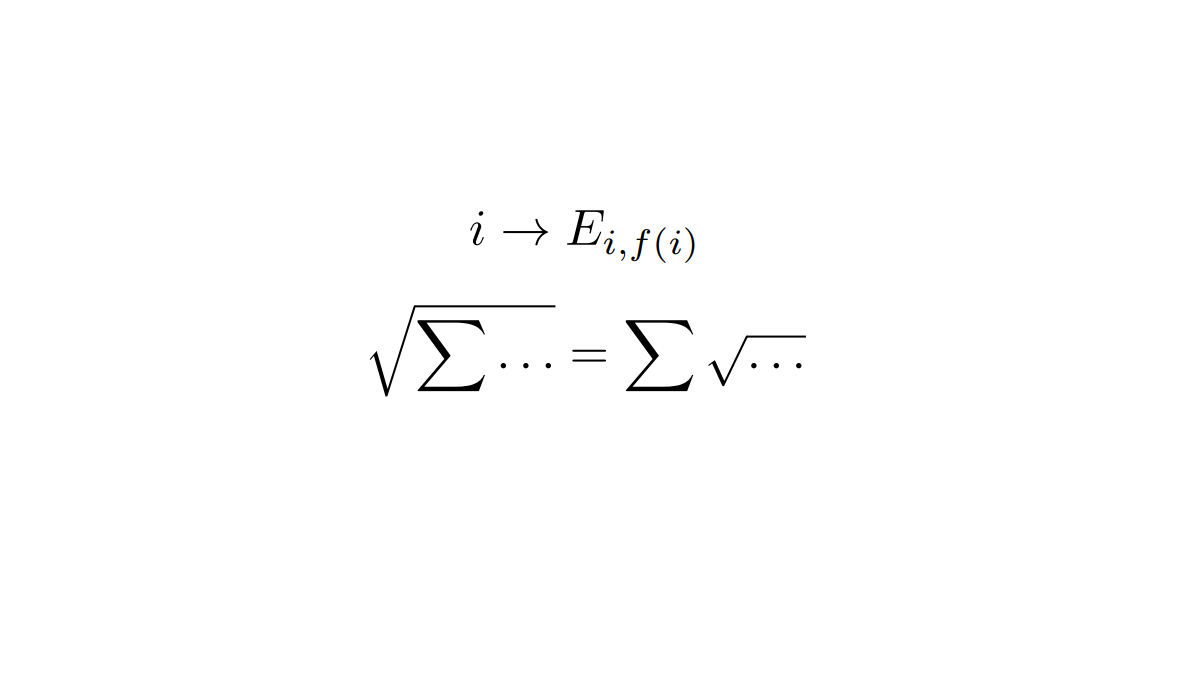Many online merchants face a common challenge with multiple product variations, leading to duplicate content issues. When similar products have slightly different URLs like "?=sortby" or "?p=2", search engines may view them as duplicates, impacting your website's credibility and search rankings. To tackle this:
In this article, I will introduce NoSQL concepts and show how they are related to Elasticsearch, and we will consider this search engine as a NoSQL document store.
Toloka is a crowdsourcing platform and microtasking project launched by Yandex to quickly markup large amounts of data. But how can such a simple concept play a crucial role in improving the work of neural networks?
The published material is in the Appendix of my book [1]
Modern civilization finds itself at a crossroads in which to choose the meaning of life. Because of the development of technology, the majority of the world's population may be "superfluous" - not in demand in the production of values. There is another option, where each person is a supreme value, an absolute individual and can be indispensably useful in the technology of the collective mind.
In the eighties of the last century, the task of creating a scientific field of "collective intelligence" was set. Collective intelligence is defined as the ability of the collective to find solutions to problems more effectively than each participant individually. The right collective mind must be...
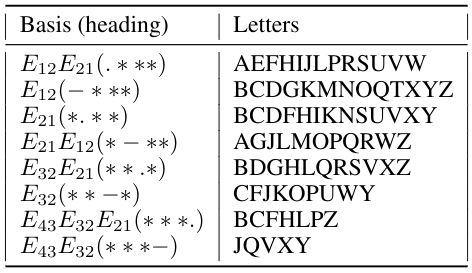
In [1,2,3] texts (sign sequences with repetitions) were transformed (coordinated) into algebraic systems using matrix units as word images. Coordinatization is a necessary condition of algebraization of any subject area. Function (arrow) (7) in [1]) is a matrix coordinatization of text. One can perform algebraic operations with words and fragments of matrix texts as with integers, but taking into account the noncommutativity of multiplication of words as matrices. Structurization of texts is reduced to the calculation of ideals and categories of texts in matrix form.
The mathematical model of signed sequences with repetitions (texts) is a multiset. The multiset was defined by D. Knuth in 1969 and later studied in detail by A. B. Petrovsky [1]. The universal property of a multiset is the existence of identical elements. The limiting case of a multiset with unit multiplicities of elements is a set. A set with unit multiplicities corresponding to a multiset is called its generating set or domain. A set with zero multiplicity is an empty set.
The previous work from ref [1] describes the method of transforming a sign sequence into algebra through an example of a linguistic text. Two other examples of algebraic structuring of texts of a different nature are given to illustrate the method.
Algebra and language (writing) are two different learning tools. When they are combined, we can expect new methods of machine understanding to emerge. To determine the meaning (to understand) is to calculate how the part relates to the whole. Modern search algorithms already perform the task of meaning recognition, and Google’s tensor processors perform matrix multiplications (convolutions) necessary in an algebraic approach. At the same time, semantic analysis mainly uses statistical methods. Using statistics in algebra, for instance, when looking for signs of numbers divisibility, would simply be strange. Algebraic apparatus is also useful for interpreting the calculations results when recognizing the meaning of a text.
For me, these two models are quite similar, but in fact they don’t have obvious characteristics to measure this similarity. These models have different numbers of vertices, edges and polygons. They are of different sizes, rotated differently and both have the same transforms (Location = [0,0,0], Rotation in radians = [0,0,0], Scale = [1,1,1]). So how to determine their similarity?
To say SEO has “changed a lot” would be the understatement of the decade. We’ll often see multiple updates per year from Google, like the BERT update in October aimed at helping the search engine better interpret natural language searches. Or the site diversity update in June, which focused on reducing duplicate organic listings on SERPs for the same site.
At a certain point, any website owner wonders what's better: SEO or PPC? Which promotion strategy will be the most rational to use in this particular situation? Or maybe it's best to combine both?
Before you decide between SEO and PPC, you need to consider the differences between them…
Let's say, your website offers content, products, or services for people from different regions or countries who speak different languages. Search engines will probably count this as duplicate content, leading to low rankings.
The PVS-Studio team has been keeping the blog about the checks of open-source projects by the same-name static code analyzer for many years. To date, more than 300 projects have been checked, the base of errors contains more than 12000 cases. Initially the analyzer was implemented for checking C and C++ code, support of C# was added later. Therefore, from all checked projects the majority (> 80%) accounts for C and C++. Quite recently Java was added to the list of supported languages, which means that there is now a whole new open world for PVS-Studio, so it's time to complement the base with errors from Java projects.
The Java world is vast and varied, so one doesn't even know where to look first when choosing a project to test the new analyzer. Ultimately, the choice fell on the full-text search and analytical engine Elasticsearch. It is quite a successful project, and it's even especially pleasant to find errors in significant projects. So, what defects did PVS-Studio for Java manage to detect? Further talk will be right about the results of the check.
Some time ago among security researchers, it was very “fashionable” to find improperly configured AWS cloud storages with various kinds of confidential information. At that time, I even published a small note about how Amazon S3 open cloud storage is discovered.
However, time passes and the focus in research has shifted to the search for unsecured and exposed public domain databases. More than half of the known cases of large data leaks over the past year are leaks from open databases.
Today we will try to figure out how such databases are discovered by security researchers...