Comments 62
Если останется один только git, что нас ждёт?
Зависит от подхода. Я `git pull` вообще никогда не использую. Сначала `git fetch`, потом `git rebase`, будет похоже на то что вы описали.
(какого черта у Хабра опять сломалось форматирование кода?)
Мимо.
Каким образом ребейс вам конфликты решит?
Никаким, но описанному поведению
если изменения касались одного и того же участка кода в файле все равно мерждила осталвяя оба куска кода и давая пользователю разрулить конфликт.
он вполне соответствует.
А что, SVN магическим образом умеет решать конфликты? То что можно помержить автоматически, то рибейз и помержит. А если есть конфликтующие изменения, то их надо разрешать руками, что в гите, что в SVN, что при git rebase что при git pull или git merge
А в Git как конфликты разруливать?
Ну точно так же. Он совершенно так же показывает конфликт в файле, даже синтаксис почти тот самый. Только вместо filename в первой строчке он указывает на ревизию с другой стороны. Например: https://wincent.com/wiki/Understanding_Git_conflict_markers
Единственное, что не надо ходить по ошибкам компиляции (хотя можно, если хочется), достаточно сделать git diff, он покажет неразрешенные конфликты.
В момент резолва конфликта гит делает примерно то же самое. Только компилировать то зачем? Если уж средствами гита или какого GitExtensions лень разруливать, то любая нормальная IDE имеет либо свои средства для решения конфликтов, либо нормальную интеграцию с Meld, kdiff3, etc, которые покажут разницу между вашим кодом, кодом прилетевшим из репозитория и исходной точкой, от которой ответвились оба изменения. Подберите себе удобный набор инструментов, настройте их один раз тщательно (вплоть до интеграции в трекер и CI/CD) и будет вам счастье
Да вроде git pull автоматически все мержит если нет конфликтов. А если есть - то "все равно мержит и дает пользователю разрулить конфликт", так что я не очень понял о чем вообще речь
Никаких проблем нет, если идти по гит флоу, делая изменения в отдельной ветке (фича-бранче), подмердживая в нее изменения от основной перед мерджем обратно. Конфликты решаются на этом этапе.
Попробуйте fossil – лучшее из двух миров.
Поддерживаю. Сам активно пользовался. Единственная проблема - предполагает что все всем доверяют и все везде могут мержить. Ну и интеграций не хватает.
Вообще-то прикольно: сначала создали распределённую систему контроля версий, а потом залили весь код на один сервер «GitHub”. …
Единственная проблема - предполагает что все всем доверяют и все везде могут мержить.
Ну, fossil создавался для небольших коллективах, где каждый каждому доверяет. А такие небольшие коллективы встречаются намного чаще.
Но кстати, если немножко изменить начин применения, то вполне можно использовать fossil и в условиях неполного доверия – вот моя коротенькая заметка как это делается (en): Bazaar model with Fossil SCM.
Можно `git stash`, потом `git pull`, потом `git stash pop`.
Большинство клиентов не умеют в такое сами по себе. А делать вагон операций каждый раз - такое себе.
Вроде свежий гит умеет в такое автоматически, но там варнинги про то что всё может пойти не так, поэтому как-то ссыкотно это включать.
https://git-fork.com делает хорошо по умолчанию. А чтоб не было страшно, надо разобраться в основных командах. Когда делать fetch, когда pull, когда rebase и будет праздник предсказуемость.
Обычно в такой ситуации я беру чистую копию репозитория и какой-нибудь сравнялкой(Beyond Compare или Araxis Merge) перекидываю свои изменения в чистый репозиторий и уже оттуда делаю коммит и пуш. Но должен же быть способ проще? На всякий случай уточню что использую TortoiseGit.
Каждая система контроля версии должна делать это сама. По сути надо скачать обновления и слить их с своими изменениями. Если есть конфликты – исправить и сделать опять push.
Ну сделал и сделал. И что? Есть же две стратегии для git pull: merge и rebase. Их можно прям в конфиг прописать. Обе выполнятся абсолютно автоматом, если ты и твой коллега не мордуете один и тот же код. Если мордуете - забираешь правки коллеги и на них применяешь свои (потому что ты знаешь что ты делал и как это быстро применить к коду, а что делал коллега - ещё разбираться надо). И в принципе для pull можно и всегда rebase делать, потому что твои коммиты должны линейно лечь над тем, что уже вкоммитано в репозиторий.
git config --global pull.rebase trueМерж-конфликты начинаются когда разрабы делают одно и то же и, почему-то, все в одном бранче, а регулярно забираться из репо - религия не позволяет. Meld позволяет разруливать конфликты вот прям вообще легко
https://git-scm.com/book/en/v2 главы Git Basics, git branching, distributed git (поверхостно), git tools (чтобы знать, где искать нужную ручку в будущем).
А мне SVN нравится
И какого оно работать при недоступности сервера ?
Печально (по мне, mercurial заметно приятнее git), но закономерно, git – это стандарт де-факто, глупо держать зоопарк систем хранения версий.
К сожалению это всё привело к тому, что гит стал промышленным стандартом. А из-за того что у всех разные потребности - оброс огромным количеством костылей.
Он не предназначен для хранения бинарей, но есть lfs, который работает через костыли в виде хуков.
Гит как бы дентрализованный, локов как бы нету, но они есть, но если они есть то система уже не совсем децентрализованная.
Как бы есть локальные бранчи и локальные коммиты, но если хочешь нормальные локи - использовать их нельзя.
В попытках удовлетворить всех - гит стал франкенштейном. И швец, и жнец, и на дуде игрец.
По факту мы имеем в каждй конторе своё подмножество функций, которые используются в рабочем флоу. Даже если челвоек работал с гитом в одной компании, он может почти полностью потеряться в другой. Банально в одной rebase flow, в другой - merge flow. Приходится переучиваться, и это хуже чем переучиться на другой софт, т.к. софт вроде тот же вполне привычный, а операции надо делать другие.
В компании где работаю в итоге пришли к тому, что есть свой гит клиент, со своим флоу и со своими дополнительными костылями, которые добавляют нам то, чего нету в базовом гите, например тот же вышеупомянутый stash push, pull, stash pop
О боже, у вас изобрели git pull --autostash или алиасы? Может чтобы не держать "свой гит клиент" нужно разобраться с нормальным нормально? Там переучиваться, собственно при переходе между компаниями негде, ты или разобрался, или нет
Большинство разработчиков умеют только тыкнуть кнопку в ide без понимания сути происходящего. А уж консоль им покажи, так сожгут на костре.
А потом у них "Гиту нужно переучиваться".
Тыкать кнопки без понимания сути невозможно.
Что касается консоли, мне всегда было интересно: это мир неправильный, или я неправильный? Люди массово используют визуальные инструменты вместо текстовых там, где им не место (например, WYSIWYG при создании UI вместо текстового markup language), а там, где сам бог велел рисовать визуальные деревья или отображать красивый markdown — там они используют консоль.
В IDE в которых просто торчит кнопка Sync (под капотом делает git pull ; git push) - легко. А у JB зачем-то и текст прошлого коммита сохраняется - вообще легко новичкам навертеть чего-то, в чём они сами не разберутся за адекватное время
Тыкать кнопки без понимания сути невозможно.
Мы же про АйТи говорим, верно? Это вполне себе стандартный подход, по факту-то.
Вроде, стандартный пост про собеседования имеет пару веток про "стоит знать хотя бы базовые и простейшие алгоритмы, или и так сойдет?", что неплохо обосновывает популярность подхода "я знаю в своей узкой области, а дальше не смотрю, пока серьезно не попросят".
Часто вам требуется смотреть на дерево? Мне вот нет. Зато часто я вот что проверяю: была ли смержена ветка, какими комитами различаются 2 ветки (релизная и мастер). В каком коммите впервые была упомянута какая-то константа. Или выбрать удобный коммит для ветвления, что бы потом ветку можно было слить в 2 других, ничего попутно лишнего не затащив. Для этого есть UI?
git commit и git push у меня не самые популярные команды.
Часто вам требуется смотреть на дерево? … В каком коммите впервые была упомянута какая-то константа.
По идее, деревянное представление могло бы быть основой как раз для подобных задач.
Странно, я как раз дерево для этого всего и использую (ну кроме поиска переменной). Одного взгляда достаточно, чтобы понять, что куда смержено и какой комит взять для ветвления.
У вас похоже 3 ветки и 5 коммитов. Ибо обычно это выглядит так, если над проектом сотня людей трудится. Как раз потому, что многие умеют только тыкать кнопки.
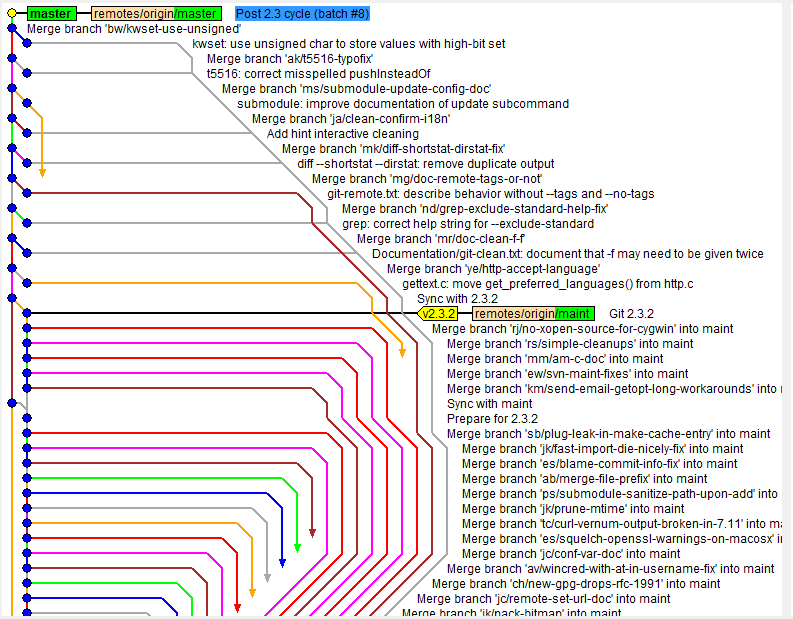
Нет, комитов у нас 2000, но какая разница, сколько комитов в проекте, я же не хожу на 5 лет назад по истории каждый день? А если в проекте такой flow, что дерево не помогает, а только запутывает, то может, не в дереве дело? Граф на скриншоте, мне кажется, был бы информативнее, если бы разработчики делали rebase перед merge, и это не обязательно делать в консоли. Тут разница в "уметь применять инструмент/не уметь" и "иметь подходящий проекту flow/не иметь", а не "консоль/кнопки". И вопросы даже не к нажимальщикам кнопок, а к поставленному процессу.
Это если что граф исходников самого гита))
Не, ну зачем искать глазами на дереве подходящий коммит, если есть merge-base?
Этот граф как-то неудобно показан (да и не актуальный давно?), мне больше нравится как GitExtensions показывает (а он показывает не стрелочки пропавшие в неизвестность, а прям откуда-докуда бранч живёт)

И у них свой особенный flow основанный на мерж реквестах от множества несвязанных разработчиков, которые пилят несвязанные фичи и всё это без какого-либо конкретного плана по выкату фич, как у бизнесочков и прочих проектов. У бизнесочков и в командах всё сильно проще и линейнее выглядит.
merge-base не всегда указывает на актуальный бранч в который можно замержиться. Если от него несколько бранчей стартовало - без нормального именования бранчей куда возвращать правки становится сильно непонятно и всякие гитлабы/гитхабы предлагают мержить прямо в мастер - потому что родителя сложно корректно отслеживать. Но руками, если именовать бранчи нормально, можно отследить (например если от мастера бранчуются релизы, от релизов большие фичи (feature/something), от больших фич разрабы (dev/each-small-part) - тогда ты всегда знаешь кто родитель для твоего коммита.
Мне даже интересно стало, по какому принципу вы выбираете откуда ветвиться. Есть master, есть релизные ветки (кому нужны), есть ветка в которой команда ведёт текущую разработку (большая фича, которая по окончании спринта будет влита выше). Всё, больше не от чего ветвиться, ты либо пилишь от последнего актуального релиза (но чаще мастера), либо оговорено какую ветку дополняешь. Что там искать то?
Чтобы найти в каком коммите упомянута какая-то константа - ну если это константа (она в одном месте проинициализирована), то коммит где она проинициализирована и будет первым - file history в чистом виде, на худой конец blame. Если это не константа, а магические циферки - git log -S"magicmushrooms"
Дерево тут при чём вообще? Уж лучше в каком GitExtensions прыгать хоткеем на Parent Commit пока не упрёшься в нужный
Очевидно там создается по ветке на каждый багфикс или минорную фичу. Так делают в больших командах, это упрощает анализ проблем и откат если что-то пошло не так по сравнению с вариантом где несвязанные правки разных людей в одной ветке перемешаны
Вообще не очевидно) Во первых всё ещё не нужно с собаками искать "от кого отбранчеваться", потому что каждый багфикс или минорная фича берутся от основной актуальной ветки, а не от несвязанной фичи васяна забытой в каком-то десятом бранче пятой ветки позапрошлого релиза.
Во вторых делаешь багфикс, минорную фичу или свою часть большой фичи в своей ветке (например dev/jira-1234-title), подмерживаешь её в feature/next-cool-deployment (иногда squash, если там несколько коммитов связанных одним контекстом), для одиночных коммитов fast-forward, а старый уже не нужный бранч успешно удаляется. И, хоба, у тебя есть версия на тестовом энвайрменте готовая к поставке без ада из бранчей - они будут выглядеть максимум как несколько ёлочек сливающихся в итоге в мастер, а не как макаронный монстр на скрине выше. Всё откатывается выборочно на ура (потому что каждая самостоятельная единица - всё ещё самостоятельный коммит), всё тестируется (после того как прошёл CI и автотесты), нормально последовательно ревьюится (вру, на самом деле ревьюится ещё на этапе мерж-реквеста в ветку)
Заменять ветку на 1 коммит == терять историю изменений внутри ветки. Для каких-то тривиальных вещей это осмысленно, но для чего-то более-менее сложного это путь в никуда. Отсюда и обилие веток.
Вот "искать от кого отбранчеваться" при правильно налаженном процессе не надо, это да. Хотя я видел прецеденты где процесс мержа в главную ветку был поставлен криво и занимал недельки так две (пока все будет протестировано и одобрено), вот там веточки имели тенденцию перемешиваться, черрипикать коммиты и бранчеваться где не попадя.
Дерево тут при чём вообще?
Это же ведь не ко мне вопрос. Именно log -S я и имел ввиду.
Мне даже интересно стало, по какому принципу вы выбираете откуда ветвиться.
Когда нужно в релизную ветку докинуть какой-то фикс или фичу, которые по каким-то причинам туда не успели через мастер заехать, но очень нужны. В таком случае я делаю бранч от последнего общего предка мастера и релиза. Затем мержу одну ветку и в мастер и в релиз.
Если это делать черрипиком, тогда 2 одинаковых по содержимому коммита формально будут разными сущностями. И будут светиться в диффлоге.
Когда над одним репозиторием работает несколько десятков человек, половину из которых я даже не знаю, мне как-то нужно убедиться, что все задачи из релиза были смержены, что никакие фиксы не забыли в мастер закинуть. А бывает что задачу смержили, а в жире версию не проставили. Я не вижу никаких способов это сделать через дерево. Только дифлог трёхсторонний, регулярки.
--autostash работает только с rebase. А еще он не атомарен. Если что-то пойдет не так в процессе, вам придется ручками доставать ваши данные из стэша.
Требовать такого понимания от условного композитора в компании - идиотизм.
"ты или разобрался, или нет"
Это чушь. 99% пользователей гита в нём ничего не понимают и действуют по чек листу. Да и чтобы понимать гит надо книжку прочитать и через кучу кейсов самостоятельно пройти. Никто не будет в здравом уме при найме сотрудников требовать от них хорошего знания гита. Это просто отсеет огромную кучу крутых специалистов.
Есть очень простой вариант обходиться без stash - коммитать свои правки прежде чем начинать что-то делать. Хорошая, кстати, привычка.
Немного непонятно, что за крутые спецы не могут мерж-конфликт порешать.
Ну и то что вы 99% людей нанимаете не умеющих в СКВ... это ваш личный опыт, который плохо кореллирует с 99% пользователей гита
Когда-то давно вдоволь накувыркался CVS на фре, Subversion, Mercurial... и как-то не вижу проблем использовать Git для большинства задач разработчиков. Без страданий по тому, какой он "франкенштейн" и как при обилии обучалок его "тяжелее" освоить чем любой другой
99.9% людей, связанных с геймдевом и не умеющих в код (дизайнеры, артовики, звуковики и т.п) - они все работают строго по инструкции, где каждый шаг в сторону равносилен смерти.
Ещё более математически выверенная цифра - обожаю такое. И все они одновременно долбятся в один и тот же файл, а людей могущих один раз им нормально гит настроить и один раз нормально заонбордить в инструмент которым их якобы вынудили каждый день пользоваться - в компании нет. Может это не проблема гита и не про его сложность, а про то что кто-то на галеру просто дворников с улицы зовёт, выдаёт им вёсла и "просто гребите отсюда и до заката, вы всё должны сами уметь мы вас уже продали как сеньоров и учить не обязаны"?
если хочешь нормальные локи
Что такое «нормальные локи»? Это то, за что во времена Visual Source Safe били по морде по возвращении из отпуска, или я пропустил какие-то новые локи? Просьба извинить мою серость, я сторонник максимально простых процессов и визуальных инструментов (TortoiseGit).
Нормальные локи, это локи, которые для лока требуют, чтобы у тебя была актуальная версия файла.
Так а чем это поможет в ситуации "Вася вечером залочил половину репозитория и ушел домой, а на следующий день не пришел, потому что заболел"? Ну или просто, вот есть файл в репозитории, я делаю патч на одну функцию в этом файле, коллега - на другую. Почему мы не можем делать это одновременно?
А можно попросить поподробнее описать сценарий? Насколько я знаю, некоторые серверы (BitBucket, GitHub) имеют настройку "ветка должна быть после rebase", то есть смержить можно будет только если 100% коммитов из мастера присутствуют в ветке с новыми изменениями. И да, это уже реализации серверов, а не просто git клиент.
Я подозреваю, что Вы имеете ввиду что-то другое. А какой сценарий требуется?
Активно пользовался CVS, SVN, HG, GIT, Perforce. Для себя всегда выбирал HG, жаль, если помрет...
Они ещё в 2006 году, когда мигрировали с CVS, рассматривали Git и, емнип, основной претензией тогда было то, что Git плохо поддерживался в Windows. Поэтому выбирали между Mercurial, SVN и Bazaar.
Разработка Firefox полностью перейдёт с Mercurial на Git