ClickHouse users already know that its biggest advantage is its high-speed processing of analytical queries. But claims like this need to be confirmed with reliable performance testing. That's what we want to talk about today.
We started running tests in 2013, long before the product was available as open source. Back then, just like now, our main concern was data processing speed in Yandex.Metrica. We had been storing that data in ClickHouse since January of 2009. Part of the data had been written to a database starting in 2012, and part was converted from
OLAPServer and Metrage (data structures previously used by Yandex.Metrica). For testing, we took the first subset at random from data for 1 billion pageviews. Yandex.Metrica didn't have any queries at that point, so we came up with queries that interested us, using all the possible ways to filter, aggregate, and sort the data.
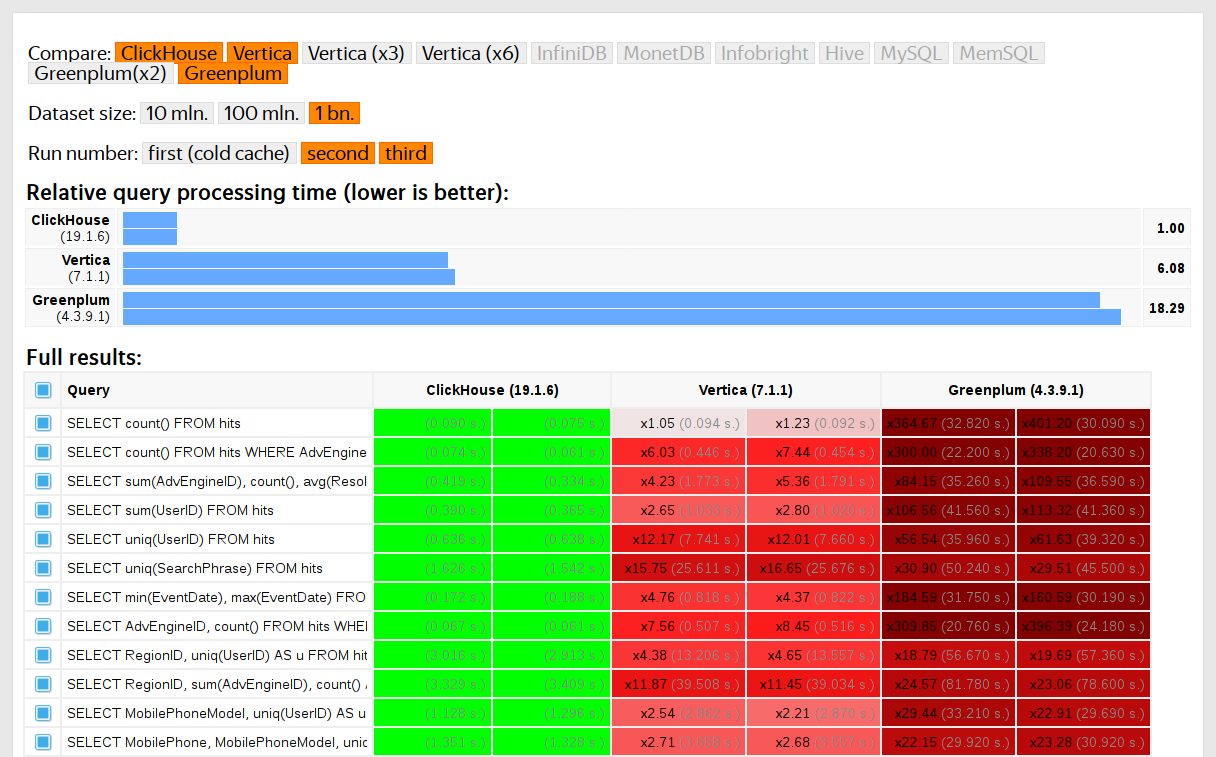
ClickHouse performance was compared with similar systems like Vertica and MonetDB. To avoid bias, testing was performed by an employee who hadn't participated in ClickHouse development, and special cases in the code were not optimized until all the results were obtained. We used the same approach to get a data set for functional testing.
After ClickHouse was released as open source in 2016, people began questioning these tests.