A native macOS load tester app — and backpressure made it honest

Why I built Requester, a real-time HTTP load testing app for macOS, and what Swift structured concurrency taught me about telling the truth under load.
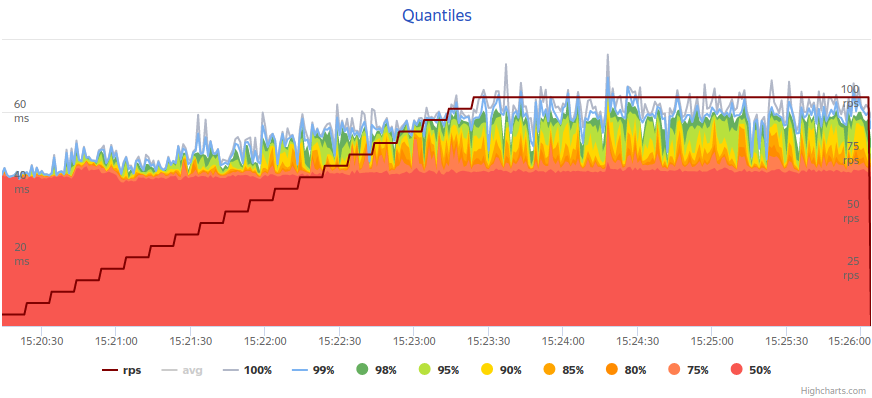
I wanted to hammer an HTTP endpoint and see what happened. Not read a summary report three minutes later — watch it, live, the way you watch a profiler.
The existing options are great but they all live in the terminal: wrk, hey, k6. I love them, but I kept wishing for a native window with a chart that moved. So I built one for macOS, in Swift and SwiftUI, and called it Requester.
This post is less “here are the features” and more “here are the three things I made building it.” The most interesting one: making the tool honest about backpressure turned out to be a design decision, not an accident.