На сегодняшний день существует большое количество различных систем управления базами данных - СУБД, от коммерческих до открытых, от реляционных до новомодных NoSQL и аналогичных.
Одним из лидеров направления СУБД является PostgreSQL и ее различные ответвления, о некоторых из которых мы рассмотрим подробнее.
В этой статье мы начнем говорить о СУБД PostgreSQL, рассмотрим отличия редакций и некоторые особенности архитектуры, а также процесс установки. Но начнем мы с небольшого ликбеза для того, чтобы читатели плохо знакомые с терминологией баз данных могли быстро войти в курс дела.
Итак, схемой мы будем называть логическое объединение таблиц в базе данных, а сама БД это физическое объединение таблиц. Индекс - отношение, которое содержит данные, полученные из таблицы или материализованного представления. Его внутренняя структура поддерживает быстрое извлечение и доступ к исходным данным.
Еще один важный термин, это первичный ключ - частный случай ограничения уникальности, определенной для таблицы или другого отношения, которое также гарантирует, что все атрибуты в первичном ключе не имеют нулевых значений. Как следует из названия, для каждой таблицы может быть только один первичный ключ, хотя возможно иметь несколько уникальных ограничений, которые также не имеют атрибутов, поддерживающих значение null.
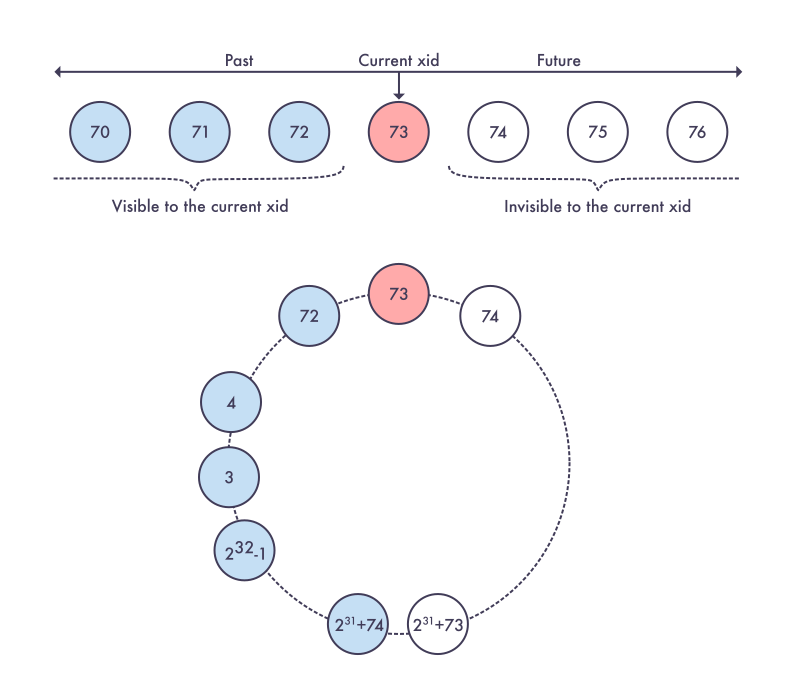
Ну и наконец, наверное, самый распространенный термин - транзакция это комбинация команд, которые должны действовать как единая атомарная команда. То есть, все они завершаются успешно или завершаются неудачно как единое целое, и их эффекты не видны другим сеансам до завершения транзакции, и, возможно, даже позже, в зависимости от уровня изоляции. Соответственно, если выполнение хотя бы одной команды внутри транзакции завершилось ошибкой - вся транзакция завершится ошибкой.