожидание времени до приезда такси. В итоге обучится модель, минимизирующая средний квадрат ошибки прогноза (Mean Squared Error, MSE):
Здесь — правильные ответы,
— правильные ответы,  — прогнозы модели.
— прогнозы модели.
Другой вариант — не ошибаться с прогнозом ETA преимущественно в одну сторону, в большую или в меньшую. В этом случае мы покажем пользователю медиану распределения времени до приезда такси. В итоге обучится модель, оптимизирующая средний модуль ошибки прогноза (Mean Absolute Error, MAE):
Но мы поняли, что немного забегаем вперед.
После назначения мы знаем, какая именно машина едет к пользователю, а значит, можем оценить ее время в пути по Яндекс.Картам. Это время и показывается в пине после заказа. С одной стороны, теперь у нас больше информации и прогноз будет точнее, но, с другой стороны, это тоже оценка с погрешностью.
Вот в чем оказался подвох в задаче про ЕТА в пине. Пока водитель не назначен, надо прогнозировать именно то время, которое потом покажет роутинг Яндекс.Карт, а не фактическое время до подачи машины.
Казалось бы, что за чушь: вместо точного значения брать в качестве таргета другой прогноз? Но это имеет смысл, и вот почему. По пути к вам назначенная машина может задержаться. Водитель попал в опасную ситуацию на дороге, в пробку из-за ДТП или вышел купить воды. Такие задержки сложно предугадать. Они создают дополнительный шум в целевой переменной, из-за которого и без того непростая задача спрогнозировать ЕТА в пине становится еще сложнее.
Как избавиться от шума? Прогнозировать сглаженную целевую переменную — время, которое показывается уже после назначения машины на основе маршрута к пользователю.
В этом есть логика и с точки зрения бизнеса: время в дороге по оптимальному пути из ETA в любом случае не выкинешь, а вот дополнительные задержки можно уменьшать, работая с водителями.
Мы выяснили, что для ЕТА в пине нужно прогнозировать не фактическое время, а время, которое будет получено после назначения машины по маршруту. Из двух метрик качества, MAE и MSE, мы выбрали MAE. Возможно, с точки зрения интуитивности прогноза более логично оценивать матожидание (MSE), а не медиану (MAE). Но у MAE есть приятная особенность: модель более устойчива к выбросам (outliers) среди обучающих примеров.
Признаки делятся на группы:
— построенные по текущему времени;
— гео (координаты, расстояние до центра города и значимых объектов на карте);
— пиновые (сколько и каких машин рядом, по-разному подсчитанная их плотность);
— статистика по зоне (как обычно ошибаемся, сколько предсказываем);
— данные о ближайших водителях (за какое время доезжают, насколько первый ближе второго и т.п.).
На этих признаках обучали, конечно же, CatBoost. Решающим доводом было то, что реализованный в CatBoost градиентный бустинг над сбалансированными деревьями уже давно зарекомендовал себя как очень мощный метод машинного обучения, а способ кодирования категориальных признаков в CatBoost регулярно оправдывает себя на наших задачах. Другая приятная особенность библиотеки — быстрое обучение на GPU.
Теперь пара слов о том, какие модели сравнивались. Исходное ЕТА (до уточнения машинным обучением) рассчитывалось на основе времени, за которое может приехать ближайшая к пользователю машина. Текущая модель (используется в приложении сейчас) — то, что получилось сделать с помощью машинного обучения и чему посвящена эта статья. Кроме того, в продакшн скоро выкатится новая модель. Она использует на порядок больше значимых для решения задачи признаков. В таблице ниже приводятся замеры качества этих моделей на исторических данных. К слову, у нас планов ещё много — приходите помогать.
Качество прогноза ETA на валидации*
* В процентах (в скобках указано изменение по сравнению с исходным ETA).
Машинное обучение позволило выиграть примерно две секунды, или 3,4 % среднего отклонения прогноза. А в новой модели — еще почти секунду, суммарно уже 4,5 %. Но по этим числам сложно понять, что ETA улучшилось существенно. Чтобы почувствовать пользу от машинного обучения, стоит обратить внимание на последний столбец. Промахов с прогнозом более чем на 5 минут стало на 19,2 %, а в новой модели — даже на 23,2 % меньше! Кстати, такие ошибки случаются лишь в 3 и 2,8 % случаев в моделях с использованием машинного обучения.
Мы уточняли ЕТА в пине в основном для того, чтобы предоставить пользователям достоверный прогноз. Но, разумеется, при любом применении машинного обучения в бизнесе обязательно оценивать экономический эффект. И понимать, сопоставим ли он с затратами на построение и внедрение моделей. После А/В-теста в онлайне выяснилось, что мы, применив машинное обучение, получили статистически значимый рост конверсии из заказа в совершённую поездку (ведь заказ может быть и отменен) и рост конверсии из пользовательской сессии в заказ.
В обоих случаях речь идет об эффекте порядка 0,1 процентного пункта. Это, кстати, не противоречит статистической значимости: на наших объемах данных даже такое различие достоверно обнаруживается за 2–4 недели. И со значимостью для бизнеса на самом деле все тоже неплохо: оказалось, что затраты на уточнение ЕТА отбиваются приростом конверсии буквально за несколько месяцев.
В итоге мы получили полезный и показательный кейс. Уточнение ЕТА в пине стало поучительной историей об аккуратном выборе целевой переменной. Со стороны продукта это очень мотивирующий пример: мы улучшили приложение и увидели, что пользователи это оценили. Надеемся, уточненное ЕТА поможет нашим пассажирам чаще успевать на встречи, поезда и самолеты.
P.S. Если вам интересны и другие технологии Яндекс.Такси, то рекомендуем пост о динамическом ценообразовании, который совсем недавно опубликовал мой коллега.
Под катом поговорим о том, как методы машинного обучения помогают Яндекс.Такси более качественно прогнозировать ETA (Estimated Time of Arrival — ожидаемое время прибытия).
Для начала напомним, что пользователь видит в приложении перед заказом:
На карте синим отмечены оптимальные точки для посадки в такси. Красный пин — точка, к которой пользователь вызывает такси. В пине отображается, через какое время прибудет машина. В идеальном мире. Но в реальном мире другие люди неподалеку тоже вызывают себе машину через приложение Яндекс.Такси. И мы не знаем, какой автомобиль к кому поедет, ведь они распределяются только после заказа. Если машина уже назначена, для прогноза мы воспользуемся роутингом Яндекс.Карт и временем при движении по оптимальному пути. Это время (возможно, с небольшим запасом) мы и покажем пользователю сразу после заказа. Остается вопрос: а как же спрогнозировать ETA до заказа?
И здесь появляется машинное обучение. Составим выборку с объектами и правильными ответами и обучим алгоритм угадывать ответ по признакам объекта. В нашем случае объекты — это пользовательские сессии, ответы — это время, через которое фактически приехала машина. Признаками объекта могут быть числовые параметры, известные до заказа: количество водителей и пользователей приложения рядом с пином, расстояние до ближайших автомобилей сервиса и другие потенциально полезные величины.
Почему это важно
В идеальном мире люди все делают заранее и всегда безошибочно планируют свое время. Но мы живем в реальном мире. Если человек опаздывает на работу или, хуже того, в аэропорт, ему важно понимать, успеет ли он вовремя выехать и добраться до места назначения.
Решая, что заказать, будущий пассажир руководствуется в том числе временем ожидания. Оно может сильно отличаться и в разных приложениях для вызова такси, и в разных тарифах одного приложения. Чтобы пользователь не пожалел о выборе, очень важно показывать точное ЕТА.
Кажется, все просто. Придумать побольше признаков, обучить модель, например CatBoost, спрогнозировать время до прибытия машины — и можно закончить на этом. Но опыт показывает, что лучше не спешить и хорошенько подумать, а потом делать.
Сначала мы не сомневались, что нужно прогнозировать то время, через которое к пользователю фактически приедет водитель. Да, до заказа мы не знаем наверняка, какая именно машина будет назначена. Но мы можем предсказать ETA, используя данные не о конкретном водителе, а о водителях поблизости от заказа. Разумеется, прогноз должен быть достаточно честным, чтобы пользователь мог планировать время.
Но что значит «честным»? Ведь любой алгоритм прогнозирования плох или хорош только статистически. Встречаются и удачные, и откровенно плохие результаты, но нужно «в среднем» не сильно отклоняться от правильных ответов. Здесь надо понимать, что «в среднем» бывает разное. Например, среднее — это как минимум три понятия из статистики: матожидание, медиана и мода. Картинка из великолепной книги Дарелла Хаффа «Как лгать при помощи статистики» прекрасно показывает различие:
Мы хотим, чтобы модель в среднем ошибалась мало. В зависимости от значения «в среднем» возникает два варианта оценки качества прогнозов. Первый вариант — показывать пользователю математическое ожидание времени до приезда такси. В итоге обучится модель, минимизирующая средний квадрат ошибки прогноза (Mean Squared Error, MSE):

Здесь
— правильные ответы, — прогнозы модели.Другой вариант — не ошибаться с прогнозом ETA преимущественно в одну сторону, в большую или в меньшую. В этом случае мы покажем пользователю медиану распределения времени до приезда такси. В итоге обучится модель, оптимизирующая средний модуль ошибки прогноза (Mean Absolute Error, MAE):

Но мы поняли, что немного забегаем вперед.
Переосмысление постановки задачи
После назначения мы знаем, какая именно машина едет к пользователю, а значит, можем оценить ее время в пути по Яндекс.Картам. Это время и показывается в пине после заказа. С одной стороны, теперь у нас больше информации и прогноз будет точнее, но, с другой стороны, это тоже оценка с погрешностью.
Вот в чем оказался подвох в задаче про ЕТА в пине. Пока водитель не назначен, надо прогнозировать именно то время, которое потом покажет роутинг Яндекс.Карт, а не фактическое время до подачи машины.
Казалось бы, что за чушь: вместо точного значения брать в качестве таргета другой прогноз? Но это имеет смысл, и вот почему. По пути к вам назначенная машина может задержаться. Водитель попал в опасную ситуацию на дороге, в пробку из-за ДТП или вышел купить воды. Такие задержки сложно предугадать. Они создают дополнительный шум в целевой переменной, из-за которого и без того непростая задача спрогнозировать ЕТА в пине становится еще сложнее.
Как избавиться от шума? Прогнозировать сглаженную целевую переменную — время, которое показывается уже после назначения машины на основе маршрута к пользователю.
В этом есть логика и с точки зрения бизнеса: время в дороге по оптимальному пути из ETA в любом случае не выкинешь, а вот дополнительные задержки можно уменьшать, работая с водителями.
Метрики качества, данные, модель и обучение
Мы выяснили, что для ЕТА в пине нужно прогнозировать не фактическое время, а время, которое будет получено после назначения машины по маршруту. Из двух метрик качества, MAE и MSE, мы выбрали MAE. Возможно, с точки зрения интуитивности прогноза более логично оценивать матожидание (MSE), а не медиану (MAE). Но у MAE есть приятная особенность: модель более устойчива к выбросам (outliers) среди обучающих примеров.
Признаки делятся на группы:
— построенные по текущему времени;
— гео (координаты, расстояние до центра города и значимых объектов на карте);
— пиновые (сколько и каких машин рядом, по-разному подсчитанная их плотность);
— статистика по зоне (как обычно ошибаемся, сколько предсказываем);
— данные о ближайших водителях (за какое время доезжают, насколько первый ближе второго и т.п.).
На этих признаках обучали, конечно же, CatBoost. Решающим доводом было то, что реализованный в CatBoost градиентный бустинг над сбалансированными деревьями уже давно зарекомендовал себя как очень мощный метод машинного обучения, а способ кодирования категориальных признаков в CatBoost регулярно оправдывает себя на наших задачах. Другая приятная особенность библиотеки — быстрое обучение на GPU.
Теперь пара слов о том, какие модели сравнивались. Исходное ЕТА (до уточнения машинным обучением) рассчитывалось на основе времени, за которое может приехать ближайшая к пользователю машина. Текущая модель (используется в приложении сейчас) — то, что получилось сделать с помощью машинного обучения и чему посвящена эта статья. Кроме того, в продакшн скоро выкатится новая модель. Она использует на порядок больше значимых для решения задачи признаков. В таблице ниже приводятся замеры качества этих моделей на исторических данных. К слову, у нас планов ещё много — приходите помогать.
Качество прогноза ETA на валидации*
| |
Mean Absolute Error |
Ошибка более 1 минуты |
Ошибка более 2 минут |
Ошибка более 5 минут |
| Исходное ETA |
82,082 |
29,95 |
18,12 |
3,7 |
| Текущая модель |
79,276 (–3,4) |
29,33 (–2,1) |
16,98 (–6,3) |
3 (–19,2) |
| Новая модель |
78,414 (–4,5) |
28,95 (–3,4) |
16,62 (–8,2) |
2,8 (–23,2) |
* В процентах (в скобках указано изменение по сравнению с исходным ETA).
Машинное обучение позволило выиграть примерно две секунды, или 3,4 % среднего отклонения прогноза. А в новой модели — еще почти секунду, суммарно уже 4,5 %. Но по этим числам сложно понять, что ETA улучшилось существенно. Чтобы почувствовать пользу от машинного обучения, стоит обратить внимание на последний столбец. Промахов с прогнозом более чем на 5 минут стало на 19,2 %, а в новой модели — даже на 23,2 % меньше! Кстати, такие ошибки случаются лишь в 3 и 2,8 % случаев в моделях с использованием машинного обучения.
Итоги
Мы уточняли ЕТА в пине в основном для того, чтобы предоставить пользователям достоверный прогноз. Но, разумеется, при любом применении машинного обучения в бизнесе обязательно оценивать экономический эффект. И понимать, сопоставим ли он с затратами на построение и внедрение моделей. После А/В-теста в онлайне выяснилось, что мы, применив машинное обучение, получили статистически значимый рост конверсии из заказа в совершённую поездку (ведь заказ может быть и отменен) и рост конверсии из пользовательской сессии в заказ.
В обоих случаях речь идет об эффекте порядка 0,1 процентного пункта. Это, кстати, не противоречит статистической значимости: на наших объемах данных даже такое различие достоверно обнаруживается за 2–4 недели. И со значимостью для бизнеса на самом деле все тоже неплохо: оказалось, что затраты на уточнение ЕТА отбиваются приростом конверсии буквально за несколько месяцев.
В итоге мы получили полезный и показательный кейс. Уточнение ЕТА в пине стало поучительной историей об аккуратном выборе целевой переменной. Со стороны продукта это очень мотивирующий пример: мы улучшили приложение и увидели, что пользователи это оценили. Надеемся, уточненное ЕТА поможет нашим пассажирам чаще успевать на встречи, поезда и самолеты.
P.S. Если вам интересны и другие технологии Яндекс.Такси, то рекомендуем пост о динамическом ценообразовании, который совсем недавно опубликовал мой коллега.
