The new issue of Data Science Digest is here! Hop to learn about the latest news, articles, tutorials, research papers, and event materials on DataScience, AI, ML, and BigData. All sections are prioritized for your convenience. Enjoy!
The new issue of Data Science Digest is here! Hop to learn about the latest news, articles, tutorials, research papers, and event materials on DataScience, AI, ML, and BigData. All sections are prioritized for your convenience. Enjoy!

As we all are aware of the fact that the digital market is heavily leaning towards a reliable UX-driven process, app development has become quite complex, especially for targeting the industry for mobile platforms.
For every organization, creating a product that is beneficial for their customer needs always comes up with a plethora of challenges.
From the technical point of time, there are various challenges that every business faces, including selecting the right platform for the app, the right technology stack or framework, and creating an app that fulfills the needs and expectations of customers.
Similarly, there are more challenges that every business faces and needs to cope with while creating its dream product.
So, what to do??
Well, what if I say that the answer to all your queries and questions is Flutter app development with Artificial Intelligence (AI) integration……
Surprised? Wondering how?
Well, AI in Flutter app development is one of the best advancements in the software market. The concept of AI was first introduced during the 20th century with loads of innovations and advancements that we are still integrating into our mobile app development.
But, what are Artificial Intelligence and Flutter app development?

Hi All,
I’m pleased to invite you all to enroll in the Lviv Data Science Summer School, to delve into advanced methods and tools of Data Science and Machine Learning, including such domains as CV, NLP, Healthcare, Social Network Analysis, and Urban Data Science. The courses are practice-oriented and are geared towards undergraduates, Ph.D. students, and young professionals (intermediate level). The studies begin July 19–30 and will be hosted online. Make sure to apply — Spots are running fast!
If you’re more used to getting updates every day, follow us on social media:
Telegram
Twitter
LinkedIn
Facebook
Regards,
Dmitry Spodarets.
So we have already played with different neural networks. Cursed image generation using GANs, deep texts from GPT-2 — we have seen it all.
This time I wanted to create a neural entity that would act like a beauty blogger. This meant it would have to post pictures like Instagram influencers do and generate the same kind of narcissistic texts. \
Initially I planned to post the neural content on Instagram but using the Facebook Graph API which is needed to go beyond read-only was too painful for me. So I reverted to Telegram which is one of my favorite social products overall.
The name of the entity/channel (Aida Enelpi) is a bad neural-oriented pun mostly generated by the bot itself.


Hi All,
I have some good news for you…
Data Science Digest is back! We’ve been “offline” for a while, but no worries — You’ll receive regular digest updates with top news and resources on AI/ML/DS every Wednesday, starting today.
If you’re more used to getting updates every day, follow us on social media:
Telegram - https://t.me/DataScienceDigest
Twitter - https://twitter.com/Data_Digest
LinkedIn - https://www.linkedin.com/company/data-science-digest/
Facebook - https://www.facebook.com/DataScienceDigest/
And finally, your feedback is very much appreciated. Feel free to share any ideas with me and the team, and we’ll do our best to make Data Science Digest a better place for all.
Regards,
Dmitry Spodarets.
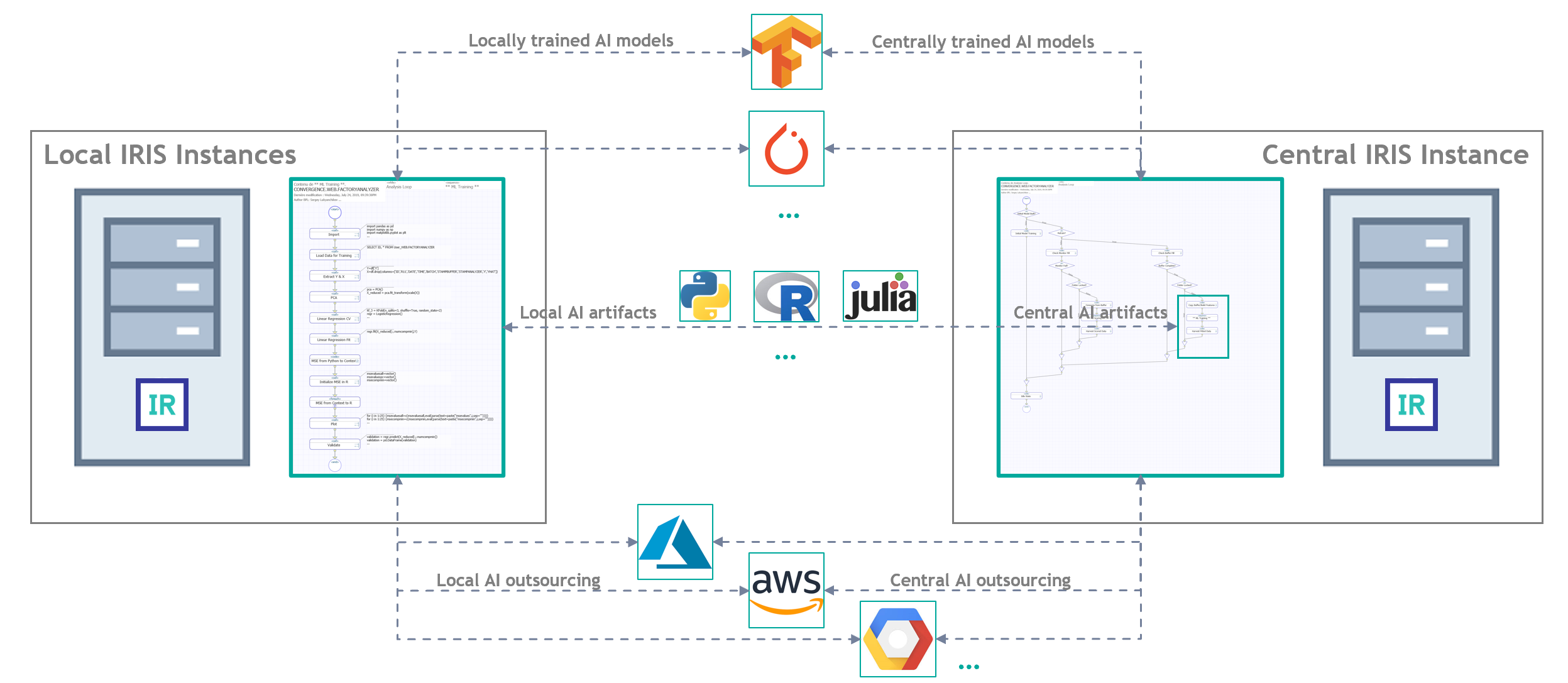
Author: Sergey Lukyanchikov, Sales Engineer at InterSystems
What is Distributed Artificial Intelligence (DAI)?
Attempts to find a “bullet-proof” definition have not produced result: it seems like the term is slightly “ahead of time”. Still, we can analyze semantically the term itself – deriving that distributed artificial intelligence is the same AI (see our effort to suggest an “applied” definition) though partitioned across several computers that are not clustered together (neither data-wise, nor via applications, not by providing access to particular computers in principle). I.e., ideally, distributed artificial intelligence should be arranged in such a way that none of the computers participating in that “distribution” have direct access to data nor applications of another computer: the only alternative becomes transmission of data samples and executable scripts via “transparent” messaging. Any deviations from that ideal should lead to an advent of “partially distributed artificial intelligence” – an example being distributed data with a central application server. Or its inverse. One way or the other, we obtain as a result a set of “federated” models (i.e., either models trained each on their own data sources, or each trained by their own algorithms, or “both at once”).
Distributed AI scenarios “for the masses”
We will not be discussing edge computations, confidential data operators, scattered mobile searches, or similar fascinating yet not the most consciously and wide-applied (not at this moment) scenarios. We will be much “closer to life” if, for instance, we consider the following scenario (its detailed demo can and should be watched here): a company runs a production-level AI/ML solution, the quality of its functioning is being systematically checked by an external data scientist (i.e., an expert that is not an employee of the company). For a number of reasons, the company cannot grant the data scientist access to the solution but it can send him a sample of records from a required table following a schedule or a particular event (for example, termination of a training session for one or several models by the solution). With that we assume, that the data scientist owns some version of the AI/ML mechanisms already integrated in the production-level solution that the company is running – and it is likely that they are being developed, improved, and adapted to concrete use cases of that concrete company, by the data scientist himself. Deployment of those mechanisms into the running solution, monitoring of their functioning, and other lifecycle aspects are being handled by a data engineer (the company employee).

There is a lot of commotion in text-to-speech now. There is a great variety of toolkits, a plethora of commercial APIs from GAFA companies (based both on new and older technologies). There are also a lot of Silicon Valley startups trying to ship products akin to "deep fakes" in speech.
But despite all this ruckus we have not yet seen open solutions that would fulfill all of these criteria:
16kHz and 8kHz out of the box;We decided to share our open non-commercial solution that fits all of these criteria with the community. Since we have published the whole pipeline we do not focus much on cherry picked examples and we encourage you to visit our project GitHub repo to test our TTS for yourself.
One of the most time-consuming steps while implementing a SIEM solution is writing and tuning "Playbook" – a set of reaction procedures SOC Team has to follow in case of alert triggering.
So during one of our projects we stoped for a moment and thought: "How can we optimize (ideally automate) the Playbook?"

There’s a lot of talk about machine learning nowadays. A big topic – but, for a lot of people, covered by this terrible layer of mystery. Like black magic – the chosen ones’ art, above the mere mortal for sure. One keeps hearing the words “numpy”, “pandas”, “scikit-learn” - and looking each up produces an equivalent of a three-tome work in documentation.
I’d like to shatter some of this mystery today. Let’s do some machine learning, find some patterns in our data – perhaps even make some predictions. With good old Python only – no 2-gigabyte library, and no arcane knowledge needed beforehand.
Interested? Come join us.
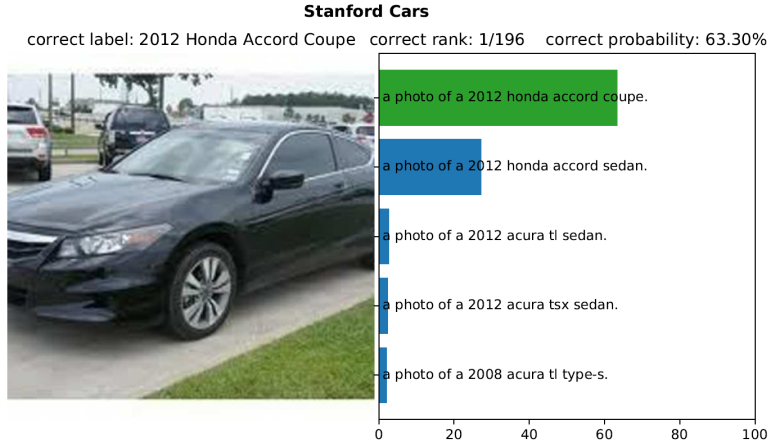
Neural networks (NN) and computer vision models in particular are known to perform well in specific tasks, but often fail to generalize to tasks they have not been trained on. A model that performs well on a food data may perform poorly on satellite images.
A new model from OpenAI named CLIP claims to close this gap by a large margin. The paper Open AI wrote presenting CLIP demonstrates how the model may be used on a various classification datasets in a zero-shot manner.
In this article, I will explain the key ideas of the model they proposed and show you the code to use it.
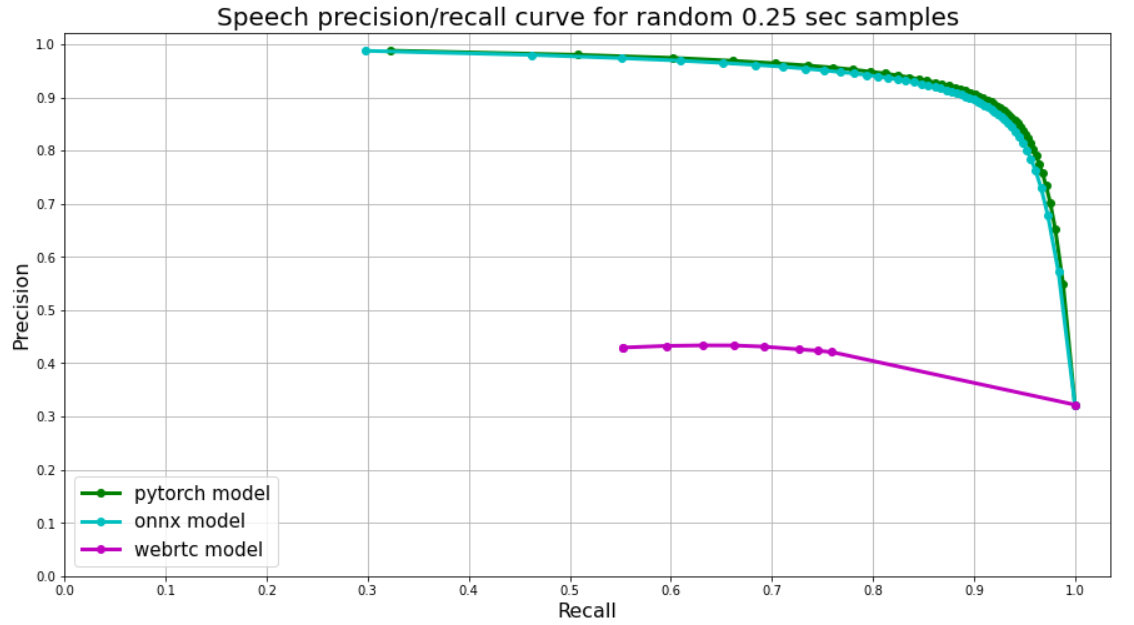
Currently, there are hardly any high quality / modern / free / public voice activity detectors except for WebRTC Voice Activity Detector (link). WebRTC though starts to show its age and it suffers from many false positives.
Also in some cases it is crucial to be able to anonymize large-scale spoken corpora (i.e. remove personal data). Typically personal data is considered to be private / sensitive if it contains (i) a name (ii) some private ID. Name recognition is a highly subjective matter and it depends on locale and business case, but Voice Activity and Number Detection are quite general tasks.
Key features:
Typical use cases:

Every time when the essential question arises, whether to upgrade the cards in the server room or not, I look through similar articles and watch such videos.
Channel with the aforementioned video is very underestimated, but the author does not deal with ML. In general, when analyzing comparisons of accelerators for ML, several things usually catch your eye:
The answer to the question "which card is better?" is not rocket science: Cards of the 20* series didn't get much popularity, while the 1080 Ti from Avito (Russian craigslist) still are very attractive (and, oddly enough, don't get cheaper, probably for this reason).
All this is fine and dandy and the standard benchmarks are unlikely to lie too much, but recently I learned about the existence of Multi-Instance-GPU technology for A100 video cards and native support for TF32 for Ampere devices and I got the idea to share my experience of the real testing cards on the Ampere architecture (3090 and A100). In this short note, I will try to answer the questions:

With ML projects still on the rise we are yet to see integrated solutions in almost every device around us. The need for processing power, memory and experimentation has led to machine learning and DL frameworks targeting desktop computers first. However once trained, a model may be executed in a more constrained environment on a smartphone or on an IoT device. A particularly interesting environment to run the model on is browser. Browser-based solutions may be used on a wide range of devices, desktop and mobile, online and offline. The topic of this post is how to prepare a model for the in-browser usage.
This post presents an end-to-end implementations of a model creation in Python and Node.js. The end goal is to create a model and to use it in a browser. I'll use TensorFlow and TensorFlow.js as main frameworks. One could train a model in Python and convert it to JS. Alternative is to train a model directly in javascript, hence omitting the conversion step.
I have more experience in Python and use it in my everyday work. I occasionally use javascript, but have very little experience in the contemporary front-end development. My hope from this post that python developers with little JS experience could use it to kick start their JS usage.

We are proud to announce that we have built from ground up and released our high-quality (i.e. on par with premium Google models) speech-to-text Models for the following languages:
You can find all of our models in our repository together with examples, quality and performance benchmarks. Also we invested some time into making our models as accessible as possible — you can try our examples as well as PyTorch, ONNX, TensorFlow checkpoints. You can also load our model via TorchHub.
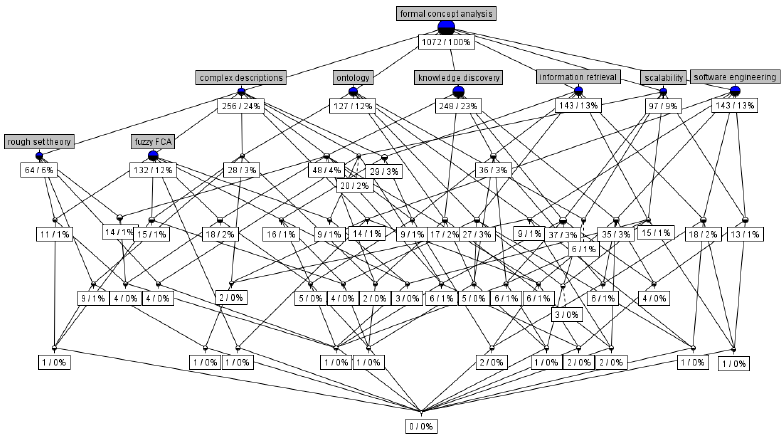
This is a fourth article in the series of works (see also first one, second one, and third one) describing Machine Learning system based on Lattice Theory named 'VKF-system'. The program uses Markov chain algorithms to generate causes of the target property through computing random subset of similarities between some subsets of training objects. This article describes bitset representations of objects to compute these similarities as bit-wise multiplications of corresponding encodings. Objects with discrete attributes require some technique from Formal Concept Analysis. The case of objects with continuous attributes asks for logistic regression, entropy-based separation of their ranges into subintervals, and a presentation corresponding to the convex envelope for subintervals those similarity is computed.

This is a third article in the series of works (see also first one and second one) describing Machine Learning system based on Lattice Theory named 'VKF-system'. It uses structural (lattice theoretic) approach to representing training objects and their fragments considered to be causes of the target property. The system computes these fragments as similarities between some subsets of training objects. There exists the algebraic theory for such representations, called Formal Concept Analysis (FCA). However the system uses randomized algorithms to remove drawbacks of the unrestricted approach. The details follow…